Oracle observer что это
Обновлено: 02.07.2024
This document will guide you through configuring Oracle Data Guard Fast-Start Failover (FSFO) using a physical standby database. FSFO can provide substantial gains in high availability and disaster recovery preparedness for all environments, from inexpensive Cloud-based systems to global distributed data centers.
The information in this guide is based on practical experience gained from deploying FSFO in a global corporate production environment. The guide makes few assumptions about your existing environment and includes examples for creating a physical standby database and Data Guard Broker configuration. To get started, all you'll need is Oracle Database Enterprise Edition Release 10.2 or later, a database, and three hosts: two for the databases and a small host for the FSFO observer. The guide attempts to be operating system agnostic; however, some examples may contain platform specific elements such as path and file naming conventions.
DOWNLOAD
Major Components of an FSFO Environment
FSFO builds upon a number of other Oracle technologies and features such as Data Guard, Flashback Database, and Data Guard Broker.
Data Guard
The foundation of FSFO is Data Guard - a primary and at least one standby. The standby can be physical or logical and there can be multiple standbys, but only one of the standbys can be the failover target at any given time. The following paragraphs describe the supported availability modes.
Maximum Availability Mode (Oracle Database 10g Rel 2 and later)
In Maximum Availability mode, FSFO guarantees that no transaction that has received a commit acknowledgment will be lost during a failover. The price for this guarantee is increased commit latency ( log file sync waits). Maximum Availability mode uses synchronous redo transfer and FSFO imposes the additional requirement that the redo is recorded in the standby redo log (SRL) of the target standby (AFFIRM option of log_archive_dest_ n). Overall commit latency is increased by the round-trip network latency. With increased latency comes decreased throughput; however, in some cases the difference in throughput may be made up by increasing parallelism.
Although redo transfer is synchronous, Maximum Availability mode allows the primary to remain available if the standby database becomes unavailable for any reason (e.g. standby database, host, or network failure, etc.). If the primary is unable to contact the standby after a user specified period of time (NET_TIMEOUT option of log_archive_dest_ n), it drops out of synchronous transfer mode and begins operating as though it were in Maximum Performance mode. When the standby becomes available again, the primary and standby re-synchronize and resume synchronous redo transfer.
Maximum Performance Mode (Oracle Database 11g Rel 1 and later)
Oracle Database 11g FSFO adds support for Maximum Performance mode (async redo transfer), providing the flexibility to trade durability for performance. Commit latency is not affected by redo transfer, but committed transactions whose redo has not been received by the standby will be lost during failover. FSFO configurations in Maximum Performance mode may limit potential data loss by specifying the maximum allowable age of transactions that are lost during a failover. For example, if the limit specified is 30 seconds (the default), FSFO guarantees that all transactions that committed prior to 30 seconds ago are preserved during failover. The minimum allowable limit is 10 seconds.
Data Guard Broker
Broker is a Data Guard management utility that maintains state information about a primary and its standby databases. It automatically sets Data Guard related database initialization parameters on instance start and role transitions, starts apply services for standbys, and automates many of the administrative tasks associated with maintaining a Data Guard configuration. FSFO is a feature of Broker which records information about the failover target, how long to wait after a failure before triggering a failover, and other FSFO specific properties.
Flashback Database
Flashback Database is a continuous data protection (CDP) solution integrated with the Oracle Database. It provides a way to quickly restore a database to a previous point in time or SCN using on-disk data structures called flashback logs. Flashing back a database is much faster and more seamless (one simple DDL statement) than traditional point-in-time or SCN-based recovery. FSFO uses Flashback Database as part of the process of reinstating a failed primary as a standby.
Problems with automatic reinstatement are frequently due to misconfiguration, so let's look at this in a bit more detail.
Flashback Database records the before-image of changed blocks. To avoid the overhead of recording every change to every block, Flashback Database takes a "fuzzy" snapshot every 30 minutes and only records the before-image block upon its first change since the last snapshot. Subsequent changes to the same block during the same snapshot are not recorded.
Flashing back a database occurs in two stages:
- Restore - Flashback Database restores the datafiles to the closest snapshot prior to the specified SCN. This can be compared to performing an RMAN restore of the datafiles from a backup taken prior to the specified SCN, but is much faster.
- Media Recovery - Once the restore is complete, recovery proceeds as a typical media recovery, applying redo from archived and online redologs and rolling back uncommitted changes with undo. This means that in order for a flashback database operation to succeed,Flashback Database requires all archive redo logs generated between the snapshot time and restore SCN (typically the past 30 minutes of redo). Use the V$RECOVERY_PROGRESS view to monitor recovery status.
For FSFO environments, set db_flashback_retention_target = 60 or higher to provide sufficient Flashback Database history for automatic standby reinstatement. Metadata for the fuzzy snapshot is stored in the flashback log itself. If that metadata is pushed out, Oracle can no longer find a fuzzy snapshot so it will not be able to flash back. To avoid problems due to timing variations, values less than 60 minutes are not recommended and values of 30 or less virtually guarantee Flashback Database failure.
Flashback Database stores its logs in the Flash Recovery Area (FRA), so the FRA must be large enough to store at least 60 minutes of Flashback Database history. The total storage requirement is proportional to the number of distinct blocks changed during snapshots - e.g. 1,000,000 block changes on a small set of blocks generates less Flashback Database history than 1,000,000 changes on a larger set of blocks. A good method to determine Flashback Database storage requirements is to enable Flashback Database and observe the amount of storage it uses during several peak loads. There is little risk in enabling Flashback Database to determine its storage requirements - it can be disabled while the primary is open if necessary. However, re-enabling Flashback Database will require a bounce since the database must be mounted and not open.
FSFO observer
The observer is the third party in an otherwise typical primary/standby Data Guard configuration. It is actually a low-footprint OCI client built into the DGMGRL CLI (Data Guard Broker Command Line Interface) and, like any other client, may be run on a different hardware platform than the database servers. Its primary job is to perform a failover when conditions permit it to do so without violating the data durability constraints set by the DBA. Only the observer can initiate FSFO failover. It's secondary job is to automatically reinstate a failed primary as a standby if that feature is enabled (the default). The observer is the key element that separates Data Guard failover from its pre-FSFO role as the plan of last resort to its leading role in a robust high availability solution.
Note: the FSFO observer version must match the database version. Oracle Database 11g observers are incompatible with 10g databases and vice-versa.
Conditions for FSFO Failover
By default, the observer will initiate failover to the target standby if and only if ALL of the following are true:
- observer is running
- observer and the standby both lose contact with the primary
- Note: if the observer loses contact with the primary, but the standby does not, the observer can determine that the primary is still up via the standby.
User configurable failover conditions (11g and later)
Oracle Database 11g Rel 1 introduced user configurable failover conditions that can trigger the observer to initiate failover immediately.
Health conditions
Broker can be configured to initiate failover on any of the following conditions. Conditions shown in blue are enabled by default.
- Datafile Offline (due to IO errors)
- Corrupted Controlfile
- Corrupted Dictionary
- Inaccessible Logfile (due to IO errors)
- Stuck Archiver
Oracle errors (ORA-NNNNN)
You can also specify a list of ORA- errors that will initiate FSFO failover. The list is empty by default.
Application initiated
Applications can initiate FSFO failover directly using the DBMS_DG.INITIATE_FS_FAILOVER procedure with an optional message text that will be displayed in the observer log and the primary's alert log.
Walkthrough Overview
The walkthrough begins with a single database that will become the primary of a Data Guard configuration. For this build, we will use a single physical standby database. FSFO can also be used with logical standbys and an FSFO-enabled configuration may have multiple standbys with a mix of physical and logical, but only one standby can be the failover target at any given time.
- Configure Oracle Net (aka SQL*Net)
- Prepare the primary database
- Create a physical standby
- Enable Flashback Database
- Create a Broker configuration
- Configure the observer
- Enable and test FSFO
Conventions used
Names used in the examples:
Input commands are shown in shaded boxes in normal text. Expected output is shown in blue text.
Configure Oracle Net
Data Guard uses Oracle Net (SQL*Net) for communication between the primary and standby databases and the FSFO observer. Getting the Oracle Net configuration right is one of the key factors in a successful FSFO deployment. Improper Oracle Net configuration is a leading cause of reported FSFO issues.
Note: Data Guard requires dedicated server connections for proper operation. Do not use Shared Server (formerly MTS) for Data Guard.
Configure listeners
It's good practice to use separate listeners for application connections and Data Guard connections. This allows Data Guard to remain functional during maintenance periods when the application listeners are down. Be sure to include the Data Guard listener in the local_listeners database parameter.
Most of the network services used in a FSFO environment may use dynamic registration, but to enable Broker to restart instances during role transitions or during reinstatement after a failover, you must define a static service named db_unique_name_dgmgrl. db_domain . (Note: 11.1.0.7 adds the StaticConnectIdentifier Broker database property to allow you to specify a different service name.) If you will be using RMAN to create the standby database, it also needs a static service to restart the database being created. In order to maintain separation of Broker and non-Broker activity, a second static service is recommended.
Oracle observer что это
В общем, штука неплохая и, думаю, в 11g она уже достаточно вылизана. Плюс, в 11g разрешено уже использовать Maximum Performance (в 10g, насколько помню, необходим обязательно Maximum Availability и, соответственно, SYNC для передачи редопотока)
Нет веры "железному разуму" пока до такой степени. Да и раз в N лет сказать failover ручками никого не напряжет + спокойнее будет, учитывая, что на некоторых базах этот failover может полчаса длиться.
Виртуализация, вычислительные платформы, СХД, проектирование, проектная документация
Рекомендации от Oracle
1. Сначала удалим ранее созданную нами вручную конфигурацию Data Guard;
[oracle@rac-node01]$ srvctl stop instance -d TEST -n rac-node02
[oracle@rac-node01]$ ORACLE_SID=TEST1; export ORACLE_SID
[oracle@rac-node01SQL> shutdown immediate;
]$ scp /u01/app/oracle/product/11.2.0/dbhome_1/dbs/spfileTEST1.ora rac-node02:/u01/app/oracle/product/11.2.0/dbhome_1/dbs/spfileTEST2.ora
[oracle@rac-node01]$ srvctl start database -d TEST
[oracle@rac-node01]$ srvctl status database -d TEST
Instance TEST1 is running on node rac-node01
Instance TEST2 is running on node rac-node022. На всех хостах (rac-node01, rac-node02, rac02-scan) добавляем (где нет) в файл /u01/app/oracle/product/11.2.0/dbhome_1/network/admin/tnsnames.ora следующие строчки:
TEST_STANDBY =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = rac02-scan.test.local)(PORT = 1521))
(CONNECT_DATA =
(SERVICE_NAME = TEST_STANDBY)
)
)TEST_PRIMARY =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = rac01-scan.test.local)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = TEST)
)
)
3. Ставим клиентское ПО Oracle на нашу клиентскую виртуальную машину client01: InstantClient и Administrator
Добавляем в файл C:\app\user\product\11.2.0\client_2\network\admin\tnsnames.ora следующие строчки:TEST_STANDBY =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = rac02-scan.test.local)(PORT = 1521))
(CONNECT_DATA =
(SERVICE_NAME = TEST_STANDBY)
)
)TEST_PRIMARY =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = rac01-scan.test.local)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = TEST)
)
)4. На вский случай пересоздадим standby database:
[oracle@rac02-scan]$ sqlplus sys as sysdba
SQL> shutdown immediate
SQL> startup nomount;]$ rman target=/
RMAN> connect auxiliary sys/secret@TEST_STANDBY
RMAN> run
2>
3> allocate channel prmy1 type disk;
4> allocate channel prmy2 type disk;
5> allocate channel prmy3 type disk;
6> allocate channel prmy4 type disk;
7> allocate auxiliary channel stby type disk;
8> duplicate target database for standby from active database dorecover nofilenamecheck;
9> >]$ sqlplus sys as sysdba
SQL> shutdown immediate
SQL> startup mount;5. Создадим конфигурацию Data Guard Broker:
Стартуем брокеров:
[oracle@rac-node01]$ dgmgrl
DGMGRL> connect sys/secret@TEST_PRIMARY
DGMGRL> create configuration TEST as primary database is TEST connect identifier is TEST_PRIMARY;
DGMGRL> add database TEST_STANDBY as connect identifier is TEST_STANDBY maintained as physical;
DGMGRL> show configuration;Fast-Start Failover: DISABLED
Configuration Status:
DISABLEDDGMGRL> enable configuration;
DGMGRL> show configuration
Fast-Start Failover: DISABLED
Configuration Status:
SUCCESSDGMGRL> show database test_standby
Role: PHYSICAL STANDBY
Intended State: APPLY-ON
Transport Lag: 0 seconds
Apply Lag: 0 seconds
Real Time Query: OFF
Instance(s):
TEST6. Проверим наличие управляющих интерфейсов DGMGRL на всех хостах. Они нужны для того, чтобы можно было управлять базой когда она в состоянии shutdown.
Выглядит такой интерфейс как статически определенный в файле listener.ora сервис с именем <db_unique_name>_DGMGRL.<db_domain>.
Вообще то, оно должно добавиться автоматически, но чаще не добавляется, чем добавляется. Проверяем, если нет, добавляем.(SID_DESC =
(GLOBAL_DBNAME = TEST_STANDBY_DGMGRL)
(ORACLE_HOME = /u01/app/oracle/product/11.2.0/dbhome_1)
(SID_NAME = TEST)
)На всех хостах рестартуем listener и проверяем наличие сервиса:
srvctl stop listener
srvctl start listener
lsnrctl status
7. Для единообразия создадим сервис test.rac на standalone сервере rec02-scan (на кластере такой сервис у нас уже есть).
Для этого нужно выполнить switchover на TEST_STANDBY:
[oracle@rac-node01И, собственно, создать сервис:
[oracle@rac02-scanSQL> show parameter service
SQL> show parameter listener
Добавим триггеры, которые будут запускать сервис при смене роли БД на PRIMARY (на кластере RAC сервис автоматически запускает clusterware, там нам не нужно заботиться):
[oracle@rac02-scan]$ sqlplus sys@TEST_STANDBY as sysdba
SQL> DEFINE _EDITOR = nano
SQL> edit rolechangeonstartupSQL> start rolechangeonstartup;
SQL> edit whenrolechange
SQL> start whenrolechange;
DGMGRL> show configuration
Fast-Start Failover: DISABLED
Configuration Status:
SUCCESS]$ lsnrctl status
Убеждаемся, что сервиса test.rac нет.]$ dgmgrl
DGMGRL> connect sys/secret@TEST_PRIMARY
DGMGRL> switchover to test_standby9. Теперь потестируем failover.
Для начала проверяем, что на обеих базах включен flashback (он нужен после failover и восстановления старого primary для выполнения процедуры превращения старого primary в standby)
SQL> SELECT LOG_MODE,FLASHBACK_ON FROM V$DATABASE;Исходное состояние:
DGMGRL> show configurationFast-Start Failover: DISABLED
Configuration Status:
SUCCESSБыстро, решительно выключаем базу на хосте rac02-scan (якобы у нас произошла авария):
[oracle@rac02-scan]$ sqlplus sys@TEST_STANDBY as sysdb
SQL> shutdown abort;Представим, что аварию на хосте rac02-scan удалось ликвидировать:
[oracle@rac02-scan]$ sqlplus sys@TEST_STANDBY as sysdba
SQL> startup mountПревращаем rac02-scan в standby:
DGMGRL> reinstate database test_standbyDGMGRL> show configuration
Fast-Start Failover: DISABLED
Configuration Status:
SUCCESS10. Сейчас посмотрим как отрабатывается failover на стороне клиента.
Настроим сразу оба типа. Идем на client1 и в файлы добавляем:
C:\app\user\product\11.2.0\client_2\network\admin\sqlnet.oraTEST =
(DESCRIPTION =
(Address_list =
(load_balance = off)
(Failover = on)
(ADDRESS = (PROTOCOL = TCP) (Host = rac01-scan) (Port = 1521))
(ADDRESS = (PROTOCOL = TCP) (Host = rac02-scan) (Port = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = test.rac)
(FAILOVER_MODE =
(TYPE = SELECT)
(METHOD = BASIC)
(Retries = 180)
(DELAY = 5)
)
)
)Проводим подготовительные мероприятия:
C:\Windows\System32>chcp 1251
C:\Windows\System32>SET LOCAL=TEST
C:\Windows\System32>sqlplus sys as sysdba
SQL> select name, database_role from v$database;SQL> SELECT INSTANCE_NAME FROM v$instance;
SQL> show parameters uniq
Создадим тестовую табличку в базе:
SQL> connect soe/soe;
SQL> create table s (n number not null);Понавставляем в нее некоторое количество значений.
SQL> select * from s;
11. Сейчас потестируем автоматический failover на стороне сервера.
Включаем Fast Start Failover и запускаем observer на client1 :
DGMGRL> enable fast_start failover;
Включено.
DGMGRL> show configurationБыстрое автоматическое переключение при отказе: ENABLED
Состояние конфигурации:
SUCCESSDGMGRL> start observer
12. И, наконец, удаление конфигурации.
[oracle@rac-node01]$ dgmgrl
DGMGRL> connect sys/secret@TEST_PRIMARY
DGMGRL> remove configuration]$ sqlplus sys@TEST as sysdba
SQL> show parameters log_archive_config;]$ sqlplus sys as sysdba
SQL> show parameters log_archive_config;Вот вроде бы и все. Но есть особенность. После этого попытался я перестартовать RAC DB:
[oracle@rac-node01]$ srvctl stop database -d TEST
Ан не тут то было:
[oracle@rac-node01В указанном логе ничего криминального не нашел. Нечего делать, нужно идти читать alert log:
Alert Log находится: $ORACLE_BASE/diag/rdbms/<sid>/<instance>/trace/alert_<instancename>.log
у нас $ORACLE_BASE = /u01/app/oracle/
значит
[oracle@rac-node02]$ tail -200 /u01/app/oracle/diag/rdbms/test/TEST2/trace/alert_TEST2.log
Наш dgmgrl вычистил настройки только с одного из узлов кластера. Проверяем:
[oracle@rac-node02]$ ORACLE_SID=TEST2; export ORACLE_SID
[oracle@rac-node02]$ sqlplus sys as sysdba
SQL> startup mount;
SQL> SELECT INSTANCE_NAME FROM v$instance;SQL> show parameters log_archive_config
]$ srvctl status database -d TEST
Instance TEST1 is running on node rac-node01
Instance TEST2 is running on node rac-node02Конфигурация fast-start-failover
![SUBD_Deep_4.6_site-5020-c7a1b8.jpg]()
Fast Start Failover — функционал автоматического запуска failover в случае необходимости. По умолчанию выключен. Процедура Failover инициируется сервисом DG observer (см. рисунок ниже). Собственно observer — это маленький OCI клиент, встроенный в DGMGRL CLI. Также observer автоматизирует превращение (reinstate) старого primary в standby.
![clipboard02-5020-bf88ac.jpg]()
Схема его работы весьма проста: если observer и standby одновременно потеряли связь с primary, но видят друг друга — инициируется failover. После появления в поле видимости старого primary observer автоматически пытается превратить его в standby.
Располагать этот сервис рекомендуется на третьей площадке (если считать, что площадка primary — первая, а standby — вторая), лучше всего на площадке, где расположены клиенты.
Далее приведу настройки, которые нужно выполнить.
Сервера:
— oracle-1 10.10.0.20 — PRIMARY; — oracle-2 10.10.0.21 — STANDBY; — oracle-observer 10.10.0.22 — установлен oracle-client.
Настройка tnsnames.ora:
Tns настраивается на всех 3-х серверах.
Создание standby
Создать pfile и перенести его на standby на PRIMARY: ```oracle-sql CREATE PFILE='/tmp/init.ora' from spfile;
Запустить rman и законнектиться к обеим базам:
Создаём конфигурацию Data Guard:
Включаем обсервер: dgmgrl -logfile $HOME/observer.log sys/<PASS>@ORA_MASTER "start observer" & Проверяем, что конфигурация включилась и работает:
Вот и всё, пишите комментарии. Если интересуют подробности, держите ссылку по теме.
Структура базы данных Oracle
База данных Oracle включает в себя: — табличные пространства; — управляющие файлы; — журналы; — архивные журналы; — файлы трассировки изменения блоков; — ретроспективные журналы; — файлы резервных копий (RMAN).
Табличные пространства Oracle
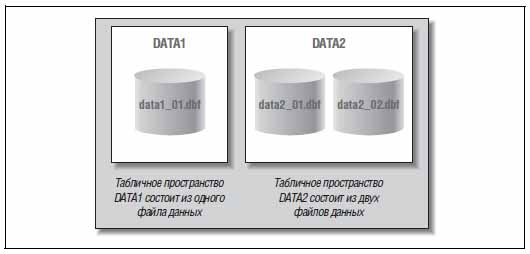
Любые данные, которые хранятся в базе данных Oracle, просто обязаны существовать в каком-либо табличном пространстве. Под табличным пространством (tablespace) понимают логическую структуру, то есть вы не сможете попросить ОС показать вам табличное пространство Oracle.
При этом каждое табличное пространство включает в себя физические структуры, называемые файлами данных (data files). Одно табличное пространство Oracle способно содержать один либо несколько файлов данных, в то время как каждый файл данных может принадлежать лишь одному tablespace. Создавая таблицу, мы можем указать, в какое именно табличное пространство мы её поместим — Oracle находит для неё место в каком-нибудь из файлов данных, которые составляют указанное табличное пространство.
На рисунке ниже вы можете посмотреть на соотношение между файлами данных и табличными пространствами в базе данных Oracle.
![tablespaces_data_files_Oracle_1-20219-802832.jpg]()
Создавая новую таблицу, мы можем поместить её в табличное пространство DATA1 либо DATA2. Таким образом, физически наша таблица окажется в одном из файлов данных, которые составляют указанное табличное пространство.
Файлы базы данных Oracle
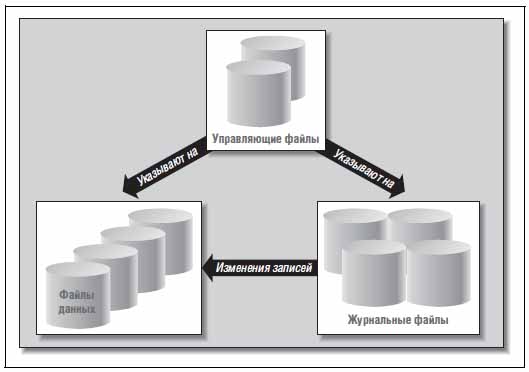
База данных Oracle может включать в себя физические файлы 3-х основных типов: • control files — управляющие файлы; • data files — файлы данных; • redo log files — журнальные файлы либо журналы.
Посмотрим на отношения между ними:
![oracle_database_files_1-20219-34b3e2.jpg]()
В управляющих файлах содержится информация о местонахождении других физических файлов, которые составляют базу данных Oracle, — речь идёт о файлах данных и журналов. Также там хранится важная информация о содержимом и состоянии БД Oracle. Что это за информация: • имя базы данных Oracle; • время создания БД; • имена и местонахождение журнальных файлов и файлов данных; • информация о табличных пространствах; • информация об архивных журналах; • история журналов, порядковый номер текущего журнала; • информация о файлах данных в автономном режиме; • информация о резервных копиях, контрольных точках, копиях файлов данных.
При этом функция управляющих файлов не ограничивается хранением важной информации, нужной при запуске экземпляра, — полезны они и в процессе удалении БД Oracle. К примеру, уже с версии Oracle Database 10g можно посредством команды DROP DATABASE удалить все файлы, которые перечислены в управляющем файле БД, включая сам управляющий файл.
Базы данных Oracle: экземпляры и сущности
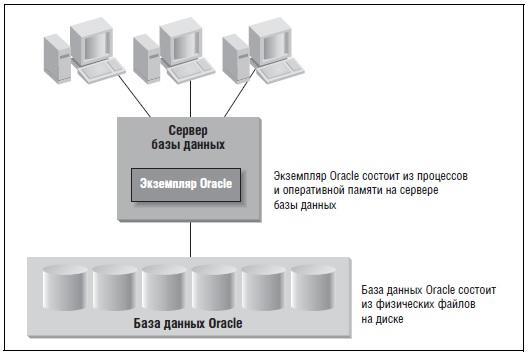
СУБД Oracle Database включает в себя физические и логические компоненты. Особого упоминания заслуживает понятие экземпляра. Замечено, что некоторые используют термины «база данных» и «экземпляр» в качестве синонимов. Да, это взаимосвязанные, но всё же разные вещи. База данных в терминологии Oracle — это физическое хранилище информации, а экземпляр — это программное обеспечение, которое работает на сервере и предоставляет доступ к информации, содержащейся в базе данных Oracle. Экземпляр исполняется на конкретном сервере либо компьютере, в то самое время как база данных хранится на дисках, подключённых к этому серверу:
![instans_and_Oracle_Database_1-20219-067a61.jpg]()
При этом база данных Oracle является физической сущностью, состоящей из файлов, которые хранятся на дисках. В то же самое время, экземпляр – это сущность логическая, состоящая из структур в оперативной памяти и процессов, которые работают на сервере. Экземпляр может являться частью только одной базы данных. При этом с одной базой данных бывает ассоциировано несколько экземпляров. Экземпляр ограничен по времени жизни, тогда как БД, условно говоря, может существовать вечно.
Также стоит заметить, что у пользователей нет прямого доступа к информации, которая хранится в базе данных Oracle — они должны запрашивать эту информацию у экземпляра Oracle.
Если упрощённо, то экземпляр — это мост к базе данных, а сама БД – это остров. Когда экземпляр запущен, мост работает, а данные способны попадать в базу данных Oracle и покидать её. Если мост перекрыт (экземпляр остановлен), пользователи не могут обращаться к базе данных, несмотря на то, что физически она никуда не исчезла.
Data Guard Broker
Fast Start Failover
![Clipboard02]()
База данных Oracle. Структура и основные понятия СУБД Oracle
Oracle Database — это объектно-реляционная СУБД (система управления базами данных), созданная компанией Oracle. В настоящее время она имеет множество разных версий и типов. Однако в этой статье мы поговорим не о видах баз данных Oracle, а о структуре и основных концепциях, которые относятся к СУБД Oracle Database. Поняв архитектуру СУБД Oracle, вы заложите фундамент, необходимый для понимания прочих средств (а они весьма обширны), предоставляемых базой данных Oracle.
Инициализация СУБД Oracle
Когда вы запускаете экземпляр Oracle, происходит считывание параметров инициализации. Параметры определяют, каким образом базе данных Oracle следует использовать физическую инфраструктуру и прочую конфигурационную информацию об экземпляре.
Как правило, инициализационные параметры хранятся в файле параметров инициализации экземпляра (обычно это INIT.ORA) либо, начиная с Oracle9i, в репозитории, называемом файлом параметров сервера (SPFILE). С выходом каждой новой версии Oracle число обязательных параметров инициализации уменьшается.
Кстати, в дистрибутиве Oracle можно найти пример файла инициализации, который пригоден для запуска базы данных. Также можно воспользоваться специальной программой Database Configuration Assistant (DCA) — она подскажет обязательные значения.
Более подробную информацию смотрите в официальной документации для СУБД Oracle Database.
Системная архитектура и все-все-все
Oracle Data Guard между RAC и standalone. Часть третья: Data Guard Broker, Fast Start Failover, автоматический failover на стороне клиента
Продолжение, начало тут и тут.
![Clipboard02]()
Для начала немного теории:
Автоматический failover на стороне клиента
На серверах произошел failover или switchover, клиент должен подключиться или продолжить работу (т.е. переподключиться). Желательно автоматически. Желательно не потеряв данные. Желательно незаметно для приложения.
В случае Connect-time Failover все просто: даем список адресов и говорим пробовать подключаться к следующему, если предыдущий недоступен.
В случае Run-time Failover есть варианты, но всех их роднит то, что транзакция, в ходе которой произошел failover, вылетает с ошибкой и приложению нужно эту ситуацию обработать:
- Transparent Application Failover для OCI based applications like sqlplus and JDBC thick clients
- Fast Connection Failover для JDBC thin connections
Подробности в виде презентаций: TAF, FCF и FAN.
Читайте также: