
Voice control engine что это
Обновлено: 30.06.2024
Hello!
I noticed something on my desktop called: VoiceControlEngine.exe (Main Window). It is visually showing on my desktop every time my pc start up, and it is very disturbing. It comes with the MSI SDK and Dragon Center, so I can't uninstall it. But, is there a way to remove it visually from my desktop? it is very annoying.
I am able to resize the window and make it like a line, but still, I don't want to see that on my desktop.

peterthegreatpeterthegrea158d02e8
New member
You can remove it by ending the task in Task Manager. To permanently stop it from coming back, you need to disable its service. Open the Services app, then go to MSI_VoiceControl_Service. Right click on it and click Properties. In the General tab, change the Startup type to Disabled, and if the service is currently running, click the Stop button. Press OK and you shouldn't have to deal with it for any longer.
What I suspect it does, is recognize the "Hey Lucky" voice command that MSI Mystic Light in the Dragon Center optionally uses. I don't know why it forms a window, even when that voice command is disabled by default.
Добавление в приложение голосовых команд
Рассмотрите возможность добавления голосовых команд при создании любого взаимодействия. Voice — это мощный способ управления системой и приложениями. Так как пользователи говорят с разными разновидностями диалектов и диакритических знаков, правильное нажатие ключевых слов распознавания речи гарантирует, что команды пользователей будут интерпретироваться неоднозначно.
Рекомендации
Ниже приведены некоторые рекомендации, которые помогут облегчить распознавание речи.
Преимущества речевого ввода
Голосовой ввод — это естественный способ сообщить о наших намерениях. Речь особенно хороша при обходе интерфейса, поскольку она может помочь пользователям в устранении нескольких шагов интерфейса. Пользователь может сказать "вернуться назад" при просмотре веб-страницы вместо того, чтобы приступать к работе и нажать кнопку "назад" в приложении. Это небольшое время сохранения имеет мощный эмоциональномный результат на восприятии пользователя и дает им небольшой объем суперсовременные. Использование голосовой связи — это также удобный метод ввода, когда наши руки заняты или когда нам предстоит выполнить несколько заданий. На устройствах, где ввод с клавиатуры является сложной возможностью, Диктовка голоса может быть эффективным альтернативным способом ввода текста. Наконец, в некоторых случаях, когда диапазон точности для взгляда и жеста ограничен, Voice может помочь в неоднозначности намерений пользователя.
Преимущества использования голоса для пользователя
- Экономия времени — конечная цель достигается намного эффективнее.
- Сокращение усилий — задания выполняются намного быстрее и не требуют значительных усилий.
- Облегчение восприятия информации — это интуитивно понятно, легко выучить и запомнить.
- Это основе социотехники приемлемое — оно должно попадать в соответствие с социальную нормами поведения.
- Это установившаяся практика — использование голосовой связи легко может стать привычным поведением.
Проблемы с голосовым вводом
Хотя речевой ввод отлично подходит для многих разных приложений, он также сталкивается с несколькими проблемами. Понимание преимуществ и трудностей, связанных с голосовыми вводами, позволяет разработчикам приложений более разумно выбирать способ и время использования речевого ввода и создавать превосходные возможности для пользователей.
Речевой ввод для непрерывного элемента управления вводом Один из них является детализированным элементом управления. Например, пользователю может потребоваться изменить свой том в своем музыкальном приложении. Она может сказать «громче», но не ясно, сколько громкости система должна сделать тому. Пользователь может сказать: «сделайте его немного громче», но «немного» — трудность. Перемещение и масштабирование голограмм с помощью голоса также усложняется.
Надежность распознавания речевого ввода Хотя системы ввода голоса становятся лучше и эффективнее, иногда они могут неправильно слышать и интерпретировать голосовую команду. Ключом является устранение проблемы в приложении. Отправляйте свои отзывы пользователям, когда система прослушивается и что понимается системой, что позволяет понять потенциальные проблемы, связанные с распознаванием речи пользователей.
Ввод голоса в общих пространствах Возможно, голоса не основе социотехники в сферах, к которым вы предоставляете доступ другим пользователям. Вот несколько таких случаев.
Голосовое ввод уникальных или неизвестных слов Проблемы, возникающие при вводе голоса, также поступают, когда пользователи определяют слова, которые могут быть неизвестны для системы, например псевдонимы, определенные сленговых выражений слова или аббревиатуры.
Обучениеные команды voice Хотя конечная цель заключается в естественном противоречии системе, часто приложения по-прежнему используют определенные предварительно определенные команды. Задача, связанная с значительным набором голосовых команд, заключается в том, как научиться выполнять их без перегрузки пользователя и как помочь пользователю в их использовании.
Состояния обратной связи голосовых команд
При правильном применении голосовых команд пользователь понимает, что он может сказать, и получает обратную связь о том, что система услышала его правильно. Эти два сигнала придают пользователю уверенность в правильности выбора голосовых команд в качестве основного метода ввода. Ниже приведена схема, показывающая, что происходит с курсором после распознавания голосовой команды и как он сообщает это пользователю.

1. состояние обычного курсора

2. сообщает о голосовом отзыве, а затем исчезает
3. возвращается к обычному состоянию курсора
Поддержка устройств
| Компонент | HoloLens (1-го поколения) | HoloLens 2 | Иммерсивные гарнитуры |
| Голосовой ввод | ✔️ | ✔️ | ✔️ (с микрофоном) |
Главное, что пользователю следует знать о "речи" в смешанной реальности
- Скажите «SELECT» при нацеливании на кнопку (это можно использовать в любом месте для выбора кнопки).
- Вы можете произнести имя метки кнопки панели приложения в некоторых приложениях, чтобы выполнить действие. Например, при просмотре приложения пользователь может сказать команду "Удалить", чтобы удалить приложение из мира (это экономит время от необходимости выбора его вручную).
- вы можете начать Кортана прослушивать, выполнив слово «эй Кортана». Вы можете задавать ей вопросы ("Привет, Кортана, какая высота Эйфелевой башни"), попросить ее открыть приложение ("Привет, Кортана, открой Netflix") или попросить ее открыть меню "Пуск" ("Привет, Кортана, открой домашнюю страницу") и многое другое.
Языки преобразования текста в речь и голоса, доступные в Windows
Windows 10 и Windows 8.1
Китайский (Китайская Народная Республика)
Сторонние языки для текста в речь
Другие языки для преобразования текста в речь можно приобрести у следующих сторонних поставщиков:
Примечание: Эта информация представлена исключительно для ознакомления. Корпорация Майкрософт не рекламирует стороннее программное обеспечение, а также не занимается поддержкой по вопросам его установки и использования. Для справки по указанным продуктам обратитесь к соответствующему производителю.
Языки
HoloLens 2 поддерживает несколько языков. Помните, что речевые команды всегда будут выполняться в языке интерфейса системы, даже если установлено несколько клавиатур или если приложения пытаются создать распознаватель речи на другом языке.
Voice control engine что это
Пользователи, использующие средства обучения OneNote,средства обучения в Wordи Функцию чтения вслух в области "Редактор" в Office и браузере Microsoft Edge, в этой статье представлены способы скачивания новых языков для функции "Текст в речь" в разных версиях Windows.
Обнаружение команд Voice
Некоторые команды, например команды для быстрой обработки выше, могут быть скрыты. Чтобы узнать, какие команды можно использовать, Взгляните на объект и скажите «что можно сказать?». Откроется список возможных команд. Можно также использовать курсор Head, чтобы найти и раскрывать подсказки голоса для каждой кнопки перед вами.
Если вам нужен полный список, просто скажите «показывать все команды» в любое время.
"Привет, Кортана!"
вы можете сказать "эй Кортана", чтобы открыть Кортана в любое время. Вам не нужно ждать, пока он пойдет, чтобы продолжить задавать вопрос или дать ему инструкцию. например, попробуйте сказать «эй Кортана, что такое погода?». как одно предложение. чтобы получить дополнительные сведения о Кортана и о том, что вы можете сделать, спросите его! скажите «эй Кортана, что можно сказать?» и она будет получать список рабочих и рекомендуемых команд. если вы уже находитесь в Кортана приложении, выберите ? значок на боковой панели, чтобы извлечь это же меню.
команды, относящиеся к HoloLens
- "Что можно говорить?"
- "Перейти на запуск"-вместо раскрытия для перехода в меню "Пуск "
- "Запуск "
- "Переместить сюда"
- "Сделать фотографию"
- "Начать запись"
- "Закончить запись"
- "Показывать луч"
- "Скрыть руки луча"
- "Увеличить яркость"
- "Уменьшить яркость"
- "Увеличение объема тома"
- "Уменьшить объем тома"
- "Отключить" или "включить звук"
- "Завершение работы устройства"
- "Перезапустить устройство"
- "Переход в спящий режим"
- "Что такое время?"
- «Сколько аккумулятора осталось?»
Диктовка
Вместо ввода с помощью воздушныхнаработок речь может оказаться более эффективной для ввода текста в приложение. Это может значительно ускорить ввод данных с меньшими усилиями для пользователя.
Диктовка речи начинается с нажатия кнопки микрофона на клавиатуре
В любой момент, когда найдутся неактивные клавиатура, можно переключиться в режим диктовки вместо ввода. Чтобы начать работу, выберите микрофон на стороне текстового поля ввода.
Проектирование
Концепция программной реализации содержит три этапа, которые реализуются в одном программном продукте, имеющем эргономичный графический интерфейс.
Сбор обучающих примеров.
Для обучения нейросети пользователю предлагается произнести несколько раз заготовленные голосовые метки. Так как записываемые фразы состоят из одного слова, то размер файла не имеет значения. И для дальнейшей обработки звук записывается в формат WAV. Это PCM формат записи без потерь. Он является стандартом для дальнейшей обработки звука с помощью библиотеки python_speech_features языка Python. К аудиофайлу должно прилагаться его “значение”, необходимое для дальнейшего обучения нейросети (соответствующие команды).
Обучение нейронной сети.
Программа считывает аудиофайлы, и производит генерацию новых аудиофайлов путем изменения длины звуковой дорожки, а также изменение высоты, громкости и тембра речи. Это необходимо для увеличения количества примеров для обучающей выборки, что позволит увеличить качество распознавания нейронной сетью. В программе пользователю будет предложено обучить сеть на записанных ранее голосовых метках. Пользователь может также дополнять базу обучающими голосовыми метками, и дообучить нейронную сеть позднее.
После обучения программы на заданных словах, пользователь может приступить к работе или добавить на обучение новые голосовые метки. Обученная нейронная сеть может распознать подаваемые звуковые файлы.
ввод голоса в мртк (смешанная реальность набор средств) для Unity
С помощью мртк можно легко назначить голосовые команды для любых объектов. Используйте профиль ввода речи мртк для определения ключевых слов. Назначая сценарий спичинпусандлер , можно сделать так, чтобы любой объект отвечал на ключевые слова, определенные в профиле речевого ввода. Спичинпусандлер также предоставляет метку подтверждения речи для улучшения достоверности пользователя.
Установка нового языка преобразования текста в речь в Windows 8.1
В любом выпуске Windows 8.1 выполните указанные ниже действия.
Откройте панель управления.
Выберите пункт Язык.
Выберите команду Добавить язык.
В открывшемся диалоговом окне выберите язык, который хотите добавить, а затем в нижней части списка нажмите кнопку Добавить.
Под добавленным языком щелкните Скачивание и установка языкового пакета.
После этого Windows скачает и установит выбранный языковой пакет. Может потребоваться перезагрузить компьютер.
После перезапуска новый язык станет доступен для преобразования текста в речь, и иммерсивное средство чтения в средствах обучения для OneNote сможет распознавать текст и читать его на необходимом языке.
Установка нового языка преобразования текста в речь в Windows 10
В параметрах Windows 10 нужно скачать нужный язык и настроить язык речи.
Выберите кнопку Начните, а затем выберите Параметры.

В представлении Параметры Windows выберите Параметры времени & языке.
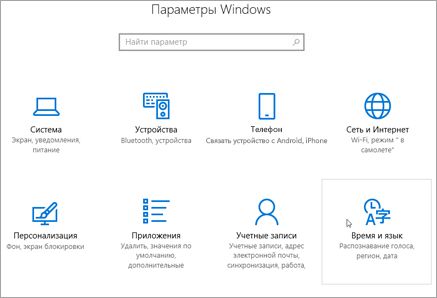
Выберите Язык & регион, а затем выберите Добавить язык.
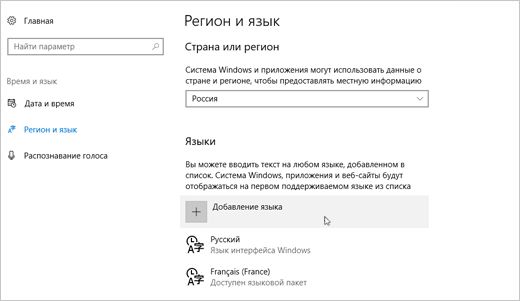
Выберите нужный язык из списка. Начнется установка языка.
После установки нового языка выберите его в списке Язык & регионе, а затем выберите Параметры.
В области Языковые параметры выберите нужные скачивания (языковой пакет, рукописный заметок и клавиатура).
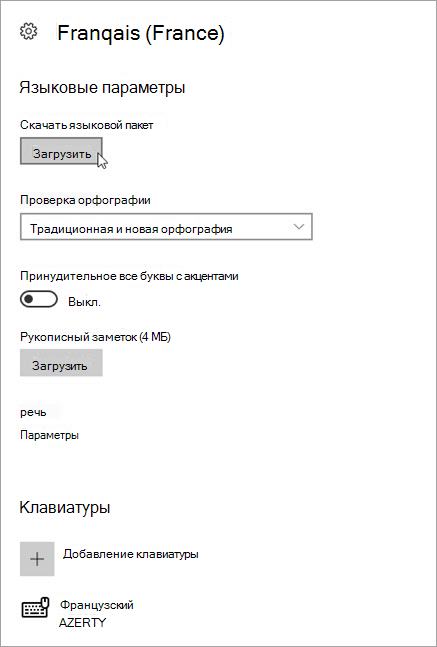
Теперь вам нужно изменить параметры речи по умолчанию. Для начала выберите речь.
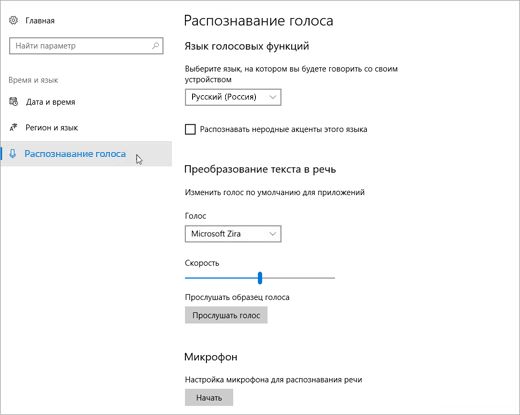
Отсюда настройте параметры речи.
Язык речи: выберите нужный язык в его конце.
Распознайте нестандартные акценты для этого языка. Чтобы активировать эту функцию, поключив этот элемент, нужно включить его.
Для передачи текста в речь: измените голос по умолчанию, скорость голоса и просмотрите его.
Наконец, выберите Начало работы в разделе Микрофон, чтобы настроить микрофон Кортаны.
Голосовой ввод

Голос — один из основных типов ввода в HoloLens. Он позволяет напрямую создавать голограммы без использования жестов руки. Голосовой ввод позволяет естественным способом сообщить о своих намерениях. Речь особенно хорошо работает при обходе сложных интерфейсов, поскольку позволяет пользователям перемещаться по вложенным меню с помощью одной команды.
речевой ввод обеспечивается тем же механизмом , который поддерживает речь во всех универсальных Windows приложениях. на HoloLens распознавание речи всегда будет работать на Windows языке интерфейса, настроенном Параметры устройства.
Распространенные вопросы пользователей о голосовых командах
- Что я могу сказать?
- Как узнать, что система услышала меня правильно?
- Система продолжает неправильно интерпретировать мои голосовые команды.
- Она не реагирует, когда я даю ей голосовые команды.
Команда "Select"
HoloLens (1-го поколения)
HoloLens 2
чтобы использовать команду "select" в HoloLens 2, сначала необходимо открыть курсор «взгляд», чтобы он использовался в качестве указателя. Команду для ее упрощения можно запомнить — просто скажите «SELECT».
Чтобы выйти из режима, снова используйте руки, нажимая на кнопку с пальцами или используя системный жест.
Изображение: Скажите "выбрать", чтобы использовать голосовую команду для выбора
![Пользователь может сказать "выбрать", чтобы использовать голосовую команду для выбора.]()
Команды Voice для быстрой обработки с голограммами
Существует множество голосовых команд, которые можно сказать, облаками на голограммах, чтобы быстро выполнять задачи манипуляции. Эти команды работают с окнами приложений и трехмерными объектами, помещенными в мир.
Команды обработки голограмм
- Лицом мне
- Больше | Улучшение
- Меньше
на HoloLens 2 можно также создать более естественные взаимодействия в сочетании с глазами-взглядом, который неявно предоставляет контекстные сведения о том, на что вы ссылаетесь. Например, можно взглянуть на голограмму и сказать, что _это_«поместить», а затем взглянуть на то, где нужно его поместить, и сказать « _сюда_». Вы также можете взглянуть на сложную часть на сложной машине и сказать: "получить дополнительные сведения об этом".
Устранение неполадок
если у вас возникли проблемы с помощью команды "select" и "эй Кортана", попробуйте переместиться в скрытое место, отключив его к источнику шума или нажимая звук. в настоящее время все распознавание речи на HoloLens настраивается и оптимизируется специально для встроенных докладчиков США английского.
в выпуске Windows Mixed Reality Developer Edition 2017 логика управления конечными точками звука будет работать нормально (бессрочно) после выхода и возврата на рабочий стол компьютера после первоначального подключения хмд. Перед первым выходом и входом в систему после ВМР OOBE пользователь может столкнуться с различными функциями аудио, начиная с отсутствия звука, в зависимости от того, как система была настроена перед первым подключением к ХМД.
Заключение
Таким образом, в научно-исследовательской работе проведен обзор современного рынка голосовых интерфейсов и сфер их использования. Показано, что данный вид программного обеспечения ориентирован на использование в системах дикторонезависимого голосового управления и не учитывает индивидуальных особенностей пользователя, что особенно актуально для людей с ограниченными возможностями здоровья и имеющих речевые нарушения.
Определены требования к голосовому интерфейсу управления вычислительной системой для помощи людям с нарушениями речи.
Описан математический аппарат, подходящий для реализации концепции. Составлен алгоритм программной реализации голосового интерфейса.
Дальнейшее развитие предполагает разработку программы с удобным графическим интерфейсом для реализации прототипа голосового интерфейса управления, который может быть использован для различных задач, таких как управление бытовыми приборами, компьютером, роботизированной техникой (экзоскелетами) людьми с инвалидностью.
Взаимодействие
Для приложений, которые хотят воспользоваться преимуществами настраиваемых параметров обработки ввода звука, предоставляемых HoloLens, важно понимать различные категории звуковых потоков , которые может использовать приложение. Windows 10 поддерживает несколько различных категорий потоков и HoloLens использует три из них для оптимизации качества звука микрофона, предназначенного для речи, обмена данными и других, которые могут использоваться для воспроизведения звука в окружающей среде (то есть «видеокамер»).
- Категория AudioCategory_Communications Stream настроена для сценариев качества вызова и речевого сопровождения и предоставляет клиенту 24-разрядный моно поток на входе пользователя в 16-кГц.
- категория AudioCategory_Speechного потока настроена для обработчика речи HoloLens (Windows) и предоставляет его 24-битный моно поток от пользователя с 16-кгц. При необходимости эта категория может использоваться сторонними обработчиками речи.
- Категория AudioCategory_Other Stream настраивается для записи звука в окружающей среде и предоставляет клиенту 24-разрядный стереофонический аудиопоток 48 кГц.
вся эта обработка аудио аппаратного ускорения означает, что функции заменяют гораздо меньше энергии, чем если бы та же обработка выполнялась на HoloLens цп. Избегайте выполнения других системных входных данных на ЦП, чтобы максимально увеличить время работы батареи системы и воспользоваться преимуществами встроенной, развернутой обработки звукового ввода.
Голосовой интерфейс как способ управления вычислительной системой
Создание систем распознавания речи представляет собой чрезвычайно сложную задачу. Особенно трудно распознать русский язык, имеющий множество особенностей. Все системы распознавания речи можно разделить на два класса:
Системы, зависимые от диктора — настраиваются на речь диктора в процессе обучения. Для работы с другим диктором такие системы требуют полной перенастройки.
Системы, независимые от диктора — работа которых не зависит от диктора. Такие системы не требуют предварительного обучения и способны распознавать речь любого диктора.
Изначально на рынке появились системы первого вида. В них звуковой образ команды хранился в виде целостного эталона. Для сравнения неизвестного произнесения и эталона команды использовались методы динамического программирования. Эти системы хорошо работали при распознавании небольших наборов из 10-30 команд и понимали только одного диктора. Для работы с другим диктором эти системы требовали полной перенастройки.
Для того чтобы понимать слитную речь, необходимо было перейти к словарям гораздо больших размеров, от нескольких десятков до сотен тысяч слов. Методы, использовавшиеся в системах первого вида, не подходили для решения этой задачи, так как просто невозможно создать эталоны для такого количества слов.Для того чтобы понимать слитную речь, необходимо было перейти к словарям гораздо больших размеров, от нескольких десятков до сотен тысяч слов. Методы, использовавшиеся в системах первого вида, не подходили для решения этой задачи, так как просто невозможно создать эталоны для такого количества слов.
Кроме этого, существовало желание сделать систему, не зависящую от диктора. Это весьма сложная задача, поскольку у каждого человека индивидуальная манера произнесения: темп речи, тембр голоса, особенности произношения. Такие различия называются вариативностью речи. Чтобы ее учесть, были предложены новые статистические методы, опирающиеся в основном на математические аппараты Скрытых Марковских Моделей (СММ) или Искусственных Нейронных сетей. Наилучшие результаты достигнуты при комбинировании этих двух методов. Вместо создания эталонов для каждого слова, создаются эталоны отдельных звуков, из которых состоят слова, так называемые акустические модели. Акустические модели формируются путём статистической обработки больших речевых баз данных, содержащих записи речи сотен людей. В существующих системах распознавания речи используются два принципиально разных подхода:
Распознавание голосовых меток — распознавание фрагментов речи по заранее записанному образцу. Этот подход широко используется в относительно простых системах, предназначенных для исполнения заранее записанных речевых команд.
Распознавание лексических элементов — выделение из речи простейших лексических элементов, таких как фонемы и аллофоны. Этот подход пригоден для создания систем диктовки текста, в которых происходит полное преобразование произнесенных звуков в текст.
Обзор различных интернет-источников позволяет выделить следующие программные продукты, решающие задачи распознавания речи и их основные характеристики:
Горыныч ПРОФ 3.0 — это простая в использовании программа, для распознавания устной речи и набора текста путем диктовки с поддержкой русского языка. В ее основе лежат российские разработки в области распознавания устной речи.
- дикторозависимость;
- языкозависимость (русский язык и английский язык);
- точность распознавания зависит от ядра системы американской программы «Dragon Dictate»;
- предоставляет средства голосового управления отдельными функциями операционной системы, текстовых редакторов и прикладных программ;
- требует обучения.
- дикторонезависимость;
- устойчивость к окружающим шумам и помехам в телефонном канале;
- распознавание русской речи работает с надежностью 97% (словарь 100 слов).
- распознавание русской речи работает с надежностью около 95%;
- дикторонезависимость;
- словарный запас около 150 тыс. слов;
- одновременная поддержка нескольких языков;
- компактный размер движка.Sakrament ASR Engine (разработка компании «Сакрамент»)
- дикторонезависимость;
- языконезависимость;
- точность распознавания достигает 95-98%;
- распознавание речи в виде выражений и небольших предложений;
- нет возможности обучения.
- поддержка русского языка;
- возможность встраивать распознавание речи на веб-ресурсы;
- голосовые команды, словосочетания;
- для работы необходимо постоянное подключение к сети internet.
- отсутствует поддержка русского языка;
- точность распознавания до 99%.
- точность распознавания достигает 95-98%;
- дикторонезависимость;
- словарь системы ограничен набором специфических терминов.
- дикторонезависимость;
- распознавание слитной речи;
- обучаемость;
- наличие версии для встраиваемых систем — Pocket Sphinx.
Языки для преобразования текста в речь от производителей ПО с открытым кодом
Бесплатные языки для преобразования текста в речь доступны на сайте компании eSpeak, производящей программное обеспечение с открытым кодом. Эти языки работают в Windows 7, однако в Windows 8, Windows 8.1 и Windows 10 могут возникнуть проблемы с поддержкой. Дополнительные сведения см. в списке всех языков и кодов eSpeak.
Скачивание языков eSpeak
Скачайте установщик для Windows setup_espeak-1.48.04.exe.
Когда файл загрузится, запустите его и нажмите кнопку Далее в первом окне.
Укажите путь установки и нажмите кнопку Далее.
Введите двухбуквенные коды для необходимых языков и флагов. Например, если вам нужно задействовать преобразование текста в речь для английского, испанского, польского, шведского и чешского языков, заполните поля следующим образом:
Концепция голосового интерфейса управления вычислительной системой для помощи людям с нарушениями речи
![image]()
В настоящее время большое внимание уделяется созданию доступной среды для людей с инвалидностью и ограниченными возможностями здоровья. Важным средством обеспечения доступности и улучшения качества жизни, социального взаимодействия, интеграции в общество для людей с инвалидностью являются средства вычислительной техники и специализированные информационные системы. Анализ литературы показал, что на сегодняшний день ведутся различные разработки для облегчения взаимодействия человека и компьютера, в том числе в направлении разработки голосовых интерфейсов управления вычислительной системой. Однако, данные разработки ориентируются на создание дикторонезависимых систем, обучаемых на больших данных и не учитывающих особенности произношения команд компьютеру людьми с различными нарушениями речевых функций.
Целью научно-исследовательской работы является проектирование дикторозависимого голосового интерфейса управления вычислительной системой на основе методов машинного обучения.
Задачи, решаемые в работе:
- Провести обзор голосовых интерфейсов и способы их применения для управления вычислительными системами;
- Изучить подходы к персонализации голосового управления вычислительной системой;
- Разработать математическую модель голосового интерфейса управления вычислительной системой;
- Разработать алгоритм программной реализации.
Математический аппарат распознавания состояния диктора и его особенностей
Для решения задачи, поставленной в работе, проанализируем требования к системе.
Система должна быть:
- дикторозависимой;
- обучаться под особенности произношения конкретного пользователя;
- распознавать определенное количество голосовых меток и переводить их в управляющие команды.
Голосовые команды являются звуковой волной. Звуковую волну можно представить в виде спектра входящих в нее частот. Цифровой звук – это способ представления электрического сигнала посредством дискретных численных значений его амплитуды. В качестве входной информации для работы голосового интерфейса выступает звуковой файл в оперативной памяти, в результате подачи файла на нейронную сеть программа выдает соответствующий результат.
Оцифровка – это фиксация амплитуды сигнала через определенные промежутки времени и регистрация полученных значений амплитуды в виде округленных цифровых значений. Оцифровка сигнала включает в себя два процесса — процесс дискретизации и процесс квантования.
Процесс дискретизации – это процесс получения значений сигнала, который преобразуется с определенным временным шагом, такой шаг называется шагом дискретизации. Количество измерений величины сигнала, выполняемых в одну секунду, называют частотой дискретизации или частотой выборки, или частотой семплирования. Чем меньше шаг дискретизации, тем выше частота дискретизации и тем более точное представление о сигнале нами будет получено.
Квантование – это процесс замены реальных значений амплитуды сигнала приближенными с некоторой точностью значениями. Каждый из 2N возможных уровней называется уровнем квантования, а расстояние между двумя ближайшими уровнями квантования называется шагом квантования. Если амплитудная шкала разбита на уровни линейно, квантование называют линейным или однородным.
Записанные значения амплитуды сигнала называются отсчетами. Чем выше частота дискретизации и чем больше уровней квантования, тем более точное представление сигнала в цифровой форме.
В качестве математического аппарата решения задачи выделения характеризующих признаков целесообразно использовать нейронную сеть, которая сможет обучиться и автоматически выделить необходимые признаки. Это позволит обучать систему под особенности произношения речевых команд конкретного пользователя. Сравнивая механизмы различных нейронных сетей, нами выбраны две наиболее подходящие. Это сеть Коско и Кохокена.
Самоорганизующаяся карта Кохонена — нейронная сеть с обучением без учителя, выполняющая задачу визуализации и кластеризации. Является методом проецирования многомерного пространства в пространство с более низкой размерностью (чаще всего, двумерное), применяется также для решения задач моделирования, прогнозирования, выявление наборов независимых признаков, поиска закономерностей в больших массивах данных, разработке компьютерных игр. Является одной из версий нейронных сетей Кохонена.
Сеть Кохонена является подходящей сетью, так как данная сеть может провести автоматическое разбиение обучающих примеров на кластеры, где количество кластеров задается пользователем. После обучения сети можно рассчитать к какому кластеру относится входной пример, и вывести соответствующий результат.
Нейронная сеть Коско или двунаправленная ассоциативная память (ДАП) — однослойная нейронная сеть с обратными связями, базируется на двух идеях: адаптивной резонансной теории Стефана Гросберга и автоассоциативной памяти Хопфилда. ДАП является гетероассоциативной: входной вектор поступает на один набор нейронов, а соответствующий выходной вектор вырабатывается на другом наборе нейронов. Как и сеть Хопфилда, ДАП способна к обобщению, вырабатывая правильные реакции, несмотря на искаженные входы. Кроме того, могут быть реализованы адаптивные версии ДАП, выделяющие эталонный образ из зашумленных экземпляров. Эти возможности сильно напоминают процесс мышления человека и позволяют искусственным нейронным сетям сделать шаг в направлении моделирования мозга.
Преимущество этой сети является в том, что основе дискретных нейронных сетей адаптивной резонансной теории разработана новая двунаправленная ассоциативная память, способная запоминать новую информацию без переобучения нейронной сети. Это позволяет пользователю пополнять запас голосовых меток в случае необходимости.
«Видите, скажите»
HoloLens имеет модель "видите ит-it" для голосового ввода, где метки на кнопках сообщают пользователям о том, какие голосовые команды также могут говорить. например, при просмотре окна приложения в HoloLens (первое поколение) пользователь может сказать команду "настроить", чтобы настроить расположение приложения в мире.
Изображение: пользователь может сказать команду "настроить", которая отображается на панели приложений, чтобы настроить расположение приложения.
![При просмотре окна приложения или голограммы пользователь может сказать команду "настроить", которая отображается на панели приложений, чтобы настроить расположение приложения в мире]()
Когда приложения следуют этому правилу, пользователи могут легко понять, что следует сказать для управления системой. хотя облаками на кнопке в HoloLens (1-й), вы увидите всплывающую подсказку "voice вдаваясь", которая появляется после второй, если кнопка включена с помощью голоса и отображает команду "нажать". чтобы показать всплывающие подсказки в HoloLens 2, отобразите голосовый курсор, указав "select" или "что можно сказать" (см. изображение).
Изображение: команды отображаются под кнопками.
![Видите, что команды отображаются под кнопками]()
Речь и взгляд
Если вы используете речевые команды, то в качестве стандартного механизма нацеливания используется курсор, который является предметом выбора или для передачи команды в приложение, которое вы ищете. Может даже не потребоваться отображение курсора «взгляд» (см. статью «как»). некоторым голосовым командам не требуется цель, например "перейти на начало" или "эй Кортана".
Читайте также:



