
Fir driver что это
Обновлено: 16.05.2024

FIR driver, Audio WDM driver. Предназначен автоматической установки всех драйверов для тех, кто не желает устанавливать их по отдельности. Обычно является несколько устаревшим по сравнению с патчами, доступными по отдельности.
802.11BG - каца, что то с беспроводной связью.
Эт дрова для инфракрасного порти и беспроводного подключения к интернету. а вообще, Юль - не парся. там туфта стандартная насована. -)
кстати -очень плохо стал подключатся внешний жесткий диск на 200Гб,я из за этого собственно и залезла в штатный диск-чтобы переустановить драйвера,может поможешь )кстати переустановила верхний и нижний с картинки вроде получше но все равно не очень
Vlad Pisatel Мастер (1513) Угу. нижний драйвер - рс карта (хрень длинная с лева или с права) она для нета (кста,ты в какой стране живешь?) В украине используют. Так вот зайди сюда Пуск-выполнить пропиши dxdiag сделай полную проверку. как сделаешь,напишешь,ок?:-)
PCI Express Config Space
Немного отвлечёмся на один нюанс про PCIE Config Space. С этим адресным пространством не всё так просто - со времён шины PCI для доступа к её конфигурационному пространству используется метод с использованием I/O портов 0xCF8 / 0xCFC. Он применён и в нашем драйвере AsrDrv101:

Чтение и запись PCI Config Space
Но через этот метод доступны только 0x100 байт конфигурационного пространства, в то время как в стандарте PCI Express размер Config Space у устройств может быть достигать 0x1000 байт! И полноценно вычитать их можно только обращением к PCI Extended Config Space, которая замаплена где-то в адресном пространстве, обычно чуть пониже BIOS:

Адресное пространство современного x86 компа, 0-4 ГБ
На чипсетах Intel (ну, в их большинстве) указатель на эту область адресного пространства можно взять из конфига PCI устройства 0:0:0 по смещению 0x60, подробнее описано в даташитах:

У AMD я такого не нашёл (наверняка есть, плохо искал), но сам факт неуниверсальности пнул меня в сторону поиска другого решения. Погуглив стандарты, я обнаружил, что указатель на эту область передаётся системе через ACPI таблицу MCFG
А сами ACPI таблицы можно найти через запись RSDP, поискав её сигнатуру по адресам 0xE0000-0xFFFFF, а затем распарсив табличку RSDT. Отлично, здесь нам и пригодится функционал поиска по памяти. Получаем нечто такое:
На всякий случай оставляем вариант для чипсетов Intel
Всё, теперь осталось при необходимости заменить чтение PCI Express Config Space через драйвер на чтение через память. Теперь-то разгуляемся!
Как использовать IPP FIR фильтры в приложениях максимально эффективно

В библиотеке Intel Performance Primitives (IPP), начиная с версии 8.2, планомерно осуществляется переход от внутреннего распараллеливания функций к внешнему. Причины такого решения изложены в статье Функции IPP c поддержкой бордюров для обработки изображений в нескольких потоках.
В этом посте будут рассмотрены функции, реализующие фильтр с конечным откликом — FIR фильтр (Finite Impulse Response).
Через Python в дебри
Конечно же я захотел сделать свой небольшой "тулкит" для различных исследований и экспериментов на базе такого драйвера. Причём на Python, мне уж очень нравится, как просто выглядит реализация сложных вещей на этом языке.
Первым делом нужно установить драйвер в систему и запустить его. Делаем "как положено" и сначала кладём драйвер (нужной разрядности!) в System32:
Раньше в похожих ситуациях я извращался с папкой %WINDIR%\Sysnative, но почему-то на моей текущей системе такого алиаса не оказалось, хотя Python 32-битный. (по идее, на 64-битных системах обращения 32-битных программ к папке System32 перенаправляются в папку SysWOW64, и чтобы положить файлик именно в System32, нужно обращаться по имени Sysnative).
Затем регистрируем драйвер в системе и запускаем его:
А дальше запущенный драйвер создаёт виртуальный файл (кстати, та самая колонка "имя" в таблице с анализом дров), через запросы к которому и осуществляются дальнейшие действия:

И ещё одна полезная программа для ползания по системе, WinObj
Тоже ничего особенного, открываем файл и делаем ему IoCtl:
Вот здесь чутка подробнее. Я долго думал, как же обеспечить адекватную обработку ситуации, когда таких "скриптов" запущено несколько. Не останавливать драйвер при выходе нехорошо, в идеале нужно смотреть, не использует ли драйвер кто-то ещё и останавливать его только если наш скрипт "последний". Долгие упорные попытки получить количество открытых ссылок на виртуальный файл драйвера ни к чему не привели (я получал только количество ссылок в рамках своего процесса). Причём сама система точно умеет это делать - при остановке драйвера с открытым файлом, он остаётся висеть в "Pending Stop". Если у кого есть идеи - буду благодарен.
В конечном итоге я "подсмотрел", как это делают другие программы. Выяснилось, что большинство либо не заморачиваются, либо просто ищут запущенные процессы с тем же именем. Но одна из исследованных программ имела кардинально другой подход, который я себе и перенял. Вместо того, чтобы переживать по количеству ссылок на файл, просто на каждый запрос открываем и закрываем файл! А если файла нет, значит кто-то остановил драйвер и пытаемся его перезапустить:
А дальше просто реверсим драйвер и реализуем все нужные нам вызовы:

Легко и непринуждённо в пару команд читаем физическую память
FIR фильтр
Фильтры являются одной из важнейших областей в цифровой обработке сигналов. И, конечно же, библиотека IPP имеет реализацию большинства классов этих фильтров, в том числе и FIR (finite impulse response) фильтра. Подробное описание FIR фильтров можно найти в многочисленной литературе или в википедии, но если кратко, в нескольких словах, то FIR фильтр просто умножает несколько предыдущих отсчетов и текущий отсчет входного дискретного сигнала на соответствующие им коэффициенты, складывает эти произведения и получает текущий отсчет выходного сигнала. Или чуть более формально: FIR фильтр осуществляет преобразование входного вектора X длиной N отсчетов в выходной вектор Y длиной тоже N отсчетов посредством умножения K отсчетов входного вектора на соответствующие им K коэффициентов H и последующим суммированием. Количество коэффициентов K называется порядком фильтра.

Рис. 1. FIR фильтр
Здесь:
tapsLen — это порядок фильтра,
numIters — это длина вектора.
Рисунок взят из документации на IPP библиотеку, поэтому используется принятая в IPP терминология.
Визуально можно представить FIR фильтр следующим образом.

Рис. 2. FIR фильтр схематически
Как видим, здесь порядок фильтра K равен 4 и мы просто умножаем 4 коэффициента h фильтра на 4 отсчета вектора x, складываем и записываем сумму в один отсчет выходного вектора y. Отметим, что коэффициенты фильтра h[3],h[2],h[1],h[0] лежат в памяти в обратном порядке по отношению к x и y, в соответствии с общепринятой формулой на рис. 1
Прокси-драйвера
В итоге получается обходной манёвр – всё, что программе запрещено делать, разработчик вынес в драйвер, программа устанавливает драйвер в систему и уже через него программа делает, что хочет! Более того – выяснилось, что RW Everything далеко не единственная программа, которая так делает. Таких программ не просто много, они буквально повсюду. У меня возникло ощущение, что каждый уважающий себя производитель железа имеет подобный драйвер:
Софт для обновления BIOS (Asrock, Gigabyte, HP, Dell, AMI, Intel, Insyde…)
Софт для разгона и конфигурации железа (AMD, Intel, ASUS, ASRock, Gigabyte)
Софт для просмотра сведений о железе (CPU-Z, GPU-Z, AIDA64)
Софт для обновления PCI устройств (Nvidia, Asmedia)
Во многих из них практически та же самая модель поведения – драйвер получает команды по типу «считай-ка вот этот физический адрес», а основная логика – в пользовательском софте. Ниже в табличке я собрал некоторые прокси-драйвера и их возможности:

Результаты краткого анализа пары десятков драйверов. Могут быть ошибки!
Mem – чтение / запись физической памяти
PCI – чтение / запись PCI Configuration Space
I/O – чтение / запись портов I/O
Alloc – аллокация и освобождение физической памяти
Map – прямая трансляция физического адреса в вирутальный
MSR – чтение / запись x86 MSR (Model Specific Register)
Жёлтым обозначены возможности, которых явно нет, но их можно использовать через другие (чтение или маппинг памяти). Мой фаворит из этого списка – AsrDrv101 от ASRock. Он устроен наиболее просто и обладает просто огромным списком возможностей, включая даже функцию поиска шаблона по физической памяти (!!)
Неполный перечень возможностей AsrDrv101
Чтение / запись RAM
Чтение / запись IO
Чтение / запись PCI Configuration Space
Чтение / запись MSR (Model-Specific Register)
Чтение / запись CR (Control Register)
Чтение TSC (Time Stamp Counter)
Чтение PMC (Performance Monitoring Counter)
Alloc / Free физической памяти
Поиск по физической памяти
Самое нехорошее в такой ситуации - если подобный драйвер остаётся запущенным на ПК пользователя, для обращения к нему не нужно даже прав администратора! То есть любая программа с правами пользователя сможет читать и писать физическую память - хоть пароли красть, хоть ядро пропатчить. Именно на это уже ругались другие исследователи. Представьте, что висящая в фоне софтина, красиво моргающая светодиодиками на матплате, открывает доступ ко всей вашей системе. Или вирусы намеренно ставят подобный драйвер, чтобы закрепиться в системе. Впрочем, любой мощный инструмент можно в нехороших целях использовать.
Линия задержки
Поскольку FIR фильтр это обычная свертка, то для получения выходного вектора длиной в N отсчетов, необходимо N+K-1 входных отсчетов, где K длина ядра. Первые K-1 отсчетов будем далее называть «линией задержки» (delay line). На рис. 2 они нумеруются x[-3], x[-2], x[-1]. Данные, подаваемые в функцию, могут быть довольно большого объема, вследствие чего быть разбитыми на отдельные последовательно обрабатываемые блоки. К примеру, если это аудио сигнал, то он может буферизоваться операционной системой, если это данные от внешнего устройства, то они могут приходить порциями по линии связи. А также данные могут обрабатываться через буфер и в самом приложении, поскольку заранее неизвестен объем возможных данных. В этом случае рабочий буфер выделяется некой фиксированной длины к примеру так, чтобы они укладывались в кэш некоторого уровня и тогда все данные проходят через этот буфер порциями. Во всех таких случаях линия задержки очень полезна. Она помогает очень просто «склеить» данные в один непрерывный поток таким образом, что не возникает краевого эффекта разбиения данных на блоки.
IPP API
- была бы возможность обработки вектора последовательными блоками;
- отсутствовало бы скрытое выделение памяти;
- поддерживалась бы обработка вектора в разных потоках;
- был допустим in-place режим т.е входной вектор является одновременно и выходным.
Этот API следует стандартной схеме, применяемой в IPP. Вначале с помощью функции ippsFIRSRGetSize запрашивается размер памяти под контекст функции и рабочий буфер. Далее вызывается функция ippsFIRSRInit, в которую подаются коэффициенты фильтра. Эта функция инициализирует внутренние таблицы данных в структуре pSpec, ускоряющие работу процессирующей функции ippsFIRSR. Содержимое данной структуры не изменяется в процессе работы функции, что отражено в ее названии Spec, поэтому может быть использовано одновременно несколькими потоками, для более эффективного использования памяти. Параметр pBuf это рабочий и модицифируемый буфер функции, поэтому для каждого потока должен быть выделен свой рабочий буфер.
Суффикс SR означает single rate, и используется для единообразия c MR (multi rate) фильтрами, описание которых может являться целой отдельной статьей. Параметр numIters также позаимствован из MR фильтров и в нашем случае означает просто длину вектора.
На начало обрабатываемого блока x[0] указывает параметр pSrc.
Теперь рассмотрим какой смысл вкладывается в параметры pDlySrc и pDlyDst.
Такой механизм из двух линий задержки позволяет распараллелить обработку вектора, даже в случае in-place режима, т.е. когда вектор перезаписывается. Для этого достаточно предварительно скопировать «хвосты» блоков в отдельные буферы и подать их в качестве входной линии в каждый поток. Пример кода использованого в статье приведен в конце единым листингом.
Пример использования Lowpass IPP FIR фильтра.
Рассмотрим, например, как использовать IPP FIR фильтр для того чтобы оставить лишь низкочастотную составляющюю сигнала.
Для генерации исходного нефильтрованного сигнала мы будем использовать специальную IPP функцию Jaehne, реализующую формулу
pDst[n] = magn * sin ((0.5πn2)/len), 0 ≤ n < len
Эта функция является рабочей лошадкой, на которой тестируются многие IPP функции. Сгенерированный сигнал будем записывать в простейший .csv файл и рисовать картинки в Excel. Выглядит исходный сигнал следующим образом.
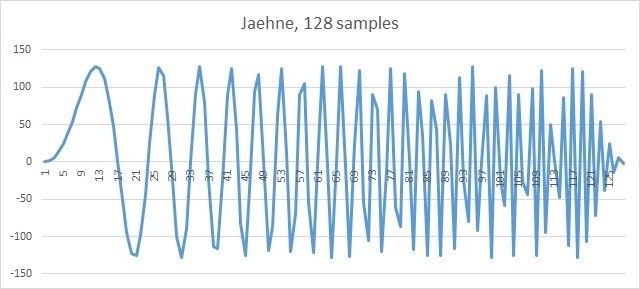
Рис. 4. 128 Отсчетов сигнала Jaehne
Рассмотрим к примеру фильтр порядка 31. Для генерации коэффициентов используется IPP функция ippsFIRGenLowpass_64f. Функция вычисляет коэффициенты только в double, поэтому они преобразуются в float. См. код функции firgenlowpass() в приложении. После вызова этой функции вычисляется размер буфера, инициализация и вызов основной функции ippsFIRSR, а также измеряется ее производительность.
После применения lowpass фильтра в сигнале осталась низкочастотная составляющая. Отметим, что фаза сдвинута, но это уже вытекает из свойства самих FIR фильтров и не относится к IPP библиотеке.
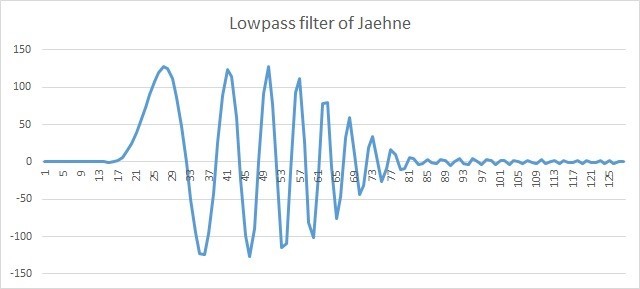
Рис. 5. 128 Отсчетов сигнала Jaehne после lowpass фильтра
На этих рисунках FIR фильтр обрабатывает 128 отсчетов, при этом 30 отсчетов входной линии задержки мы полагаем равными 0, указывая pDlySrc = NULL. Выходная линия нам также не нужна pDlyDst = NULL.
Как создается драйвер устройства

Для каждого устройства существует свой строгий порядок выполнения команд, называемой «инструкцией». Не зная инструкцию к устройству, невозможно написать для него драйвер, так как низкоуровневые машинные команды являются двоичным кодом (прерываниями) которые на выходе отправляют в драйвер результат, полученный в ходе выполнения этой самой инструкции.
При создании драйвера для Линукса, вам необходимо знать не только тип шины и ее адрес, но и схематику самого устройства, а также весь набор электрических прерываний, в ходе исполнения которых устройство отдает результат драйверу.
Написание любого драйвера начинается с его «скелета» — то есть самых основных команд вроде «включения/выключения» и заканчивая специфическими для данного устройства параметрами.
Выводы?
Как видите, имея права администратора, можно делать с компьютером практически что угодно. Будьте внимательны - установка утилит от производителя вашего железа может обернуться дырой в системе. Ну а желающие поэкспериментировать со своим ПК - добро пожаловать на низкий уровень! Наработки выложил на GitHub. Осторожно, бездумное использование чревато BSODами.
В Windows есть фича "Изоляция ядра", которая включает I/O MMU, защищает от DMA атак и так далее (кстати об этом - в следующих сериях)

Так вот, при включении этой опции, некоторые драйвера (в том числе RW Everything и китайско-подписанный chipsec_hlpr) перестают запускаться:
Производительность многопоточной версии
Библиотка IPP имеет в своем названии слово производительность (performance), которая и ставится во главу угла. Поэтому измеряем производительность ippFIRSR функции на процессоре с поддержкой AVX2. После чего реализуем следующий многопоточный код, использующий OpenMP померяем его и после сведем результаты измерений в один график.
API FIR фильтров разрабатывался таким образом чтобы разбиение вектора на несколько потоков было простым и логичным так, как это показано на рисунке:

Рис. 6. Разбиение исходного вектора между потоками
Подразумевается следующий способ разбиения вектора между потоками, см. функцию fir_omp.
Рассмотрим что делает этот код. Итак, к нам поступила очередная порция сигнала x[0],…,x[N-1], которую нужно обработать фильтром, а вместе с ней указатель на входную и выходную линии задержки или другими словами «хвост» предыдущей порции и буфер, куда следует поместить “хвост” текущей порции. Мы хотим ускорить процесс фильтрации и разбиваем обработку этой порции на T=NTHREADS блоков, соответствующее числу потоков. Для этого нам надо просто правильно указать входные и выходные линии, а также выделить свой рабочий буфер для каждого потока.
Для 0-ого потока входная линия задержки при вызове ippsFIRSR это тот самый «хвост» предыдущей порции, а для всех остальных в качестве входной линии подается указатель на блок смещенный на order-1 элементов. И только последний поток записывает «хвост» порции.
Приведенный подход подразумевает что результирующий вектор записывается по другому адресу чем исходный вектор, в случае же если данные будут перезаписаны, то линии задержки следует предварительно скопировать в отдельные буферы.
На графике показана производительность однопоточной и многопоточной версии для 4-х потоков фильтра 31 порядка на процессоре с поддержкой AVX2 инструкций Intel® Core(TM) i7-4770K 3.50Ghz. Для FIR фильтров используется единица измерения cpMAC, т.е. количество тактов на операцию Умножить+Сложить
cpMAC = (время выполнения функции) / (длина вектора * порядок фильтра)
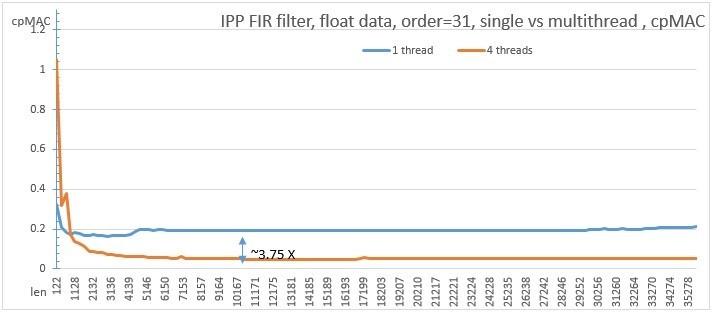
Рис. 7. Сравнение производительности однопоточной и многопоточной версий FIR фильтра
Видно, что функция очень хорошо масштабируется, и многопоточная версия работает приблизительно в 3.7 раз быстрее на достаточно длинных векторах, чем однопоточная, что очень хорошо соответствует 4 потокам. Критерий переключения между одно- и многопоточной версиями теперь, с новым API, можно подобрать экспериментально под конкретную машину, в отличие от предыдущего, где критерий был жестко зашит в код и функция параллелилась изнутри.
Читаем BIOS
В качестве примера применения нашего "тулкита", попробуем набросать скрипт чтения BIOS. Он должен быть "замаплен" где-то в конце 32-битного адресного пространства, потому что компьютер начинает его исполнение с адреса 0xFFFFFFF0. Обычно в ПК стоит флеш-память объёмом 4-16 МБ, поэтому будем "сканировать" адресное пространство с адреса 0xFF000000, как только найдём что-нибудь непустое, будем считать, что тут начался BIOS:
В результате получаем:

Вот так в 10 строчек мы считали BIOS
Но подождите-ка, получилось всего 6 мегабайт, а должно быть 4 или 8 что-то не сходится. А вот так, у чипсетов Intel в адресное пространство мапится не вся флешка BIOS, а только один её регион. И чтобы считать всё остальное, нужно уже использовать SPI интерфейс.
Не беда, лезем в даташит, выясняем, что SPI интерфейс висит на PCI Express:

И для его использования, нужно взаимодействовать с регистрами в BAR0 MMIO по алгоритму:
Задать адрес для чтения в BIOS_FADDR
Задать параметры команды в BIOS_HSFTS_CTL
Прочитать данные из BIOS_FDATA
Пилим новый скрипт для чтения через чипсет:
Исполняем и вуаля - в 20 строчек кода считаны все 8 МБ флешки BIOS! (нюанс - в зависимости от настроек, регион ME может быть недоступен для чтения).
Точно так же можно делать всё, что заблагорассудится - делать снифер USB пакетов, посылать произвольные ATA команды диску, повышать частоту процессора и переключать видеокарты. И это всё - с обычными правами администратора:

Немного помучившись, получаем ответ от SSD на команду идентификации
А если написать свой драйвер?
Некоторые из вас наверняка уже подумали - зачем так изворачиваться, реверсить чужие драйвера, если можно написать свой? И я о таком думал. Более того, есть Open-Source проект chipsec, в котором подобный драйвер уже разработан.
Зайдя на страницу с кодом драйвера, вы сразу наткнетесь на предупреждение:
В этом предупреждении как раз и описываются все опасности, о которых я рассказывал в начале статьи - инструмент мощный и опасный, следует использовать только в Windows режиме Test Mode, и ни в коем случае не подписывать. Да, без специальной подписи на обычной системе просто так запустить драйвер не получится. Поэтому в примере выше мы и использовали заранее подписанный драйвер от ASRock.
Если кто сильно захочет подписать собственный драйвер - понадобится регистрировать собственную компанию и платить Microsoft. Насколько я нагуглил, физическим лицам такое развлечение недоступно.
Точнее я так думал, до вот этой статьи, глаз зацепился за крайне интересный абзац:
У меня под рукой нет Windows DDK, так что я взял 64-битный vfd.sys , скомпилированный неким critical0, и попросил dartraiden подписать его «древне-китайским способом». Такой драйвер успешно загружается и работает, если vfdwin запущена с правами администратора
Драйвер из статьи действительно подписан, и действительно неким китайским ключом:

Как оказалось, сведения о подписи можно просто посмотреть в свойствах.. А я в HEX изучал
Немного поиска этого имени в гугле, и я натыкаюсь на вот эту ссылку, откуда узнаю, что:
есть давно утёкшие и отозванные ключи для подписи драйверов
если ими подписать драйвер - он прекрасно принимается системой
малварщики по всему миру используют это для создания вирусни
Основная загвоздка - заставить майкрософтский SignTool подписать драйвер истёкшим ключом, но для этого даже нашёлся проект на GitHub. Более того, я нашёл даже проект на GitHub для другой утилиты подписи драйверов от TrustAsia, с помощью которого можно подставить для подписи вообще любую дату.
Несколько минут мучений с гугл-переводчиком на телефоне, и мне удалось разобраться в этой утилите и подписать драйвер одним из утекших ключей (который довольно легко отыскался в китайском поисковике):

И в самом деле, китайская азбука
И точно так же, как и AsrDrv101, драйвер удалось без проблем запустить!

А вот и наш драйвер запустился
Из чего делаю вывод, что старая идея с написанием своего драйвера вполне себе годная. Как раз не хватает функции маппинга памяти. Но да ладно, оставлю как TODO.
Сравнение direct и FFT реализаций
В цифровой обработке сигналов широко используется взаимное соответствие свертки и преобразования Фурье.
IPP FIR фильтры помимо прямой реализации имеют и реализацию через FFT, причем получаемые при этом cpMAC иногда превосходят теоретически возможную для данного cpu и прямого алгоритма, о чем иногда пишут пользователи на форумах, справедливо полагая, что вычисления идут через FFT.
Теперь для того, чтобы указать какой тип алгоритма использовать, следует использовать одно из значений параметра algType — ippAlgDirect ippAlgFFT, ippAlgAuto. Последний параметр означает, что функция выбирает алгоритм по фиксированному критерию для используемого cpu, а он не всегда может быть оптимальным.
Рассмотрим производительность на том же CPU фильтра разных порядков для длины вектора в 1024 и 128 отсчетов используя прямой алгоритм и FFT реализацию.
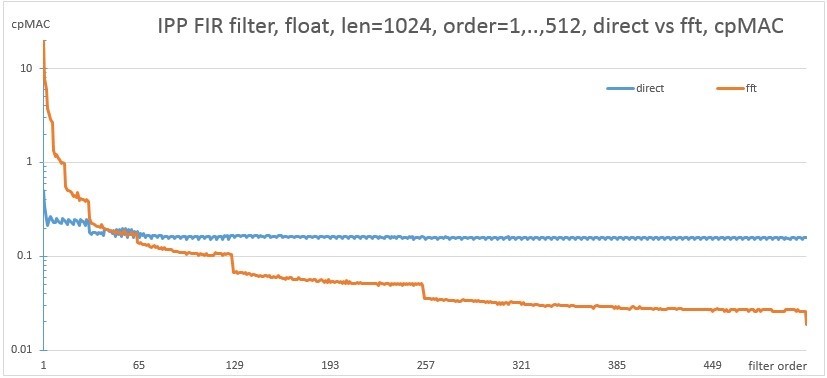
Рис. 8. Сравнение производительности direct и fft реализаций для длины в 1024 отсчета
Рис. 9. Сравнение производительности direct и fft реализаций для длины в 128 отсчетов
Для FFT реализации характерны ступеньки. Это объясняется тем, что для фильтров нескольких близких порядков используется FFT одного порядка, а когда переходит переход на следующий порядок FFT, то производительность изменяется. Для достижения максимальной производительности следует использовать тот алгоритм, который лежит ниже на графике. Предлагаемый API позволяет реализовать пример, который будет запускать на измерение на конкретной машине обе версии алгоритма, и выбирать лучшую из них. Картинка буде выглядеть примерно следующим образом. На этой картинке нарисовано двумерное пространство размером 1024x1024, где по оси X порядок фильтра, а по оси Y длина вектора. Зеленый цвет означает что fft алгоритм работает быстрее прямой версии. Характерные прямые линии внизу рисунка соответствуют рис. 9, где fft вариант работает некоторое время медленнее, после перехода на следующий порядок.
Рис. 10. Сравнение производительности direct и fft реализации IPP FIR float фильтра в пространстве filter order X vector length размерностью 1024 x 1024
Видно, что рисунок довольно сложный и его не так то просто интерполировать внутри IPP под произвольную платформу. К тому же, это рисунок может изменяться на конкретной машине. Помимо выбора между direct и fft кодом, можно добавить еще одну размерность в виде количества потоков и таким образом получится уже многослойная картинка. Предлагаемый API опять же позволяет позволяет выбрать оптимальный для данной платформы вариант и в этом случае.
Как работает драйвер и для чего он нужен?
Основное назначение драйвера – это упрощение процесса программирования работы с устройством.
Он служит «переводчиком» между хардовым (железным) интерфейсом и приложениями или операционными системами, которые их используют. Разработчики могут писать, с помощью драйверов, высокоуровневые приложения и программы не вдаваясь в подробности низкоуровневого функционала каждого из необходимых устройств в отдельности.
Как уже упоминалось, драйвер специфичен для каждого устройства. Он «понимает» все операции, которые устройство может выполнять, а также протокол, с помощью которого происходит взаимодействие между софтовой и железной частью. И, естественно, управляется операционной системой, в которой выполняет конкретной приложение либо отдельная функция самой ОС («печать с помощью принтера»).
Если вы хотите отформатировать жесткий диск, то, упрощенно, этот процесс выглядит следующим образом и имеет определенную последовательность: (1) сначала ОС отправляет команду в драйвер устройства используя команду, которую понимает и драйвер, и операционная система. (2) После этого драйвер конкретного устройства переводит команду в формат, который понимает уже только устройство. (3) Жесткий диск форматирует себя, возвращает результат драйверу, который уже впоследствии переводит эту команду на «язык» операционной системы и выдает результат её пользователю (4).
В чём суть, капитан?
В архитектуре x86 есть понятие «колец защиты» («Ring») – режимов работы процессора. Чем ниже номер текущего режима, тем больше возможностей доступно исполняемому коду. Самым ограниченным «кольцом» является «Ring 3», самым привилегированным – «Ring -2» (режим SMM). Исторически сложилось, что все пользовательские программы работают в режиме «Ring 3», а ядро ОС – в «Ring 0»:

Режимы работы x86 процессора
В «Ring 3» программам запрещены потенциально опасные действия, такие как доступ к I/O портам и физической памяти. По логике разработчиков, настолько низкоуровневый доступ обычным программам не нужен. Доступ к этим возможностям имеют только операционная система и её компоненты (службы и драйверы). И всё бы ничего, но однажды я наткнулся на программу RW Everything:

RW Everything действительно читает и пишет практически всё
Эта программа была буквально напичкана именно теми функциями, которые обычно запрещаются программам «Ring 3» - полный доступ к физической памяти, I/O портам, конфигурационному пространству PCI (и многое другое). Естественно, мне стало интересно, как это работает. И выяснилось, что RW Everything устанавливает в систему прокси-драйвер:

Смотрим последний установленный драйвер через OSR Driver Loader
Заключение
Введенный в IPP 9.0 API FIR фильтров позволяет использовать их в приложениях еще более эффективно, выбирая оптимальный вариант между прямым и fft алгоритмами, а также паралеллить каждый из выбранных вариантов. К тому же библиотека IPP абсолютно бесплатна и доступна для скачивания по этой ссылке Intel Performance Primitives (IPP).
Драйвер устройства и с чем его едят

Как уважаемый хабрапользователь наверняка знает, «драйвер устройства» — это компьютерная программа управляющая строго определенным типом устройства, подключенным к или входящим в состав любого настольного или переносного компьютера.
Основная задача любого драйвера – это предоставление софтового интерфейса для управления устройством, с помощью которого операционная система и другие компьютерные программы получают доступ к функциям данного устройства, «не зная» как конкретно оно используется и работает.
Обычно драйвер общается с устройством через шину или коммуникационную подсистему, к которой подключено непосредственное устройство. Когда программа вызывает процедуру (очередность операций) драйвера – он направляет команды на само устройство. Как только устройство выполнило процедуру («рутину»), данные посылаются обратно в драйвер и уже оттуда в ОС.
Любой драйвер является зависимым от самого устройства и специфичен для каждой операционной системы. Обычно драйверы предоставляют схему прерывания для обработки асинхронных процедур в интерфейсе, зависимом от времени ее исполнения.
Любая операционная система обладает «картой устройств» (которую мы видим в диспетчере устройств), для каждого из которых необходим специфический драйвер. Исключения составляют лишь центральный процессор и оперативная память, которой управляет непосредственно ОС. Для всего остального нужен драйвер, который переводит команды операционной системы в последовательность прерываний – пресловутый «двоичный код».
Windows: достучаться до железа

Меня всегда интересовало низкоуровневое программирование – общаться напрямую с оборудованием, жонглировать регистрами, детально разбираться как что устроено. Увы, современные операционные системы максимально изолируют железо от пользователя, и просто так в физическую память или регистры устройств что-то записать нельзя. Точнее я так думал, а на самом деле оказалось, что чуть ли не каждый производитель железа так делает!
И чем драйвер не является
Часто драйвер устройства сравнивается с другими программами, выполняющими роль «посредника» между софтом и/или железом. Для того, чтобы расставить точки над «i», уточняем:
- Драйвер не является интерпретатором, так как не исполняется напрямую в софтовом слое приложения или операционной системы.
- Драйвер не является компилятором, так как не переводит команды из одного софтового слоя в другой, такой же.
Ну и на правах рекламы – вы всегда знаете, где скачать новейшие драйвера для любых устройств под ОС Windows.
Читайте также: