
Medium errors adaptec что значит
Обновлено: 05.07.2024
Часто задаваемый вопрос: "есть ли у SAS-дисков SMART и как его посмотреть?"
Да, в некотором виде есть, в виде лог-страниц с различной полезной информацией. В статье будет рассказано о том, как эту информацию получить и интерпретировать.
Хочется подчеркнуть что, речь ниже пойдет не о домашних пользователях, для которых регулярная проверка здоровья и производительности родного железа может быть чем-то вроде хобби. Да и в случае появления признаков неисправности на том же HDD первой мыслью будет не "немедленно списать и заменить", а "сколько он еще протянет и нельзя ли как-нибудь его починить?". Такой подход вполне имеет право на жизнь, ведь ценность "домашних" данных и объем IT-бюджета, как правило, не очень высоки.
Ситуация в корпоративном секторе или в гарантийном отделе поставщика (как раз наш случай) будет немного другой. Хорошему администратору совершенно не должно быть интересно, к примеру, значение SMART-атрибута Seek_Error_Rate на диске. Логика действий проста: получив информацию от RAID-контроллера о проблемах с диском, выкинуть его из массива и запустить ребилд на новый диск (эту процедуру можно и оптимизировать). Подробности сбоя и "нельзя ли как-нибудь его починить?" никого не интересуют - стоимость потери данных и/или возможного простоя просто не позволяют адекватному сотруднику тратить время на подобные вопросы.
И все же дальнейшая судьба сбойнувшего диска - диагностика. В ней может быть заинтересован либо владелец (например, с целью пристроить более-менее живой диск для каких-либо "небоевых" нужд) и, конечно, гарантийный отдел поставщика - при этом диски могут поступать не по 1-2, а десятками. А проверить нужно в ограниченные сроки, т.е. одновременно по нескольку штук, так что времени на последовательную проверку через MHDD, HDDScan, различные утилиты от производителей и format/verify средствами контроллера просто нет.
- Изначально разрабатывался под Linux, но на данный момент портирован на большое количество платформ, включая различные *BSD и Windows. Кстати, для тех, кто предпочитает GUI - под Linux/FreeBSD/Windows есть отличный фронтенд GSmartControl
- Выводит подробную информацию о диске, включая не только SMART-атрибуты (с расшифровкой многих нестандартных атрибутов), но и страницы с логами ошибок.
- Позволяет запускать поддерживаемые современными ATA и SCSI дисками внутренние тесты самодиагностики (short selftest и long selftest).
- Может работать как при прямом подключении диска, так и через различные USB и Firewire конвертеры. Версии под Linux и FreeBSD позволяют "достучаться" до дисков, подключенных к различным RAID контроллерам (3ware, Areca, HighPoint, HP Smart Array, LSI MegaRAID).
- Может выводить в удобочитаемом виде некоторые лог-страницы SCSI-дисков (к которым, естественно, относится и SAS) - что нам и нужно.
- sg_logs - выводит лог-страницы устройства в более подробном виде, чем smartctl. Пример вывода с разъяснениями будет ниже
- sg_format - выполняет форматирование диска. При очень большом желании можно изменить объем и даже размер сектора.
- sg_verify - выполняет недеструктивную проверку выбранных блоков командой SCSI VERIFY.
- sg_reassign - ручной ремап нужных блоков через SCSI-команду REASSIGN BLOCKS с помещением в Grown defect list
- sg_senddiag - отправка команд на запуск встроенных тестов (то же, что и smartctl --selftest для ATA дисков).
Проверяем
Пациент номер один: относительно 300ГБ старый U320-SCSI диск Fujitsu MAW3300NC. Подключаем и определяем, где его искать (через lsscsi или sg_scan). Далее можно посмотреть на вывод smartctl или sg_logs. Начнем со smartctl:
Примерно тоже можно было бы получить, запустив sg_logs -a, для SAS дисков - с добавкой в виде страницы Protocol Specific port log page for SAS SSP, где перечислены оба phy SAS диска (если он 2-портовыйСразу в глаза бросаются огромное количество ошибок чтения, большое кол-во ремапов (Elements in grown defect list) и предупреждение "SMART Health Status: FIRMWARE IMPENDING FAILURE TOO MANY BLOCK REASSIGNS [asc=5d, ascq=64]". Последнее хранится на странице Informational exceptions в логах диска и говорит нам о том, что дальше его можно и не тестировать: алгоритм, заложенный в firmware уже сделал вывод о предсмертном состоянии диска по большому количеству ремапов.
Отличное от нуля значение счетчика Non-medium error count не всегда указывает на проблемы с диском. Было несколько случаев с SAS-дисками и контроллером Adaptec, когда причиной был некачественный noname кабель.
Можно еще немного помучить диск, запустив самодиагностику, например "длинный" фоновый тест:
Тест прерывается с ошибкой о найденных бэдах, о чем можно узнать, запустив
и посмотрев на соответствующую страницу:
Собственно, при помощи smartctl со SCSI/SAS дисками можно сделать то же, что при запуске sg_logs и sg_senddiag - посмотреть логи и запустить self-test'ы.
Следующий шаг - форматирование. Запускаем
При запуске с этими ключами badblocks совершит 4 пары проходов по диску, записывая и считывая различные паттерны. Занимает очень много времени (5,5 часов для этого диска и почти двое суток для 2ТБ диска).
Итак - 13 бэдов, снова смотрим в логи, видим растущее количество ремапов ошибок чтения. Для очистки совести можно запустить еще раз badblocks или внутренний тест и убедиться в том, что диск по-прежнему находится в совершенно плачевном состоянии. Можно его остановить перед отключением командой
Использование smartctl для проверки RAID контроллеров Adaptec под Linux
Команду «smartctl -d ata -a /dev/sdb» можно использовать для проверки жесткого диска и текущего состояния его соединения с системой. Но как с помощью команд smartctl проверить SAS или SCSI диски, спрятанные за RAID контроллером Adaptec в системах под управлением Linux ОС? Для этого необходимо использовать последовательные синтаксисы проверки SAS или SATA. Как правило — это логические диски для каждого массива физических накопителей в операционной системы. Команду /dev/sgX возможно использовать в качестве перехода через контроллеры ввода/вывода, которые обеспечиваюь прямой доступ к каждому физическому диску, подключенному к RAID контроллеру Adaptec.

Распознает ли Linux контроллер Adaptec RAID?
Для проверки Вы можете использовать следующую команду:
В результате выполнения команды получите следующее:
Загрузка и установка Adaptec Storage Manager для Linux
Необходимо установить Adaptec Storage Manager в соответсвии собранному дисковому массиву.
Проверяем состояния SATA диска
Команда для сканирования накопителя выглядит довольно просто:
В результате у Вас должно получится следующее:
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg . Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
Для SAS диск используют следующий синтаксис:
В результате получим что то похожее на:
А вот команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
Проверить жесткий диск можно с помощью следующих команд:
Использование Adaptec Storage Manager
Другие простые команды для проверки базового состояния выглядят следующим образом:
Обратите внимание на то, что более новая версия arcconf расположена в архиве /usr/Adaptec_Event_Monitor. Таким образом, весь путь должен выглядеть так:
Вы можете самостоятельно проверить состояние массива Adaptec RAID на Linux с помощью ввода простой команды:
Или (более поздняя версия):
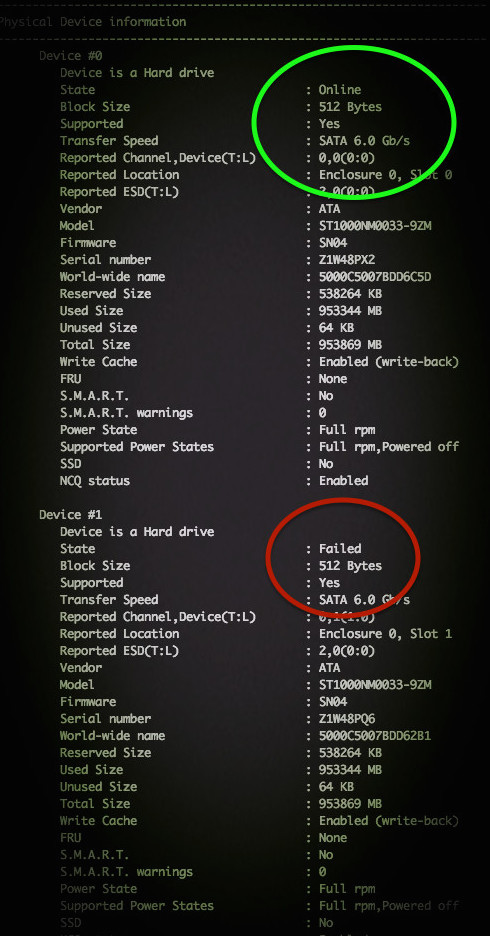
Примерный результат на фото:
По традиции, немного рекламы в подвале, где она никому не помешает. Напоминаем, что в связи с тем, что общая емкость сети нидерландского дата-центра, в котором мы предоставляем услуги, достигла значения 5 Тбит / с (58 точек присутствия, включения в 36 точек обмена, более, чем в 20 странах и 4213 пиринговых включений), мы предлагаем выделенные серверы в аренду по невероятно низким ценам, только неделю!.
Dmitryz
Параметры S.M.A.R.T. для SAS отличаются от SATA
Последнее может указывать на проблемы интерфейса (шлейф!), как и 199 у SATA/IDE.
Проверка диска только на чтение:
-s показывать проценты выполнения -v более подробно
Pass completed, 7 bad blocks found (7/0/0 errors)
Pass completed, 120 bad blocks found (0/0/120 errors)
its read/write/corruption errors. And corruption means comparison with previously written data
Посмотреть состояние дисков на контроллере Adaptec
Работает и на Windows, и на Linux. Должна быть установлена утилита командной строки для управления RAID контроллером Arcconf от Adaptec.
Посмотреть состояние дисков на контроллере в Linux
посмотреть какой у вас контроллер:
Команда для сканирования накопителя выглядит довольно просто:
В результате у Вас должно получится следующее:
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg . Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
Для SAS диск используют следующий синтаксис:
Команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
Seagate ST373307lw и Medium error
Есть пара SCSI винтов - Seagate ST373307LW, которые были в рейде, один вылетел с пометкой Medium error. По хорошему бы заменить но нечем. Вопрос: как можно реанимировать винт с данной ошибкой с минимальными затратами?
Скажу сразу, да знаю, о китайской софтине, которая в один клик исправляет данную ошибку, но просят за нее 500$
Во-первых, наверное не "medium", а "media" error?Во-вторых, "китайская софтина" это такой маленький китаец, который залезает внутрь диска и физически исправляет ошибки на поверхности блинов? Тогда 500$ что-то мало. Я бы и штуку отдал, чтобы на это посмотреть
А по сути - переформатируйте диск из BIOS обычного SCSI контроллера (или на вашем RAID-контроллере, если он это умеет (а большинство умеет)). Если ошибок не много, то поможет (и возможно даже еще несколько лет проживет).
Давайте Вы либо будете решать свои проблемы сами, либо не будете удивляться, если Вам дают правильные советы. Ваша замечательная китайская программа делает не сильно больше, чем дает форматирование диска на SCSI контроллере (просто она это делает несколько быстрее, так как заточена под определенную операцию).
Читайте также: