
Metro mirror что это
Обновлено: 02.07.2024
MetroCluster гео-распределённый, отказоустойчивый кластер построенный на базе систем хранения данных NetApp FAS, такой кластер можно представить себе, как одну систему хранения, растянутую на два сайта, где в случае аварии на одном из сайтов всегда остаётся полная копия данных. MetroCluster используется для создания высоко доступного (HA) хранилища и сервисов. Более подробно о MCC официальной документации.
MetroCluster работающий на старой ОС Data ONTAP 7-Mode (до версии 8.2.х) имел аббревиатуру «MC», а работающий на ClusteredONTAP (8.х и старше), чтобы не было путаницы, принято называть MetroCluster ClusteredONTAP (MCC).
MCC может состоять из двух и более контроллеров. Существует три схемы подключения MCC:
- Fabric-Attached MetroCluster (FCM-MCC)
- Bridge-Attached Stretch MetroCluster
- Stretch MetroCluster
Fabric-Attached MetroCluster
Эта конфигурация может состоять как из двух, так и из 4 идентичных контроллеров. Дву-нодовая конфигурация (mcc-2n) может быть конвертирована в четырех нодовую (mcc). В двухнодовой конфигурации на каждом сайте располагается по одному контроллеру и в случае выхода одного контроллера второй на другом сайте забирает на себя управление, это называется switchover. Если на каждом сайте есть больше чем одна нода, при этом выходит из строя одна нода кластера, то происходит локальный HA failover без переключения на второй сайт. MetroCluster может растягиваться до 300 км.
Это самая затратная схема из всех вариантов подключения, так как требует наличия:
- Двойного количества полок
- Один или два канала IP для Cluster peering сети
- Дополнительных SAN свитчей на бэк-енде (не путать со свитчами для подключения СХД и хостов)
- Дополнительных SAS-FC бриджей
- FC-VI порты
- Возможно xWDM мультиплексоров
- И минимум 2 ISL long-wave FC SFP+ линка (4 жилы: 2x RX, 2x TX). Т.е. к СХД подводится «темная оптика» (в промежутках может быть только xWDM, без каких-либо коммутаторов), эти линки выделенные исключительно под задачи репликации СХД (FC-VI & бэк-енд соединения)
Итого между двумя сайтами минимум необходимо 4 жилы, плюс Cluster peering.
Bridge-Attached Stretch MetroCluster
Может растягиваться до 500 метров и требует наличия:
- Двойного количества полок
- Один или два канала IP для Cluster peering сети
- Дополнительных SAS-FC бриджей
- FC-VI порты
- минимум два линка (4 жилы: 2x RX, 2x TX) темной оптики выделенные исключительно под подключение контроллеров СХД (FC-VI)
- И минимум четыре линка (итого 4х2 = 8 жил) темной оптики выделенные исключительно под бэк-енд связи
Stretch MetroCluster с прямым включением
Самый дешевый вариант. Может растягиваться до 500 метров и требует наличия:
- Двойного количества полок
- Один или два канала IP для Cluster peering сети
- FC-VI порты
- минимум два линка (4 жилы: 2x RX, 2x TX) темной оптики выделенные исключительно под подключение контроллеров СХД (FC-VI)
- И минимум два 4 канальных (для каждого канала 2 жили: RX и TX) кабеля (итого 2х8 = 16 жил) темной оптики выделенные исключительно под задачи репликации для доступа к каждой полке по двум путям.
- Для бэк-енд связности полок используется специальный 4 канальный (для каждого канала 2 жили: RX и TX) оптический SAS коннектор и оптическая патч-панель
Итого между двумя сайтами минимум необходимо 4+16=20 жил, плюс Cluster peering.
Оптический кабель для Stretch MetroCluster
В зависимости от расстояния и скорости подключения, применяется различный оптический кабель для конфигураций Stretch MetroCluster с прямым включением.
| Speed (Gbps) | Maximum distance (m) | |||
|---|---|---|---|---|
| 16Gbps SW SFP | 16Gbps LW SFP | |||
| OM2 | OM3 | OM3+/OM4 | Single-Mode (SM) Fiber | |
| 2 | N/A | N/A | N/A | N/A |
| 4 | 150 | 270 | 270 | 500 |
| 8 | 50 | 150 | 170 | 500 |
| 16 | 35 | 100 | 125 | 500 |
FC-VI порты
Обычно на каждый FAS контроллер метро кластера устанавливается специализированная плата расширения, на которой FC порты работают в режиме FC-VI. На некоторых 4-портовых FC HBA платах для FAS контроллеров разрешается использовать 2 порта для FC-VI и 2 других как таргет или инициатор порты. У некоторых FAS моделей порты на борту материнской платы могут переключаться в FC-VI режим. Порты с ролью FC-VI используют протокол Fibre Channel для зеркалирования содержимого NVRAM между контроллерами метро кластера.
Active/Active
Есть два основных подхода при репликации данных:
- «Подход А»: Обеспечивается защита от Split-Brain
- «Подход Б»: В котором есть возможность доступа (чтение и запись) ко всем данным через все сайты
Преимущество «Подхода Б» в том, что нет задержек синхронизации между двумя сайтами. В силу не ведомых мне обстоятельств некоторые производители СХД допускают схемы в которых возможен Spit-Brain. Бывают реализации по сути, работающие по «Подходу А», но при этом эмулирующие возможность писать на обе стороны одновременно, как бы скрывая Active/Passive архитектуру, но суть такой схемы в том, что пока конкретная одна такая транзакция записи не синхронизируется между двумя площадками, она не будет подтверждена, назовём его «Гибридный подход», в ней всё-равно есть основной набор данных и его зеркальная копия. Другими словами, этот «Гибридный подход» всего лишь частный случай «Подхода А», и не стоит её путать с «Подходом Б», несмотря на обманчивое сходство. «Гибридный подход» имеет возможность обратиться к своим данным через удалённый сайт, в таких реализациях, на первый взгляд, есть некое преимущество над классическим вариантом «Подхода А», но по сути он ничего не меняет — задержка синхронизации площадок как была, так и остаётся «Must Have» для защиты от Spit-Brain. Давайте рассмотрим пример на рисунке ниже всех возможных вариантов обращения к данным согласно «Подхода А» (в том числе «Гибридного»).

На рисунке визуализированы 3 варианта возможных путей обращения к данным. Первый вариант (Path 1) это классическая реализация подхода для защиты от Split-Brain: данные проходят один раз по локальному пути и один раз по длинному межсайтовому соединению ISL (Inter Switch Link) для зеркалирования. Этот вариант обеспечивает как-бы Active/Passive режим роботы кластеров, но при этом на каждом сайте есть свои хосты, каждый из которых обращается к своему локальному хранилищу (Direct Path), где обе стороны кластера утилизированы, образуя таким образом Active/Active конфигурацию. В такой Active/Active конфигурации (с «Подходом А») хост переключиться на запасной сайт только в случае аварии, а когда всё восстановиться, вернётся к использованию прежнего «прямого» пути. В то время как «Гибридная схема» (с эмуляцией возможности записи через оба сайта одновременно) позволяет работать по всем 3 вариантам путей. В двух последних вариантах Path 2 & Path 3 имеем полностью обратную картину: данные два раза пересекают длинный межсайтовый канал связи ISL (Indirect Path), что увеличивает скорость отклика. В последних двух вариантах Path 2 & Path 3 нет смысла ни в плане отказоустойчивости, ни в плане производительности, по сравнению с первым, в связи с чем они не поддерживаются в метро кластере NetApp, а работают в режиме Active/Active конфигурации (по классическому «Подходу А») то есть используя прямые пути на каждом сайте, как изображено на картинке Path 1.
Split-Brain
Как было сказано в разделе Active/Active, метро кластер архитектурно устроен таким образом, что локальные хосты работают с локальной половинкой метро кластера. И только в случае, когда целиком один сайт умирает, хосты переключаются на второй сайт. А что происходит если оба сайта живые, но просто пропала связь между ними? В архитектуре метро кластера все просто — хосты продолжают работать, писать и читать, в свои локальные половинки как ни в чём небывало. Просто в этот момент прекращается синхронизация между площадками. Как только линки будут восстановлены, обе половинки метро кластера автоматически начнут синхронизироваться. В такой ситуации данные будет вычитываться с основного плекса, а не как это обычно происходит через NVRAM, после того как оба плекса снова станут одинаковыми зеркалирование вернется в режим репликации на основе памяти NVRAM.
Active/Passive и Unmirrored Aggregates
MCC это полностью симметричная конфигурация: сколько дисков на одном сайте столько и на другом, какие FAS системы стоят на одном сайте, такие же должны быть и на другом. Начиная с версии прошивки ONTAP 9 для FAS систем, допускается иметь Unmirrored агрегаты (пулы). Таким образом, в новой прошивке количество дисков теперь может отличаться на двух площадках. Таким образом, к примеру, на одном сайте могут быть два агрегата, один из них зеркалируется (на удалённом сайте полное зеркало по типам дисков, их скорости, рейд группам), второй агрегат, который есть только на первом сайте, но он не реплицируется на удалённый сайт.
Стоит разделить два варианта Active/Passive конфигураций:
- Первый вариант. Когда используется только один основной сайт, а второй принимает реплику и живёт для подстраховки на случай выключения основного сайта
- Второй вариант. Когда есть 4 или больше ноды в кластере и на каждом сайте используется не все контроллеры

Второй вариант Active/Passive конфигурации собирают для экономии дисков в кластере из 4 или больше нод: только часть из контроллеров будут обслуживать клиентов, в то время как контроллеры, которые простаивают будут терпеливо ждать, когда умрёт сосед, чтобы его подменить. Такая схема позволяет не переключаться между сайтами в случае выхода из строя одного контроллера, а выполнить локальный НА takeover.
SyncMirror — Синхронная репликация
Технология SyncMirror позволяет зеркалировать данные и может работать в двух режимах:
- Local SyncMirror
- MetroCluster SyncMirror
SyncMirror выполняет репликацию как-бы на уровне RAID, по аналогию с зеркальным RAID-60: есть два plex'а, Plex0 (основной набор данных) и Plex1 (зеркало), каждый плекс может состоять из одной или нескольких RAID-DP групп. Почему «как-бы»? Потому-что эти два плекса, они видны как составные, зеркальные части одного агрегата (пула), но на самом деле, в нормально работающей системе, зеркалирование выполняется на уровне NVRAM контроллера. А как вы можете уже знать WAFL, RAID-DP, NVRAM и NVLOG это всё составные части одной целой архитектуры дисковой подсистемы, и их весьма условно можно отделить одно от другого. Важной деталью технологии SyncMirror является необходимость в полной симметрии дисков в двух зеркалированых пулах: размер, тип, скорость дисков, RAID группы должны быть полностью одинаковы. Есть небольшие исключения из правил, но пока я не буду о них упоминать, чтобы не вводить читателя в заблуждение.
Синхронная репликация позволяет с одной стороны снять нагрузку на дисковую подсистему, реплицируя только память, с другой стороны для решения проблемы Split-Brain и проблемы консистентности (с точки зрения структура WAFL на системе хранения) необходимо убедиться, что данные записаны на удалённую систему: в результате «синхронность», в любых системах хранения, увеличивает скорость отклика на время равное времени отправки данных на удалённый сайт + время подтверждения этой записи.
SnapMirror vs SyncMirror
- SyncMirror
- и SnapMirror

Каждый агрегат может содержать один или несколько FlexVol вольюмов (контейнер с данными), каждый вольюм равномерно размазывается по всем дискам в агрегате. Каждый вольюм это отдельная структура WAFL. В случае со SnapMirror, реплика выполняется на уровне WAFL и может выполняться на диски с совершенно другой геометрией, количеством и объёмом.

Если углубляться в технологии, то на самом деле, как Snap так и SyncMirror, для репликации данных используют снепшоты, но в случае SyncMirror это системные снепшоты по событию СP (NVRAM/NVLOG) + снепшоты на уровне агрегата, а в случае SnapMirror это снепшоты снимаемые на уровне FlexVol (WAFL).
SnapMirror и SyncMirror легко могут сосуществовать друг с другом, так можно реплицировать данные с/на метро кластер из другой системы хранения с прошивкой ONTAP.
Memory и NVRAM
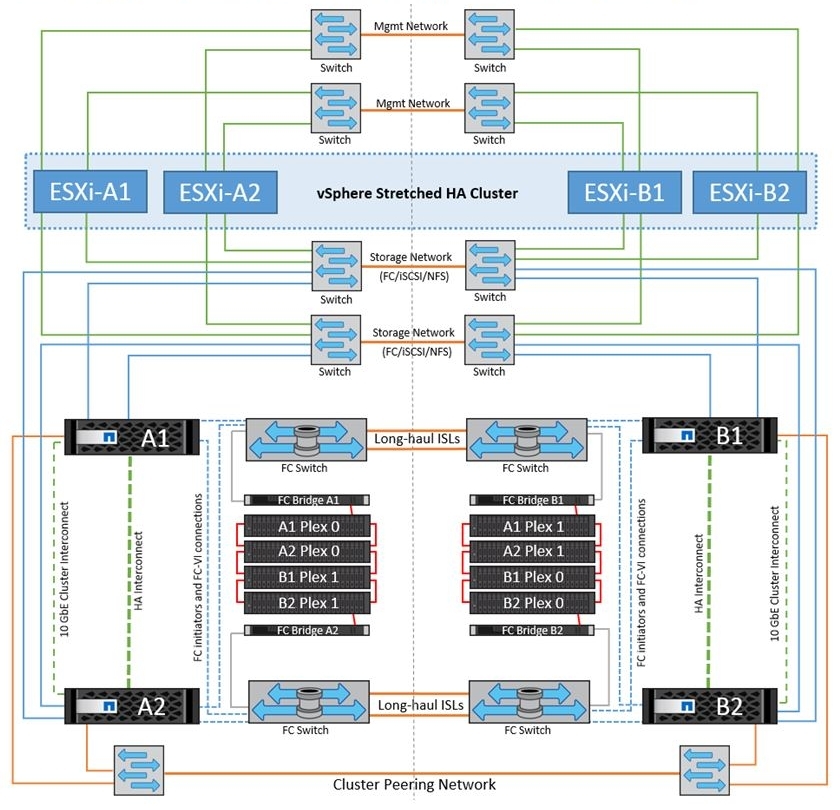
Для того чтобы обеспечить защиту данных от Split-Brain, данные которые поступают на запись попадают в NVRAM в виде логов (NVLOG) и в системную память. Подтверждение записи хосту придёт только после того, как они попадут в NVRAM одного локально контроллера, его соседа (если MCC состоит из 4 нод) и одного удалённого соседа. Синхронизация между локальными контроллерами выполняется через HA interconnect (это обычно внутренняя шина или иногда это внешнее подключение), а синхронизация на удалённую ноду выполняется через FC-IV порты. Локальный НА партнёр имеет только копию NVLOG, он не создаёт полной копии данных, ведь он и так видит диски с этими данными своего НА соседа. Удалённый DR партнёр имеет копию NVLOG и имеет полную копию всех данных (в Plex 1) на своих собственных дисках. Эта схема позволяет выполнять переключение в рамках сайта если второй контроллер HA пары уцелел или переключаться на второй сайт, если все локальные ноды хранилища вышли из строя. переключение на второй сайт происходит за пару секунд.

На картинке показана схема для четырех-нодового метро кластера. Двух-нодовая схема аналогична, но не имеет локального НА партнёра. Восьми-нодовая схема это те же самые две четыре нодовые схемы: т.е. в такой конфигурации реплика NVRAM выполняется в рамках этих 4-х нод, а объединение двух таких четырех нодовых конфигураций позволяет прозрачно перемещать данные между нодами метро кластера в рамках каждого сайта.
NVRAM дополняет технологию SyncMirror: после поступления данных в NVRAM удалённого хранилища, сразу же поступает подтверждение записи, тоесть RAID приходит в полностью синхронное состояние на втором плексе с задержкой, при этом не скомпроментировав консистентность зеркальной копии — это позволяет существенно ускорить работу отклика при зеркалировании половинок метрокластера.
Tie Breaker witness
Для того, чтобы выполнить автоматическое переключение между двумя сайтами необходимо человеческое вмешательство или третий узел, так сказать свидетель всего происходящего, беспристрастный и всевидящий арбитр, который мог бы принять решение какой из сайтов должен остаться в живых после аварии, его называют TieBreaker. TieBreaker это или бесплатное ПО от NetApp для Windows Server или специализированное оборудование ClusterLion.

OnCommand Unified Manager (OCUM)
Если же TieBreaker не установлен, можно переключаться между сайтами в ручном режиме из бесплатной утилиты OnCommand Unified Manager (OCUM) или из командной строки при помощи команд metrocluster switchover.
All-Flash
MCC поддерживает All Flash FAS системы для конфигураций Fabric-Attached и Bridge-Attached Stretch MetroCluster, в них рекомендуется использовать бриджи ATTO 7500N FibreBridge.
FlexArray
Технология виртуализации FlexArray позволяет в качестве бек-энда использовать сторонние СХД, подключая их по протоколу FCP. Допускается не иметь родных полок с дисковыми полками производства NetApp. Сторонние СХД можно подключать через те же FC фабрики, что и для FC-VI подключения, это может существенно сэкономить деньги как на том что в схеме Fabric-Attached MetroCluster устраняется необходимость в FC-SAS бриджах, так и на том, что можно утилизировать существующие позволяя сохранить инвестиции за счёт утилизации старых систем хранения. Для работы FlexArray требуется чтобы такая система хранения была в матрице совместимости.
VMware vSphere Metro Storage Cluster
VMware может использовать с MCC для обеспечения HA на основе аппаратной репликации NetApp. Также, как и в случае с SRM/SRA это плагин для vCenter, который может взаимодействовать с MetroCluster TieBreaker для обеспечения автоматического переключения в случае аварии.
VMware VVOL
Технология VVOL поддерживается с vMSC.
Выводы
Технология MCC предназначена для создания высоко доступного хранилища и высоко доступных сервисов поверх него. Использование аппаратной репликации SyncMirror позволяет реплицировать очень крупные критические корпоративные инфраструктуры и в случае аварии автоматически или вручную переключаться между сайтами производя защиту от Split-Brain. MCC устроен таким образом, что для конечных хостов он выглядит как одно устройство, а переключение для хоста выполняется на уровне сетевой отказоустойчивости. Это позволяет интегрировать MCC практически с любым решением.
Материалы по теме
Гамбургер с шурупом

Истерия бытовых отравлений
Как защититься от миллионов бактерий и токсинов, которые ежедневно атакуютВскоре после ужина ребенок отправился в парк, чтобы поиграть с друзьями. Там у него начались проблемы с дыханием. Мальчик позвонил матери и попросил прислать к нему одного из братьев с ингалятором. Брат привез тему лекарственное средство, но оно не помогло. Холлвуда госпитализировали, однако несмотря на усилия врачей, он скончался в больнице.
Вскрытие показало, что мальчик скончался в результате анафилактического шока, вызванного употреблением орехов. Коронер Алан Мур заключил, что ребенок погиб в результате несчастного случая.
Ранее сообщалось, что организатор свадеб рассказала в TikTok, как свекровь попыталась отравить одну из ее клиенток пирожным, в состав которого входил смертельно опасный для невесты ингредиент. Женщина заказала пирожные с кокосовой начинкой, хотя знала, что у невестки сильная аллергия на кокос.
Metro mirror что это
Корпорация IBM постоянно представляет новые системы хранения данных, оптимизированные для таких рабочих нагрузок, как обработка транзакций и оперативная аналитика в реальном времени. В числе новинок — СХД средней категории IBM Storwize V7000, созданная для более эффективного и экономически выгодного управления большими массивами данных предприятия.
Новая система СХД,применяющая технологию дедупликации IBM ProtecTIER, упрощает задачи администрирования, в частности, установку, настройку и управление, а также сокращает необходимое пространство для аппаратных стоек устройств хранения, сохраняя полезные площади клиентов для последующего роста.
Программное обеспечение IBM System Storage Easy Tier, разработанное IBM Research, автоматически перемещает наиболее активно используемые данные на твердотельные диски (SSD) для обеспечения ускоренного доступа к нужной информации. Менее актуальные данные переносятся на более экономически выгодные системы хранения информации.

Особенности
— Современная функциональность системы хранения корпоративного класса, отличающаяся простотой использования для компаний среднего размера.
— Интегрированная функция IBM System Storage Easy Tier обеспечивает увеличение производительности до 300% благодаря автоматическому переносу данных на высокопроизводительные твердотельные диски (SSD).
— Функция экономного предоставления ресурсов («thin provisioning») позволяет приобретать только необходимую емкость дисков.
— Динамическая миграция обеспечивает постоянную доступность приложений при переносе важнейших данных.
— IBM FlashCopy обеспечивает более быстрое и эффективное копирование данных для целей резервного копирования, тестирования и анализа данных.
— IBM Systems Director предоставляет гибкие возможности управления серверами и системами хранения данных.
— Простые в использовании средства управления данными, разработанные с применением графического пользовательского интерфейса и графических возможностей управления системами.
— Metro Mirror и Global Mirror для синхронной или асинхронной репликации данных между системами с целью повышения эффективности резервного копирования.
— Твердотельные диски для приложений, требующих высокоскоростного и быстрого доступа к данным.
— Redundant Array of Independent Disk (RAID) 0, 1, 5, 6 и 10.
- Электроэнергия, охлаждение, место в серверной, кол-во дисков
- Стандартные тома резервируют емкость, даже если в этом нет
необходимости
- Хранение этих 70% влияет на стоимость и производительность
решения
Забывчивый дедушка приготовил ужин и погубил внука

Подросток из английского города Уинсфорд, графство Чешир, Великобритания, погиб, съев приготовленный забывчивым дедушкой окорок в ореховой глазури. Об этом сообщает издание The Mirror.
12-летний Кейсон Холлвуд страдал от астмы и имел аллергию на орехи. Вместе с тремя братьями Коуэном, Корли и Кейденом и матерью Луизой мальчик отправился на рождественский ужин к бабушке и дедушке. В числе угощений для внуков был приготовленный дедушкой окорок, который впоследствии погубил ребенка. Пожилой англичанин забыл об особенности внука.
Читайте также: