
Control plane kubernetes что это
Обновлено: 02.07.2024

Kubernetes отличная платформа как для оркестрации контейнеров так и для всего остального. За последнее время Kubernetes ушёл далеко вперёд как по части функциональности так и по вопросам безопасности и отказоустойчивости. Архитектура Kubernetes позволяет с лёгкостью переживать сбои различного характера и всегда оставаться на плаву.
Сегодня мы будем ломать кластер, удалять сертификаты, вживую реджойнить ноды и всё это, по возможности, без даунтайма для уже запущенных сервисов.

Итак приступим. Основной control-plane Kubernetes состоит всего из нескольких компонентов:
etcd - используется в качестве базы данных
kube-apiserver - API и сердце нашего кластера
kube-controller-manager - производит операции над Kubernetes-ресурсами
kube-scheduler - основной шедуллер
kubelet'ы - которые непосредственно и запускают контейнеры на хостах
Каждый из этих компонентов защищён набором TLS-сертификатов, клиентских и серверных, которые используются для аутентификации и авторизации компонентов между собой. Они не хранятся где-либо в базе данных Kubernetes, за исключением определенных случаев, а представлены в виде обычных файлов:
Сами компоненты описаны и запускаются на мастерах как static pods из директории /etc/kubernetes/manifests/
На этом месте не будем останавливаться подробно, т.к. это тема для отдельной статьи. В данном случае нас в первую очередь интересует как из этого всего добра получить рабочий кластер. Но для начала давайте немного абстрагируемся, и представим что у нас есть вышеперечисленные компоненты Kubernetes, которые как-то коммуницируют между собой.
Основная схема выглядит примерно так:

(стрелочки указывают на связи клиент --> сервер)
Для коммуникации им нужны TLS-сертификаты, которые в принципе можно вынести на отдельный уровень абстракции и полностью довериться вашему инструменту деплоя, будь-то kubeadm, kubespray или что либо ещё. В этой статье мы разберём kubeadm т.к. это наиболее стандартный инструмент для развёртывания Kubernetes, а также он часто используется в составе других решений.
Допустим, у нас уже есть задеплоенный кластер. Начнём с самого интересного:
На мастерах данная директория содержит:
Набор сертификатов и CA для etcd (в /etc/kubernetes/pki/etcd )
Набор сертификатов и CA для Kubernetes (в /etc/kubernetes/pki )
Kubeconfig для cluster-admin, kube-controller-manager, kube-scheduler и kubelet (каждый из них также имеет закодированный в base64 CA-сертификат для нашего кластера /etc/kubernetes/*.conf )
Набор статик-манифестов для etcd, kube-apiserver, kube-scheduler и kube-controller-manager (в /etc/kubernetes/manifests )
Предположим, что мы потеряли всё и сразу
Чиним control-plane
Чтобы не было недоразумений, давайте также убедимся что все наши control-plane поды также остановлены:
Примечание: kubeadm по умолчанию не перезаписывает уже существующие сертификаты и кубеконфиги, для того чтобы их перевыпустить их необходимо сначала удалить вручную.
Давайте начнём с восстановления etcd, так как если у нас был кворум (3 и более мастер-нод) etcd-кластер не запустится без присутствия большинства из них.
Команда выше сгенерит новый CA для нашего etcd-кластера. Так как все остальные сертификаты должны быть им подписаны, скопируем его вместе с приватным ключом на остальные мастер-ноды:
Теперь перегенерим остальные etcd-сертификаты и static-манифесты для него на всех control-plane нодах:
На этом этапе у нас уже должен подняться работоспособный etcd-кластер:
Теперь давайте проделаем тоже самое, но для для Kubernetes, на одной из master-нод выполним:
Вышеописанные команды сгенерируют все SSL-сертификаты для нашего Kubernetes-кластера, а также статик под манифесты и кубеконфиги для сервисов Kubernetes.
Если вы используете kubeadm для джойна кубелетов, вам также потребуется обновить конфиг cluster-info в kube-public неймспейсе т.к. он до сих пор содержит хэш вашего старого CA.
Так как все сертификаты на других инстансах также должны быть подписаны одним CA, скопируем его на остальные control-plane ноды, и повторим вышеописанные команды на каждой из них.
Кстати, в качестве альтернативы ручного копирования сертификатов теперь вы можете использовать интерфейс Kubernetes, например следующая команда:
Зашифрует и загрузит сертификаты в Kubernetes на 2 часа, таким образом вы сможете сделать реджойн мастеров следующим образом:
Стоит заметить, что в API Kubernetes есть ещё один конфиг, который хранит CA сертификат для front-proxy client, он используется для аутентификации запросов от apiserver в вебхуках и прочих aggregation layer сервисах. К счастью kube-apiserver обновляет его автоматически.
Однако возможно вы захотите почистить его от старых сертификатов вручную:
В любом случае на данном этапе мы уже имеем полностью рабочий control-plane.
Чиним ServiceAccounts
Есть ещё один момент. Так как мы потеряли /etc/kubernetes/pki/sa.key - это тот самый ключ которым были подписаны jwt-токены для всех наших ServiceAccounts, то мы должны пересоздать токены для каждого из них.
Сделать это можно достаточно просто, удалив поле token изо всех секреты типа kubernetes.io/service-account-token :
После чего kube-controller-manager автоматически сгенерирует новые токены, подписаные новым ключом.
К сожалению далеко не все микросервисы умеют на лету перечитывать токен и скорее всего вам потребуется вручную перезапустить контейнеры, где они используются:
Например эта команда сгенерирует список команд для удаления всех подов использующих недефолтный serviceAccount. Рекомендую начать с неймспейса kube-system , т.к. там установлены kube-proxy и CNI-плагин, жизненно необходимые для настройки коммуникации ваших микросервисов.
На этом восстановление кластера можно считать оконченным. Спасибо за внимание! В следующей статье мы подробнее рассмотрим бэкап и восстановление etcd-кластера.

Продолжаем знакомство с Kubernetes.
-
: управляется самим Амазоном, состоит из трёх EC2 в различных Availability Zones, управляются самим AWS : обычные ЕС2 в пользовательской VPC, управляются пользователем


Для сети используется плагин amazon-vpc-cni-k8s, который позволяет подам кластера использовать ENI (Elastic Network Interface) и сетевое пространство VPC и подсетей в AWS.

Для авториазации используется плагин aws-iam-authenticator, который позволяет выполнять авторизацию кластера через AWS IAM роли и политики (см. Managing Users or IAM Roles for your Cluster)
AWS также сам выполняется минорные обновления, например с 1.11.5 to 1.11.8, но мажорные апгрейды на совести пользователя.
Подготовка AWS
Для создания кластера нам нужно поднять свою VPC, создать сети, настроить роутинг, и добавить IAM роль, которая будет использоваться кластером для авторизации.
IAM роль
Переходим в IAM, создаём новую роль, тип EKS:

Permissions AWS выберет сам:



SecurityGroup
Переходим в SecurityGroups, создаём SG для кластера:



Internet Gateway
Создаём IGW, через который будет ходить трафик из публичных подсетей:

Подключаем его к VPC:


Subnets
Создаём первую публичную сеть с блоком 10.0.0.0/18 (всего-то 16384 адресов):




И аналогично добавляем две приватные подсети:


NAT Gateway

(раньше не было кнопки Create EIP 😐 )
Сразу настраиваем маршрутизацию:

Route tables
Public route table
Создаём для публичной:



Private route table
Аналогично создаём вторую таблицу, для приватных подсетей:

Добавляем маршрут к 0.0.0.0/0 через NAT GW:


К приватным подсетям подключаем, соответственно, приватную RTB, с маршрутами через NAT:


Проверка


] $ ssh -i setevoy-testing-eu-west-2.pem ubuntu@35.178.171.252 'ping -c 1 8.8.8.8'
1 packets transmitted, 1 received, 0% packet loss, time 0msДобавляем ещё один ЕС2, в приватной подсети:

И пингуем его с первого инстанса:
] $ ssh -i setevoy-testing-eu-west-2.pem ubuntu@35.178.171.252 'ping -c 1 10.0.184.21'
64 bytes from 10.0.184.21: icmp_seq=1 ttl=64 time=0.357 ms 1 packets transmitted, 1 received, 0% packet loss, time 0msСоздание Control Plane

Задаём имя, выбираем IAM-роль, созданную в самом начале:


Можно сразу тут включить и логи:


Создание Worker Nodes
Переходим в CloudFormation > Create stack:


Находим AssociatePublicIpAddress , меняем значеине с true на false:

Кликаем Create stack:


Выбираем NodeImageId , а зависимости от зоны (см. актуальные AM ID в документации):
| Region | Amazon EKS-optimized AMI | with GPU support |
|---|---|---|
| US East (Ohio) ( us-east-2 ) | ami-0485258c2d1c3608f | ami-0ccac9d9b57864000 |
| US East (N. Virginia) ( us-east-1 ) | ami-0f2e8e5663e16b436 | ami-0017d945a10387606 |
| US West (Oregon) ( us-west-2 ) | ami-03a55127c613349a7 | ami-08335952e837d087b |
| Asia Pacific (Hong Kong) ( ap-east-1 ) | ami-032850771ac6f8ae2 | N/A* |
| Asia Pacific (Mumbai) ( ap-south-1 ) | ami-0a9b1c1807b1a40ab | ami-005b754faac73f0cc |
| Asia Pacific (Tokyo) ( ap-northeast-1 ) | ami-0fde798d17145fae1 | ami-04cf69bbd6c0fae0b |
| Asia Pacific (Seoul) ( ap-northeast-2 ) | ami-07fd7609df6c8e39b | ami-0730e699ed0118737 |
| Asia Pacific (Singapore) ( ap-southeast-1 ) | ami-0361e14efd56a71c7 | ami-07be5e97a529cd146 |
| Asia Pacific (Sydney) ( ap-southeast-2 ) | ami-0237d87bc27daba65 | ami-0a2f4c3aeb596aa7e |
| EU (Frankfurt) ( eu-central-1 ) | ami-0b7127e7a2a38802a | ami-0fbbd205f797ecccd |
| EU (Ireland) ( eu-west-1 ) | ami-00ac2e6b3cb38a9b9 | ami-0f9571a3e65dc4e20 |
| EU (London) ( eu-west-2 ) | ami-0147919d2ff9a6ad5 | ami-032348bd69c5dd665 |
| EU (Paris) ( eu-west-3 ) | ami-0537ee9329c1628a2 | ami-053962359d6859fec |
| EU (Stockholm) ( eu-north-1 ) | ami-0fd05922165907b85 | ami-0641def7f02a4cac5 |

Кликаем Next, на следующей странице можно ничего не менять, и запускаем создание стека:

Установка kubectl
На рабочую машину загружаем исполняемый файл:
] $ chmod +x kubectl
] $ sudo mv kubectl /usr/local/bin/
] $ kubectl version --short --client
] $ aws eks --region eu-west-2 --profile arseniy update-kubeconfig --name eks-cluster-manual
Added new context arn:aws:eks:eu-west-2:534***385:cluster/eks-cluster-manual to /home/setevoy/.kube/configДобавляем алиас для удобства:
AWS authenticator

Загружаем AWS authenticator:
Переходим в IAM > Roles, находим ARN (Amazon Resource Name) роли (NodeInstanceRole) (или находим в Outputs CloudFormation стека для worker nodes):


Редактируем aws-auth-cm.yaml , задаём rolearn :

/Temp] $ kk apply -f aws-auth-cm.yaml
/Temp] $ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIMEНоды появились, всё отлично.
Web-app && LoadBalancer
/Temp] $ kk apply -f eks-cluster-manual-elb-nginx.yml
/Temp] $ kk get svc
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES Annotations: kubectl.kubernetes.io/last-applied-configuration: <"apiVersion":"v1","data":<"mapRoles":"- rolearn: arn:aws:iam::534***385:role/eks-cluster-manual-workers-stack-NodeInstanceRole-12DRN98. - rolearn: arn:aws:iam::534***385:role/eks-cluster-manual-workers-stack-NodeInstanceRole-12DRN987QYB34LoadBalancer в самом AWS (потребуется минут 5, что бы завелись поды и инстансы подключились к ELB):
Пришла пора и нам разбивать этот монолит на микросервисы, для управления которыми будет использоваться Kubernetes (AWS EKS).
Общая схема K8s кластера выглядит так:
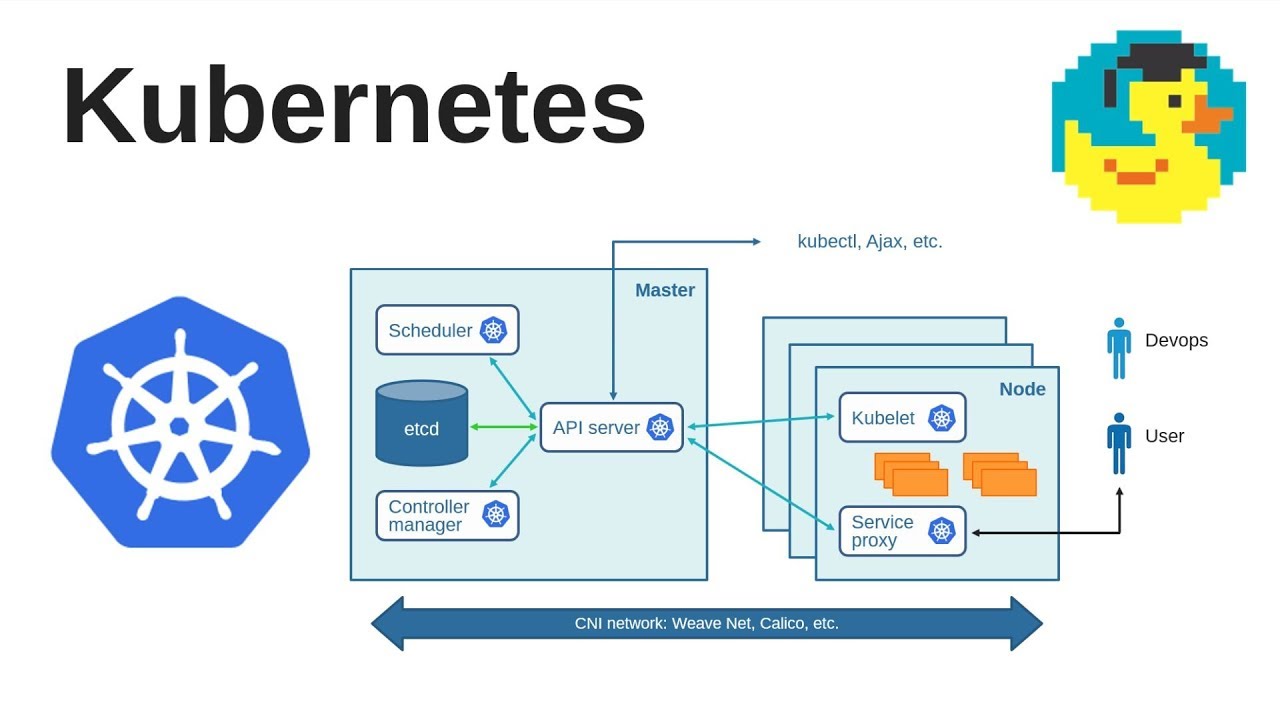
Или более простая схема:

Кластер состоит из одной или более Master Node, и одной или более Worker Node.
Master Node
Kubernetes core services aka Kubernetes Control Plane
На Master Node работают три основных компонента, которые обеспечивают работу всех компонентов системы:
Key:value хранилище, используемое Kubernetes для управления конфигурациями и service discovery.
Worker Node
На Worker Node-ах работают два компонента:
Взаимодействие компонтентов
- kubectl шлёт запрос к API-серверу
- API-сервер валидирует его, и передаёт в etcd
- etcd сообщает обратно API-серверу, что запрос принят и сохранён
- API-сервер обращается к kube-scheduler
- kube-scheduler определяет ноду(ы), на которой будет создан pod, и возвращает информацию обратно API-серверу
- API-сервер отправляет эти данные в etcd
- etcd сообщает обратно API-серверу, что запрос принят и сохранён
- API-сервер обращается к kubelet на соответствующей ноде(ам)
- kubelet обращается к Docker демону (или другому container runtime) через его API через сокет Docker-демона на ноде с задачей запустить контейнер
- kubelet отправляет статус pod-а API-серверу
- API-сервер обновляет данные в etcd
Абстракции Kubernetes
Соответственно, в K8s имеется множество собственных объектов, являющихся абстрактными, или логическими, компонентами Kubernetes.
По сути своей, под является такой себе абстракцией виртуальной машины внутри Kunbernetes-кластера: у него есть свой приватный IP, имя хоста, общие данные на дисках (см. Volumes).

Такая группа нод (Replicated Pods) управляется контроллером (см. Controllers).
При этом сами контейнеры не являются объектами Kubernetes и не управляются им: Kubernetes управляет подами, но контейнеры внутри этого пода используют общее сетевое пространство имён, включая IP адреса и порты, и могут обращаться друг к другу через localhost (потому как под == логическая виртуальная машина).
Пример шаблона для создания пода может выглядеть так:
Services
Например, сервисы можно условно обозначить так:

ClusterIP
Является типом по-умолчанию.
NodePort
Этот тип открывает доступ к приложению, используя статический IP рабочей ноды кластера. Автоматически создаёт ClusterIP для приложения, на который будет роутиться трафик с NodePort .
There are a lot of useful links in this post, but keep in mind that fact, that Kubernetes evolves very quickly so any examples can become outdated in a few months.
In general, Kubernetes cluster components looks like next:
Or a bit more simple one:
The cluster itself consists of one or more Master Nodes and one or more Worker Nodes.
Master Node
Kubernetes core services aka Kubernetes Control Plane
On the Master Node, there are three main Kubernetes components which make the whole cluster working:
Is a key:value storage used by Kubernetes for service discovery and configuration management.
Worker Node
Components interaction
Example when a new Pod created:
- kubectl will send a request to the API server
- the API server will validate it and send to the etcd
- etcd will reply to the API that requests accepted and saved in a database
- the API server will talk to the kube-scheduler
- kube-scheduler will choose a Worker Node to create a new Pod and sends this information back to the API server
- the API server will send this information to the etcd
- etcd will reply it accepted and saved data
- the API server talks to the kubelet on a chosen Worker Node
- kubelet will talk to the Docker daemon (or another container runtime used) via its API to create a new container
- kubelet will send information about new Pod back to the API server
- the API server will update information in the etcd
Kubernetes abstractions
Inherently, Pod is kind of a virtual machine inside the Kubernetes cluster: it has own private IP, hostname, shared volumes etc (see. Volumes).
Such a nodes group called Replicated Pods and are managed by a dedicated controller (see Controllers).
Services
Services in the first turn are everything about networking in a Kubernetes cluster.
They can be displayed as the next:
Here is a user who connects to a frontend application via one Service, then this frontend talks to two backend applications using two additional Services, and backends communicates to a database service via other one Service.
ClusterIP
Is the default Service type.
NodePort
Also, automatically will create a ClusterIP service for the application to route traffic from the NodePort .
Чиним воркеры
Эта команда выведет список всех нод кластера, хотя сейчас все они будут в статусе NotReady :
Когда как мастера имеют доступ к CA и могут быть присоеденены локально:
То для джойна воркеров мы сгенерируем новый токен:
и на каждом из них выполним:
Внимание, удалять директорию /etc/kubernetes/pki/ на мастерах не нужно, так как она уже содержит все необходимые сертификаты.
Вышеописанная процедура переподключит все ваши kubelet'ы обратно к кластеру, при этом никак не повлияет на уже запущенные на них контейнеры. Однако если у вас в кластере много нод и вы сделаете это неодновременно, у вас может возникнуть ситуация когда controller-manager начнёт пересоздавать контейнеры с NotReady-нод и пытаться их запустить на живых нодах кластера.
Чтобы это предотвратить мы можем временно остановить controller-manager, на мастерах:
Последняя команда нужна просто для того, чтобы удостовериться что под с controller-manager действительно не запущен. Как только все ноды кластера будут присоединены мы можем сгенерировать static-manifest для controller-manager обратно.
Для этого на всех мастерах выполняем:
Учтите что делать это нужно на этапе когда вы уже сгенерировали join token, в противном случае операция подключения зависнет на попытке прочитать токен из cluster-info.
В случае если kubelet настроен на получение сертификата подписанного вашим CA (опция serverTLSBootstrap: true ), вам также потребуется заново подтвердить csr от ваших kubelet'ов:
Читайте также: