
Сравнение процессоров atom
Обновлено: 04.07.2024
Много воды утекло, каждый следующий ЦП (кроме серверных) выпускался как в обычном, так и в мобильном (иногда ещё и во встроенном) варианте, но все манипуляции в основном заключались в добавлении к ядру энергосберегающих режимов и отборе чипов, способных работать на пониженном напряжении при пониженных частотах. Между тем, конкуренция со стороны архитектур, разработанных специально для мобильных устройств, усилилась: 1990-е принесли появление PDA (начиная с Apple Newton MessagePad), а 2000-е дали коммуникаторы, интернет-планшеты (полузабытая аббревиатура MID) и ультрамобильные ПК (UMPC). В довесок ко всему оказалось, что основные задачи для пользователя таких устройств имеют небольшие вычислительные потребности, так что почти любой ЦП, выпущенный после 2000 г., уже обладал нужной мощностью для мобильного применения, кроме, разве что, современных игр (для которых как раз тогда появились мобильные консоли с 3D-графикой).
Назрела необходимость сделать специальную архитектуру для компактного мобильного устройства, где главное — не скорость, а энергоэффективность. В Intel такую задачу взяло на себя израильское отделение компании, создавшее до этого весьма удачное семейство мобильных процессоров Pentium M (ядра Banias и Dothan). В этих ЦП энергосберегающие принципы были поставлены во главу угла с самого начала разработки, так что динамическое отключение блоков в зависимости от их загрузки и плавное изменение напряжения и частоты стало залогом экономности серии. Особенно ярко Pentium M смотрелись на фоне выпускаемых тогда же Pentium 4, которые в сравнении с ними казались раскалёнными сковородками. Причём, работая на одной частоте, Pentium M выигрывали у «четвёрок» по производительности, что вообще впервые случилось в практике процессоростроения — обычно мобильный компьютер расплачивается за свою компактность всеми остальными характеристиками. Впрочем, и сами-то Pentium 4 были, скажем так, не очень хороши в роли универсального ЦП…

Успех платформы показал, что такая высокая скорость нужна не всем, а вот сэкономить ещё энергии было бы неплохо. На тот момент (середина 2007 г.) Intel выпустила «папу» наших сегодняшних героев — процессоры A100 и A110 (ядро Stealey). Это 1-ядерные 90-нанометровые Pentium M с четвертью кэша L2 (всего 512 КБ), сильно заниженными частотами (600 и 800 МГц) и потреблением 0,4–3 Вт. Для сравнения — стандартные Dothan при частотах 1400–2266 МГц имеют энергорасход 7,5–21 Вт, низковольтные (подсерия LV) — 1400–1600 МГц и 7,5–10 Вт, а впервые введённые ультранизковольтные (ULV) — 1000–1300 МГц и 3–5 Вт. Резонно полагая, что современный компьютер большую часть времени проводит в ожидании очередного нажатия клавиши или сдвига мыши ещё на один пиксель, главным отличием A100/A110 от подсерии ULV Intel сделала умение очень глубоко засыпать, когда считать не надо совсем, благодаря чему потребление при простое падает на порядок. А сильно сокращённый кэш (большой L2 на таких частотах не очень-то и нужен) помог уменьшить размер кристалла, что сделало его дешевле. Размер корпуса процессора уменьшился впятеро, а суммарная площадь ЦП и чипсета — втрое. Как мы увидим далее, такие приёмы были использованы и в серии Atom.
Несмотря на в принципе верное целеполагание, A100/A110 остались мало востребованы рынком. То ли 600–800 МГц оказалось всё же маловато даже для простенького интернет-планшета, то ли всего два чипа (что даже модельным рядом назвать трудно) с самого начала были экспериментальным продуктом для обкатки технологии, то ли процессор просто не раскрутили маркетологи, зная, что ему на смену идёт кое-что куда более продвинутое… Менее чем через полгода после выпуска A100/A110 26 октября 2007 г. Intel объявила о близком выпуске новых мобильных ЦП с кодовыми именами Silverthorne и Diamondville и ядром Bonnell — будущих Атомов. Кстати, название Bonnell произошло от имени холмика высотой 240 м в окрестностях г. Остин (штат Техас), где в местном центре разработки Intel располагалась малочисленная группа разработчиков Атома. «Как вы яхту назовёте, так она и поплывёт.» ©Капитан Врунгель

В 2004 г. эта группа, после отмены ведомого ею проекта Tejas (наследника Pentium 4), получила прямо противоположное задание — проект Snocone по разработке крайне малопотребляющего x86-ядра, десятки которых объединит в себе суперпроизводительный чип с потреблением 100–150 Вт (будущий Larrabee, недавно переведённый в статус «демонстрационного прототипа»). В группе оказалось несколько микроэлектронных архитекторов из других компаний, включая и «заклятого друга» AMD, а её глава Belli Kuttanna работал в Sun и Motorola. Инженеры быстро обнаружили, что различные варианты имеющихся архитектур не подходят их нуждам, а пока думали дальше, в конце года CEO Intel Пол Отеллини сообщил им, что этот же ЦП также будет и 1-2-ядерным для мобильных устройств. Тогда было тяжело предположить, как именно и с какими требованиями такой процессор будет применяться через отведённые на разработку 3 года — руководство с большой долей риска указало на наладонники и 0,5 Вт мощности. История показала, что почти всё было предсказано верно.
Устройство CE4100
Теория Атома
Для начала рассмотрим основные характеристики процессора с точки зрения потребителя. Их три: скорость, энергоэффективность, цена. (Правда, энергоэффективность — не очень-то «потребительская» характеристика, но, тем не менее, именно по ней проще всего судить о некоторых важных параметрах конечного устройства.) Далее вспомним, что у идеальной КМОП-микросхемы (по этой технологии изготавливаются все современные цифровые чипы) потребление энергии пропорционально частоте и квадрату напряжения питания, а пиковая частота линейно зависит от напряжения. В результате, уполовинив частоту, мы можем уполовинить напряжение, что в теории уменьшит потребление энергии в 8 раз (на практике — в 4–5 раз). Таким образом, мобильный процессор должен быть низкочастотным и низковольтным. Как же тогда он окажется быстрым? Для этого надо, чтобы за каждый такт он выполнял как можно больше команд, что чаще всего означает увеличение числа конвейеров (степени суперскалярности) и/или числа ядер. Но это ведёт к резкому росту транзисторного бюджета, что увеличивает площадь чипа, а значит и его стоимость.
Добавим также, что так называемый «буфер переупорядочивания» и «резервационные станции» — довольно ресурсоёмкие блоки, которым приходится решать сложную задачу определения свободных ресурсов и взаимозависимостей в претендующих на исполнение командах. Единственный способ сделать это за 1 такт — разменять вычислительную сложность на избыточность. Для 3–4-путных конвейеров это делается с помощью сотен и тысяч компараторов, срабатывающих каждый такт и проверяющих все возможные комбинации запуска мопов. Что, разумеется, требует немалой площади и изрядного количества энергии. Гиперпоточность же требует лишь дополнительных буферов для хранения второго состояния конвейера (для «другого» потока), дубликата регистрового файла и относительно несложной логики, согласующей и переключающей потоки, а остальные ресурсы — общие.
Ядро Атома

Конвейер Атома
| Стадия | IF1 | IF2 | IF3 | ID1 | ID2 | ID3 | SC | IS | IRF | AG | DC1 | DC2 | EX1 | FT1 | FT2 | IWB/DC |
| Группа | Выборка из L1I (Instruction fetch) | Декодирование (Decode) | Планировка (Schedule) | Чтение регистрового файла (RF read) | Генерация адреса, доступ к L1D (Address generation, Data cache) | Исполнение (Execution) | Обработка исключений и гиперпоточности (Except/MT handle) | Отставка, запись результатов (Writeback, Data Commit) | ||||||||
Для ускорения замеров длин с L1I связан буфер тегов предекодирования, где хранится разметка границ команд. Такое решение оправдано для экономии энергии при исполнении уже встретившегося кода и похоже на используемое в ядрах AMD K7–K10, где работа ILD происходит при считывании из L2 в L1I — правда, там эта схема предназначена для ускорения основного декодирования. А вот в Атоме биты разметки определяются и отправляются в буфер лишь при первом исполнении закэшированного кода, что происходит со скоростью 3 такта/байт (у AMD — 4 байта/такт). Причина такой нерасторопности — очень простой последовательный длиномер. При этом стадию ILD все команды проходят всегда, просто ранее встретившиеся, считав готовую разметку, проходят её «навылет», не напрягая транзисторы — и снова экономия приводит к удлинению конвейера.
Выход декодера подключен к 32-моповой очереди, которая статически делится надвое при включенной HT. Весь front-end («голова конвейера» от предсказателя до очереди мопов) может работать в отрыве от back-end (исполнительного «хвоста») в случае задержек данных или исполнении долгой команды, наполняя очередь мопами про запас.
Сила Атома
Из этого разгромного по сути списка запрещающих условий становится понятно, что суперскалярность у Атома не то чтобы номинальная, а даже «вычурно кривая». Вряд ли микроархитектурщики Intel резко поглупели, но погоня за крайней простотой и энергоэффективностью довела архитектуру до абсурда, когда один из двух конвейеров будет часто простаивать из-за слишком строгих правил спаривания. Некоторым облегчением является то, что запуск команд с разной длительностью исполнения не приводит к штрафам. Аналогично — обработка данных не своего типа (для векторных команд). Например, можно использовать команду MOVAPS для целых чисел.
Самым частым камнем преткновения для архитектур с упорядоченным исполнением является кэш-промах, на обслуживание которого может потребоваться 10–200 тактов. При промахе такой ЦП просто ждёт (в лучшем случае — приостановив тактирование для экономии), а архитектура с OoO — исполняет команды, накопленные в буфере перетасовки и независящие по данным от результата проблемной команды. Ситуация настолько частая, что совсем не иметь никакого механизма перетасовки показалось инженерам Intel неоправданным — и они придумали добавку под названием Safe Instruction Recognition (безопасное распознавание команд). Она всё же даёт процессору некоторую вольность в обращении с командами, позволяя исполнять их вне очереди, и по сути является OoO-механизмом, работающим в масштабе лишь двух команд, одна из которых должна быть вещественной, а вторая — целой. Если они друг другу не мешают, то первой может запуститься целочисленная команда, имеющая меньшую задержку (если только обе команды и так не планируются на спаривание).
L1D оснащён аппаратным предзагрузчиком (префетчером) из L2, а L2 — из памяти. Благодаря зарезервированным на доступ в L1D трём стадиям конвейера если операнд в памяти кэширован, то команда с ним скорее всего выполнится также быстро, как и с регистром. Наиболее частое исключение — когда доступ к памяти требует команда, исполняемая в порту 0, через который также происходят и обмены с памятью. Кроме того, доступ к памяти и кэшу замедляется на 3 такта (!), если используемые для вычисления адреса регистры недавно записывались.
Надо полагать, что встраивание контроллера памяти (и вообще половины чипсета) в мобильный ЦП является очевидным шагом, особенно вспомнив первые подобные решения уже для 386-х процессоров. Однако Intel это сделала лишь почти через два года после выпуска первых Атомов, когда вышли модели Atom N450, N470, D410 и D510 (ядро Pineview). Подержка DDR3-1066 обещана с лета 2010 г. в моделях N455, N475 и N550, но контроллер памяти всё ещё одноканальный. Тесты показали, что особых преимуществ интеграция не принесла даже для программ, сильно зависящих от пропускной способности памяти: видимо, они и без ИКП упёрлись в слабое вычислительное ядро. Кстати, самый сложный 2-ядерный интегрированный Atom D510 имеет 176 млн. транзисторов, из которых 82 млн. потрачены на «северный мост». Сравните с цифрами для вычислительных ядер.
Выдержка Атома
Энергоэффективность — самое главное достоинство этого процессора. Хотя ЦП не всегда является самым активным потребителем электроэнергии в мобильном устройстве (при простое им оказывается подсветка ЖК-экрана или сам экран в случае применения OLED-матрицы), именно в нём применение энергосберегающих функций и технологий наиболее оправдано. Intel применила не только все накопленные до сих пор приёмы, но и добавила новые.
До Атома, когда дело доходило до анализа «энергоёмкости» нововведений, Intel применяла такое правило: при внедрении или изменении какого-либо блока, на каждые 1% ускорения ЦП должны приходиться не более чем 2% увеличения энергопотребления. Апофеоз сей недальновидной политики не заставил себя долго ждать: им стал Pentium 4. Аминь… Для Pentium M цифра энергоприбавки была уполовинена — не более 1% по ваттам. А для Атома (и, позже, в линейке Nehalem) — уполовинена снова.
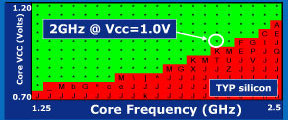
Результат неплох. По первоначальным предположениям младшим моделям для 1,3–1,5 ГГц хватит 0,8 В, для наиболее популярной частоты в 1,6 ГГц потребуется 0,85 В, а одного вольта хватило бы для 2,05 ГГц (если бы такая модель была). Цифры не такие уж и героические, ибо даже для настольных моделей куда более сложной архитектуры AMD K8 (при том, что она для экономии ватт совсем не предназначена), выполненных по последним степпингам предыдущего 65-нанометрового техпроцесса, отдельные чипы при 1 В питания работают на частоте 2,2–2,3 ГГц. Специально оптимизированная под энергосбережение версия 45-нанометрового техпроцесса могла бы дать простому Атому возможность повторить такое достижение в большинстве экземпляров. Но, в отличие от заявлений на слайдах, например, реальный Atom Z530 при частоте 1,6 ГГц питается от 1,213 В — и это специально отобранный для Z-подсерии особо экономный ЦП! «Настольная» модель 230 на той же частоте запитывается от 1,188 В… Atom N280, при простое снижая частоту с 1,66 до 1 ГГц, снижает напряжение до 1,063 В, а N450, интегрированный с северным мостом, — до 0,95.
Спрашивается — за что боролись? А боролись не просто за экономию, а за дешёвую экономию, пусть и при не самых низких напряжениях. ULV Pentium M с TDP 3–5 Вт (при 1–1,3 ГГц и 90 нм) появился за 2,5 года до Атома, но стоил в 3–5 раз дороже. Впрочем, если бы его изготовили на 45 нм, он бы имел и площадь, и цену как раз вчетверо меньше…
Atom также динамически меняет включенную часть L2, следя за активностью доступа. Неиспользуемые банки «сливаются» (выгружают содержимое в память) и отключаются. Впрочем, главной деталью в экономных кэшах является вовсе не микроархитектурно реализованные алгоритмы экономии, а новый дизайн ячейки L1, который тесно связан с размером кэшей, точнее — с неравенством размеров. И снова оставим это на потом — не кэшем единым…
Главными потребителями джоулей в ЦП являются часто переключающиеся транзисторы ядра. И тут у Атома есть, чем похвастаться: помимо того, что этих транзисторов весьма немного за счёт сокращения специализированных блоков (например, есть только один умножитель-делитель и для целых, и для вещественных, и для скаляров, и для векторов), оставшиеся включаются только, тогда когда нужно. Выключен HT — его контроллер отключён от тактирования. Не используются 64 бита — старшая половина целочисленного тракта данных вместе с половинками регистров и ФУ также выключается. Долгое время не нужен FPU или векторный блок — отбой и ему.
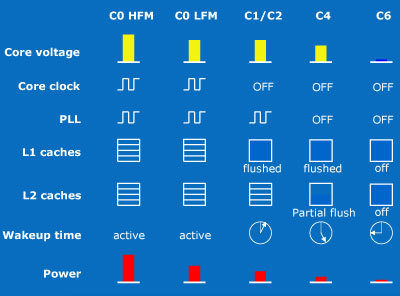
- высоко- и низкочастотный режимы C0 (HFM и LFM), отличаются только частотой (при LFM всегда 600 МГц) и напряжением ядра;
- C1 (он же C2) с нулевым тактированием и «слитыми» (но ещё запитываемыми) кэшами L1;
- C4 с отключенными умножителями частоты, «частично слитым» L2 и ещё больше сниженным напряжением;
- C6, при котором отключено и обесточено почти всё — даже из 203 выводов питания активны лишь 21, уменьшая утечки в 10 раз, а потребление — до 100 мВт (по некоторым данным в новых ЦП Z-серии — до 30 мВт).
- «форсаж» до частоты выше номинальной (C0 Burst Mode);
- ещё более экономный, чем LFM, сверхнизкочастотный режим ULFM C0 (у всех моделей — 200 МГц);
- S0i1 для простоя с быстрой готовностью — переход в S0i1 выполняется за 0,6 мс, а выход — за 1,2 мс (это дольше пробуждения из C6, но речь идёт не только о ядре, а обо всём чипе);
- S0i3 для длительного простоя — вход в него требует 0,45 мс, а выход — 3,1 мс.
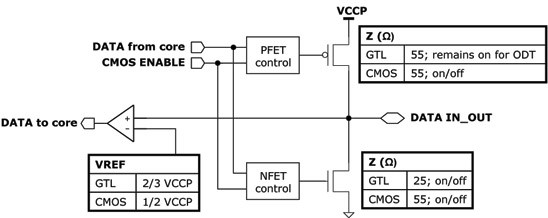
Ещё одно место экономии — сеть распределения тактирования. Дело в том, что синхронизационные сигналы (такты или «тики») необходимо доставлять во все места ядра строго одновременно. Частоты большие, фронты и спады неидеально резкие по времени — умножьте его на скорость света, и полученная цифра (2–5 см) уже вполне сравнима с размером ядра. Чтобы обеспечить одновременную доставку, сигнал распространяется по короткому пути от умножителя частоты до блоков и вентилей, что требует наличие всепокрывающей сети тактирования с огромной паразитной ёмкостью. В результате, скажем, у Pentium 4 на питание такой сети уходило до трети потребляемой мощности. Хотя никаких рекордов частоты Atom ставить не собирается, да и размеры ядра очень скромные — сеть ему не подходит. Сигнал с умножителей проходит по древообразной структуре делителей и усилителей, временные параметры которых подобраны так, чтобы после всех ветвлений приёмники получали такты одновременно. Это уменьшает затраты на тактирование до величины менее 10% от общих.
Виды Атома

Вместо того, чтобы утопить читателя в длинной таблице-«простыне» с параметрами всех моделей Атомов, лучше дать ссылку на уже имеющуюся простыню в Википедии. :) Здесь же прокомментируем увиденное.
2-ядерный Diamondville против однокристального 2-ядерного Pineview со встроенным северным мостом
Для MID также наблюдается самый большой диапазон частот — от 0,8 до 2 ГГц. Из чего логично сделать вывод, что именно на эти применения Intel прежде всего и рассчитывает. Если только не смотреть на цены: самый дешёвый из выпускаемых в мире x86-процессоров — это Atom 230. А самый дешёвый из 2-ядерных — Atom 330. Причём он стоит почти те же $45 (рекомендованная цена), что и 1-ядерный Z500 с половиной частотой (зато TDP последнего в 12 раз меньше). Самый же крутой Z550 в 2,5 раза быстрее и в 3–4 раза дороже. Его точная цена неизвестна: некоторые Атомы продаются только в комплекте с чипсетом, но цена указана именно для ЦП — вокруг этой странности год назад NVIDIA даже поскандалила с Intel, пытаясь купить только процессоры без чипсетов для своей патформы Ion.
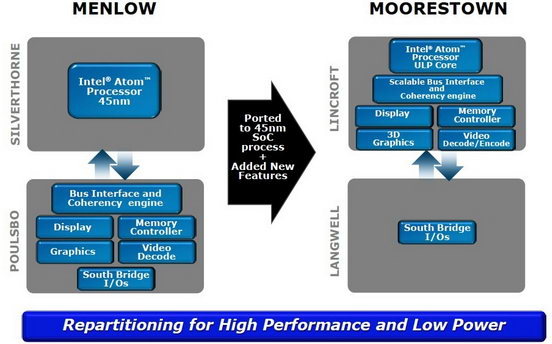
Moorestown в сравнении с Menlow
![]()
В таблицу можно добавить не более 6 процессоров (кнопка "Добавить процессор"). Для ускорения поиска интересующего процессора пользуйтесь фильтром.
Процессоры в таблице можно менять местами, перетаскивая их в нужное место с помощью мышки. "Ухватить" процессор для перетаскивания можно за ячейку с его названием (верхняя ячейка столбца). В этой же ячейке расположена кнопка для удаления процессора из таблицы ("крестик" в верхнем правом углу).
Содержание таблицы можно настраивать, скрывая / добавляя необходимые строки. Кнопка настройки расположена в верхней ячейке первого столбца таблицы.
После выбора процессоров под таблицей отображается общий рейтинг их быстродействия, результаты тестирования в синтетических тестах (PassMark, Geekbench 4, Cinebench R11.5, Cinebench R15 и др), а также уровень быстродействия их встроенных графических чипов (если они есть).
Если в базе сайта отсутствует результат тестирования процессора в определенном бенчмарке, для него отображается предполагаемый показатель, автоматически подсчитываемый системой путем анализа быстродействия процессоров с аналогичными характеристиками.
Предполагаемые результаты визуально отличаются от реальных (серый цвет анаграммы, перед результатом стоит значок "

Наглухо застряв в пробке за рулем машины, теоретически способной развивать скорость более 200 км\ч, и глядя, как меня обгоняют велосипедисты на трехколесных велосипедах, я задумалась… нет, не о том, как пересадить всех на велосипеды, и не о решении транспортных проблем человечества с помощью телепортации, а… о процессорах Intel Core и Intel Atom. А именно — Atom по сравнению с Core — это, фактически, мотороллер по сравнению с автомобилем. Он потребляет меньше топлива и стоит заметно дешевле. Но зато и скорость скутера столь же заметно уступает авто (несмотря даже на способы «разогнать» мотороллер выше заводских установок). Но, все же, в пробках или на узких улочках скутер оказывается быстрее. Недаром скутер получил свое название от английского «to scoot» — удирать, так как успешно использовался английскими подростками для спасения от полиции.
Теперь вернемся к CPU. Заменим «топливо» на «электричество», а «скорость» на «производительность», и получим полную аналогию поведения Inel Atom и Intel Core. Но тогда разумно предположить, что существуют такие «пробки»и «закоулки», в которых Atom обгонит Core. Давайте их поищем.
Итак, по всем общепринятым замерам производительности Intel Core существенно обгоняет Atom. В разделе «Производительность» статьи про Intel Atom в wikipedia читается суровый приговор: "примерно половина производительности процессора Pentium M той же частоты"
Если же сравнивать Atom именно с Core, то по данным тестов tomshardware Intel Core i3-530 побеждает Intel Atom D510 с разгромным счетом:
| 3DS MAX 2010 (рендеринг) | Core i3 быстрее в 4.36 раз |
| Adobe Acrobat 9 (создание pdf). | Core i3 быстрее в 4.55 раз |
| Photoshop CS4 (применение ряда фильтров) | Core i3 быстрее в 3.8 раз |

При этом, надо отметить, что tomshardware к Atom относится явно предвзято. Так, например, если время работы какой-то задачи на Core-i3 — 1:38, то именно так об этом и сообщается — «одна минута, 38 секунд». А если Atom исполняет что-то за 7:26, то это, по мнению авторов «около восьми минут». Но главное — сравнивать процессоры с разной тактовой частотой (2.93 GHz Core i3 и 1.66 GHz Atom ) и не делать поправку
1.76, что дает итоговый результат проигрыша Atom от 2.15 до 2.6 раз.
Почему Atom медленнее?
- Взять
нанонаборнебольшой набор данных, так, чтобы он помещался в кэш. - Попробовать использовать float данные, чтобы загружать не ALU, a FPU
- По возможности, лишить Core преимуществ неупорядоченного исполнения.

1.524
Тесты компилировались Microsoft Visual Studio 2008 с оптимизацией в release по умолчанию.
Полученные данные полностью подтверждают первое место Intel Atom с конца. То есть, цель не достигнута, переходим к следующему пункту — осложним работу Out-of-order CPU.
Усложняем задачу
Создадим искусственный тест, который будет содержать непредсказуемые ветвления, содержащие вычислительно тяжелые функции, так, чтобы результат спекулятивных вычислений Core постоянно отбрасывался, т.е. оказывался ненужной работой.
Примерно так:
Более того, функции будут состоять из цепочечных вычислений, так чтобы Core не мог путем переупорядочивания инструкций и переименования регистров посчитать что-то из таких выражений заранее, «вне очереди». Вот простейший пример подобного кода
Кстати, подобные функции и использованы в вышепоказанных тестах cephes_logf и cephes_expf, где преимущество Core минимально.
Но, несмотря на все препятствия, Core все равно оказался быстрее. Минимальный отрыв Core от Atom, который мне удалось получить различными комбинациями вычислений и случайностей — в целых два раза! То есть, Atom по-прежнему отстает.
Но если бы я на этом остановилась, то вы бы про это просто не узнали — пост бы не состоялся.
Следующим шагом была компиляция тестов с помощью Intel Compiler. Использовалась версия Composer XE 2011 update 9 (12.1) c настройками оптимизации Release по умолчанию — аналогично компилятору Microsoft.
На графике ниже приведены результаты работы вышеупомянутых тестов, включая добавленный мной rand, скомпилированные как VS2008, так и Intel Compiler.

Смотрите внимательно. Это — не обман зрения. Для четырех тестов точки зеленой линии, показывающие результат Atom для тестов, скомпилированных Intel Compiler, находится выше, чем точки бордовой — результат i5 для тестов, скомпилированных VS2008. То есть, Atom оказывается реально, более чем в два раза, быстрее на _том же коде_, что и Core i5.
Думаете, что это реклама компилятора Intel?
Абсолютно нет. Я не работаю ни в отделе рекламы, ни в компиляторной группе.
Это просто констатация того, что ваш оптимизированный код может выполняться на Atom гораздо быстрее, чем неоптимизированный на Core. Или — неоптимизированный на Core будет медленнее, чем оптимизированный на Atom.
Это — как раз те самые кочки и закоулки, которые мешают машине разогнаться.
Выводы можете сделать сами.
Читайте также: