
Crossfire x16 x4 есть ли смысл
Обновлено: 07.07.2024
24 мая, в Москве, в самый разгар жаркой весны, сотрудники фирмы ATI провели конференцию, посвященную описанной в этой статье технологии, подробностям новой игровой приставки Xbox 360 и другим не менее полезным вещам. Было здорово, спасибо Николаю Радовскому и другим представителям компании за полезную информацию и очень компетентные ответы на вопросы!
А теперь, не мешкая, перейдем к сути статьи:
ATI CrossFire — так официально называется канадский ответ на NVIDIA SLI, о котором шептались и «подозревали» технологические форумы сети еще полгода назад. Есть ли отличия? Да, несомненно. Есть ли преимущества? Судя по всему, да, и весьма значительные. Через некоторое время мы опубликуем тесты и практические исследования аспектов качества, а пока исследуем теоретические и архитектурные стороны и попробуем спрогнозировать тенденции и результаты. Общая архитектура CrossFire
Основная цель технологии — организация совместной работы двух графических ускорителей над построением изображения. Причем, архитектура должна быть не только эффективной (высокий КПД, низкая стоимость дополнительных схем, доступность для простых частных покупателей и энтузиастов), но и удобной в использовании (совместимость с уже существующими программами и даже с уже существующими аппаратными решениями, прозрачность, простота и надежность). Требований очень много, и, забегая вперед, похвалим ATI за качественный и очень продуманный подход при решении этих задач. Итак, нам предложена вот такая архитектура:

Несколько ускорителей (в варианте для пользователей их два) формируют собственную часть изображения, и выводят её через TMDS трансмиттеры в общепринятом цифровом стандарте DVI. Затем информация попадает в «черный» (на схеме — красный) ящик под названием Composing Engine, устройство, которое собственно и осуществляет совмещение результатов работы ускорителей для получения финального изображения. На выходе из этого красного ящика — вновь стандартный цифровой DVI сигнал, но на этот раз — уже финального кадра, собранного из двух порций данных, рассчитанных обоими VPU. Для устранения проблем с синхронизацией, Composing Engine содержит собственную буферную память, что позволяет этому устройству накапливать данные асинхронно, и, затем, по мере готовности обоих ускорителей, формировать и выдавать результирующий кадр. Таким образом, четкая синхронизация работы VPU не требуется, достаточно двух фактов — каждый VPU должен знать, какую часть данных ему надо рассчитать, и каждый VPU должен закончить передачу рассчитанных данных в этот «красный ящик», Composing Engine. После этого будет осуществлена передача кадра на устройство вывода, в формате DVI или (если нам нужен аналоговый сигнал) на внешний графический DAC, преобразующий цифровой DVI поток в стандартный аналоговый VGA сигнал.
Основные алгоритмы взаимодействия ускорителей
-
Разделение экрана на несколько непересекающихся зон (Scissor, также известно как Slicing). Это решение используется в современной технологии NVIDIA SLI, и во многих специальных решениях, таких как симуляторы для обучения пилотов (несколько окон тренировочной установки, модели самолета), большие информационные мультиэкраны и т.д.
Для двух VPU будет происходить вертикальное разделение финального кадра на две зоны. Интересно, что граница зон не обязательно должна проходить по середине кадра и может выбираться динамически, исходя из сложности той или иной части изображения — грубо говоря, в верхней половине может оказаться меньше объектов, чем внизу (небо) и тогда один из ускорителей будет простаивать, что может быть скомпенсировано увеличением его зоны ответственности. Задача подобной динамической балансировки нетривиальна, и требует анализа сцены, что не всегда удобно. Этот метод хорош для сбалансированных по критерию геометрических вычислений / закраска приложений, так как в идеале (при правильном адаптивном делении кадра на зоны ответственности), позволит им поровну распределить и геометрическую и пиксельную нагрузку по двум ускорителям.
- Делит и геометрическую и пиксельную нагрузку
- Высокая степень асинхронности работы VPU
- Ускоритель полностью владеет своей подотчетной зоной изображения результата
- Требует балансировки на лету зон для равномерного распределения нагрузки
- Могут быть проблемы с AA на стыке зон
- Требует заметного вмешательства в драйвер и потому высока вероятность неожиданной и неверной работы некоторых приложений
- Делит пиксельную нагрузку ровно поровну
- Очень точная балансировка нагрузки между VPU
- Можно использовать для новых методик AA (SSAA)
- Прозрачен для приложений и почти не требует модификации драйверов, мала вероятность неверной работы приложений
- Не делит геометрическую нагрузку и потому требует существенного запаса в геометрической производительности
- Требует достаточно синхронной работы ускорителей и соответственно отсутствия различия их скоростных и прочих характеристик
Какой из них избрали специалисты ATI? Оставайтесь с нами, об этом чуть позже. А пока перейдем к конкретике реализации CrossFire в «железе». Как же вышеописанный метод «красного ящика», объединяющего изображения, был исполнен ATI на практике? Вот так: Конкретика CrossFire

Вот почему статья называется «Асимметричный ответ» ;-) Оказывается, инженеры ATI решили поместить описанный выше «красный ящик» (С Engine на схеме) на одну карту, «главную», и передавать на него данные со второй карты через обычный внешний DVI разъем. Тем самым, создав решение, совместимое с уже существующими картами, выпущенными до появления CrossFire! Разве это не здорово — если у вас уже есть PCI-Express карта ATI с DVI выходом, то вам достаточно докупить специальную CrossFire карту, соединить DVI выход старой карты с новой при помощи специального провода, который идет в комплекте. И ваша суперсистема готова. На выходе новой карты вы получите уже собранное Composing Engine, по результатам работы обоих ускорителей изображение, в DVI или аналоговом VGA формате.
На карте с технологией CrossFire установлен специальный разъем, напоминающий DVI, но имеющий большее число контактов, на схеме он обозначен как DMS. Через этот разъем в карту попадает DVI сигнал с первой карты, через него же из карты выходят сигналы DVI и аналогового VGА результирующего изображения, собранного красным ящиком. Кроме того, на исходной карте остается незадействованным второй выход (DVI+VGA или только VGA), а также TV-Out, а на карте CrossFire — тоже есть второй DVI+VGA. Все эти выходы, не участвующие в совместном построении изображения, разумеется, могут быть использованы для дополнительных мониторов и других стандартных применений в «мирное», не игровое время, но на них естественно нельзя выводить совместное изображение, рассчитанное обоими ускорителями в режиме CrossFire — оно поступает только на выходы разъема DMS.
А теперь самый интересный вопрос. Внимание, знатоки. Какой алгоритм разбиения изображения был выбран ATI для реализации в своем «красном ящике»?
Физически, на CrossFire карте «красный ящик» представляет собою не специальный чип с жестко запрограммированным в него алгоритмом работы, а небольшой универсальный чип с программируемым массивом логических вентилей. Этот небольшой чип содержит в себе гибко настраиваемую схему логических элементов и буферную память для хранения промежуточных результатов, а алгоритм его работы задается драйверами, загружающими в него соответствующую схему связей. На данный момент ATI реализовали все три выше описанные методики, но это не значит, что в будущем не появятся новые, улучшенные или гибридные решения по разделению нагрузки на два ускорителя. Все, что будет необходимо — просто обновить драйверы. Не удержусь и второй раз похвалю инженеров ATI за элегантное решение — мало того, что такой подход существенно снизил стоимость разработки и внедрения CrossFire, он позволил выбирать для каждого конкретного применения режим, оптимальный с точки зрения КПД (из доступных) и, тем самым, во многом застраховал наши инвестиции в мультичиповое решение от капризов конкретных игр и приложений.
- Мы можем использовать старую карту, уже установленную в нашей системе * , надо купить вторую CrossFire карту и системную плату с двумя графическими слотами PCI-Express (если такой еще нет).
- Мы можем выбирать для каждого конкретного приложения оптимальный метод взаимодействия ускорителей при построении изображения. Причем, мы можем предоставить этот выбор драйверу, и тогда он будет сверяться со списком заранее проверенных ATI приложений, для которых уже подобрана оптимальная установка, или установит самый надежный с точки зрения прозрачности для приложения Tiling метод, если приложение ему не известно. А можем выбрать метод самостоятельно, поэкспериментировав с результатами в конкретном приложении, заботясь о КПД или о максимальном качестве изображения.
- Мы можем получить, в будущем, новые режимы и методы взаимодействия.
- Мы можем на лету, не перезагружая систему, включать и выключать CrossFire, а также менять режимы его работы.
- У нас появляются новые методы AA — когда к 2, 4 или 6 семпловому MSAA в каждом чипе, добавляется еще и 2хSSAA — усреднение результатов в Composing Engine. В итоге получается уже знакомая нам по продуктам NVIDIA гибридная формула. В случае ATI, доступны два новых режима (пока) — SS2х(MS4x) SS2х(MS6х), которые почему-то названы ATI «10хAA» и «14хАА», что не совсем точно ;-) скорее, надо было назвать их «2*4хAA» и «2*6xAA». Разумеется, в таких режимах устанавливается различное расположение отсчетов MSAA для первого и второго ускорителя, только тогда это сглаживание будет иметь смысл. Но, как мы знаем, у чипов ATI паттерн отсчетов гибко задается на сетке 4х4, и таким образом мы можем разместить там два набора по 6 отсчетов так, чтобы они не пересекались.
- Мы можем использовать совместно карты разных производителей (например, ASUS и Sapphire в одной упряжке)!
* При условии, что у вас есть системная плата CrossFire Edition

- Ее очень легко адаптировать к другим существующим (X700 и иже) и будущим решениям ATI. Фактически, любая новая флагманская карта ATI может выходить сразу и в исполнении с этой технологией
- Будут проверены и признаны совместимыми новые системные платы с двумя графическими слотами, в том числе на чипсетах Intel и, возможно, даже на чипсетах NVIDIA.
- Позже эта технология может быть масштабирована дальше, не секрет, что по аналогии с процессорами через пару лет могут появиться многоядерные или многочиповые ускорители в одном корпусе, и тогда станут возможными схемы 2*2 (две карты с двумя ускорителями на каждой).
Теперь немного совсем приземленной конкретики. Для начала цены и доступность:

Причем, на прилавках магазинов CrossFire карты будут уже в конце июня, начале июля.
Вот такие данные по производительности решений с двумя картами, CrossFire X850 XT в сравнении с NVIDIA SLI 6800 Ultra приводит ATI (внимание: в обоих случаях задействованы две карты):
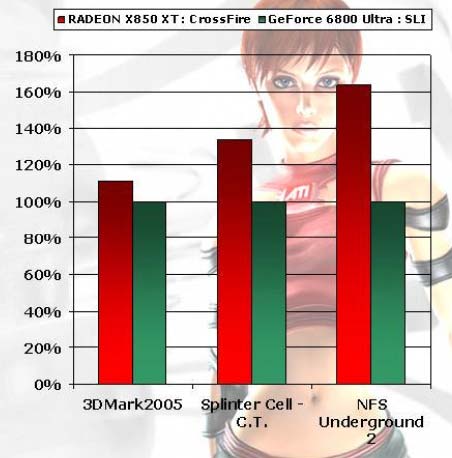
Для разрешения 1600х1200 (4xAA 8xAF)
Воздержимся от комментариев до получения собственных результатов скорости и качества работы этой технологии, а пока же отметим, что SLI работает лишь с ограниченным (причем сильно ограниченным) числом игр, в чем очень заметно проигрывает CrossFire, и, требует покупки двух новых карт, что также не может считаться большим плюсом по сравнению с CrossFire. Которая (потенциально) применима к практически миллиону уже существующих владельцев продуктов на базе всех карт семейства X800 и X850, без необходимости продавать свою старую карту.
Два самых актуальных вопроса: удастся ли ATI удержать это технологическое первенство? Ведь следующее поколение продуктов NVIDIA может взять на вооружение лучшие находки канадских специалистов в том или ином виде. И почему технология называется CrossFire — не имелась ли в виду одноименная машина фирмы Chrysler ? ;-)
Разумеется, реально очень многое будет зависеть от соотношения цена / производительность в конкретных играх. А также от наличия проблем с качеством изображения и совместимостью. Все эти аспекты мы исследуем в ближайшее время, а пока же подведем промежуточный итог:
Инженеры ATI создали очень выгодную, гибкую и удобную архитектуру многочипового рендеринга, нацеленную на конечных пользователей и игровые приложения. На бумаге перспективы CrossFire выглядят более заманчиво, чем NVIDIA SLI, а архитектурное решение можно (и нужно) признать более изящным и продуманным. В активе и совместимость с уже существующими картами и работа со всеми приложениями, и гибкий выбор метода совместной работы ускорителей. Разумеется, подобная технология нацелена на достаточно узкую нишу энтузиастов, и не принесет компании особенной сверхприбыли, но не следует забывать, что лидерство в абсолютном зачете, которое может обеспечить CrossFire, несомненно, скажется на продажах mainstream продукции ATI в лучшую сторону, а технологическое лидерство в такой области — не менее осязаемый и ценный вклад в имидж компании.
В предыдущих материалах не раз было обращено внимание на оправданность использования сборок CrossFireX. Однако при прошлых анализах конфигураций CrossFireX в тестовый стенд подбирались только высокопроизводительные компоненты. Вследствие этого в качестве используемой материнской платы было задействовано решение, которое имеет поддержку двух слотов PCI-E x16 в режиме работы x16+x16. Существенным недостатком такой реализации режима CrossFireX является высокая стоимость самой материнской платы. С другой стороны на массовом потребительском рынке присутствует достаточно большое количество доступных материнских плат, особенно для платформ Intel под процессоры на ядре Clarkdale и более новом Sandy Bridge, с поддержкой технологии CrossFireX в режимах x8+x8 и x16+x4. Сам факт асимметрии пропускной способности PCI-E x16 разъемов должен обеспечивать существенное падение суммарного быстродействия графической системы из двух видеокарт. Но столь ли критично это будет?
Обратим внимание, что для системы с CrossFireX, которая собрана из двух менее производительных видеокарт требуется и меньшая пропускная способность разъемов PCI-E x16. Тогда становится интересно, насколько понизится быстродействие графических ускорителей из ТОП-сегмента (Radeon HD 6970) и насколько из массового сегмента (Radeon HD 6870)?
Чтобы ответить на все выше заданные вопросы о работе конфигураций 2-Way CrossFireX x8+x8 и x16+x4 были использованы следующие графические ускорители: два AMD Radeon HD 6970 2 ГБ для первой сборки (второй получен методом перепрошивки BIOS AMD Radeon HD 6950 2 ГБ), и ASUS Radeon HD 6870 и MSI Radeon HD 6870 для второй сборки.
Тестовая конфигурация же выглядела следующим образом:
Intel Core i5-2500K (LGA 1155, 4 core, 3,3 ГГц, L3 6 МБ)
ASUS P8P67 (Intel P67, LGA 1155, DDR3, ATX) для x16+x4
MSI P67A-GD55 (Intel P67, LGA 1155, DDR3, ATX) для x8+x8
Scythe Kama Angle rev.B (LGA 1156/1366 support)
2х DDR2-1200 1024 МБ Kingston HyperX KHX9600D2K2/2G
Seagate Barracuda 7200.12 ST3500418AS, 500 ГБ, SATA-300, NCQ
CHIEFTEC CFT-850G-DF (850 Вт, 140+80 мм, 25дБ)
ASUS VG236H (Full HD, 1920x1080, 3D, 120 Гц) + NVIDIA 3D Vision Kit
Microsoft Windows 7 64-bit
2-Way CrossFireX на Radeon HD 6970
Сравниваем 2- Way CrossFireX x 8+ x 8 и x 16+ x 4 на Radeon HD 6970
В первую очередь проанализируем производительность работы 2-Way CrossFireX из двух более мощных видеокарт Radeon HD 6970 при работе PCI-E x16 разъемов в режимах x8+x8 и x16+x4.
Эта статья не является полностью самостоятельным материалом — скорее, приложением к нашему недавнему тестированию одиночных видеокарт семейств Radeon R7 и R9 и их работе в паре. Вопрос практической полезности режима CrossFire, как нам кажется, мы закрыли целиком и полностью, однако остались и некоторые интересные теоретические моменты, в основном относящиеся не к самим GPU, а к компьютерной платформе. Речь сегодня у нас пойдет об интерфейсе подключения видеокарт.
Является ли он важным? С точки зрения производителей (как графических процессоров, так и чиспетов) — очень даже: недаром же вот уже не первый год идет гонка пропускной способности интерфейсов. Во времена седой старины вся периферия обходилась шиной ISA, а потом именно видеокарты инициировали внедрение VLB и PCI. Последняя вскоре стала стандартной «для всего», однако ее опять оказалось мало именно видеокартам, что породило AGP, а затем и полный переход на PCI Express. Этот исторический процесс мы в свое время рассматривали подробно, так что сейчас лишь отметим, что на PCIe развитие с виду почти остановилось — только номера версий меняются и пропускная способность с каждой цифрой удваивается. В общем, одна линия нынешнего PCIe 3.0 — это как четыре линии того PCIe, с которого мы начинали, а ожидаемый в скором будущем PCIe 4.0 х1 будет соответствовать уже х8 PCIe 1.x.
Но видеокарты практически всегда используют слот максимальной ширины — х16. Казалось бы, можно уже и «ужаться», но это наблюдается только в бюджетном сегменте — а за его рамками, по мнению производителей, из-за увеличения мощности чипов нужно расширять и интерфейс. А производители плат и процессоров идут еще дальше и утверждают, что 16 линий мало — вдруг несколько видеокарт кто-то захочет поставить? Значит, нужно не меньше 32 — чтоб хотя бы две работали на полной скорости. А если их в процессоре всего 16 — значит, нужны специальные мосты и разветвители дополнительно.
Но нужны ли на самом деле? Вот это мы сегодня и попробуем проверить.
Конфигурация тестовых стендов
В качестве тестовой платформы мы (как и в прошлый раз) использовали Core i5-4690K в паре с 8 ГБ памяти DDR3-1600 на системной плате с чипсетом Intel Z97. Выбранная нами модель ASRock Z97 OC Formula интересна тем, что на ней есть четыре пригодных для подключения видеокарты слота PCIe x16, но режимы их работы разные. Самый первый может работать как х16 в одиночку или как х8, если занят второй и/или третий. Второй поддерживает режим х8, если третий свободен, и х4 в противном случае. Третий же и четвертый слоты — максимум х4, но один из них соответствует спецификациям PCIe 3.0 и разводится от процессора, а второй — чипсетный PCIe 2.0.
Использовали мы видеокарты на базе Radeon R7 260X. Почему не более мощные решения? А это самое мощное из поддерживающих CrossFire без соединительных мостиков. Использовать же мостики было бы, на наш взгляд, нарушением чистоты эксперимента — ведь обмен данными пойдет по ним, а мы хотим нагрузить шины. Поэтому именно R7 260Х.
Какие варианты тестировались? Во-первых, одна карта. Во-вторых и в-третьих — две в первом и втором слотах, что дает нам симметричную конфигурацию х8+х8. Почему две? Потому что с мостиком и без. Четвертый вариант — второй и третий слоты, т. е. PCIe 3.0 x8+x4. И еще два варианта с использованием «чипсетного» слота — совместно с первым (как обычно и делают на платах, неспособных «расщеплять» процессорные линии по слотам) и «клинический» случай: вместе с медленным третьим.
Методика тестирования
Результаты и комментарии

Единственное, что можно утверждать — использование асимметричного (т. е. «процессорный» + «чипсетный» слоты) CrossFire снижает производительность, но всего-то на 2%. А вот зависимость от скорости слотов не прослеживается, так что если в руки попало две одинаковых карты — их можно использовать, даже если плата не рассчитана под multi-GPU. Все равно работать будет нормально, обеспечивая почти двукратный прирост средней частоты кадров.

Вот более пестрый случай. Игра достаточно легкая, так что и одна видеокарта неплохо справляется с работой. Две — быстрее, но тут уже «правильный» и «неправильный» CrossFire различаются процентов на 20, что сравнимо с приростом от «неправильного» в сравнении с одиночной видеокартой. То есть смысла собирать такую конфигурацию как бы и нет, но и вреда тоже.

«Правильный» и «неправильный» CrossFire различаются на 4%, но это тяжелый случай, где даже двух видеокарт все еще мало для полноценной игры. Однако здесь мы уже подобрались близко к нижней границе комфорта, а одиночная видеокарта и половину нужного не обеспечивает.

Разница между лучшим и худшим случаем — порядка 5%, одиночную же видеокарту даже худший вариант CrossFire обходит на все 50%.

Одиночной видеокарты мало, двух — в любом виде минимально хватает. Разница между разными вариантами CrossFire есть, но очень уж смешная.

А бывает даже такое: разброс, судя по всему, на уровне погрешности измерения, т. е. все варианты можно считать одинаковыми. А вот отличие от одиночной карты принципиальное.

Равно как и здесь, но тут уже совсем без неожиданностей.
Итого
Итак: кое-какой эффект от более быстрых интерфейсов подключения видеоускорителей вроде бы есть, однако он практически незаметен. Не наблюдается и разницы между вариантами «с мостиком/без мостика», так что в какой-то степени ограничение в виде невозможности работы без него для Radeon R9 можно считать искусственным. И раз такое ограничение есть, то и более мощным, чем мы сегодня использовали, видеокартам тип интерфейса тоже должен быть примерно безразличен.

Таким образом, вердикт простой. Как мы уже писали, особого смысла в CrossFire и SLI мы не видим: работает не везде, минимальную частоту кадров не увеличивает, стоит дороже более мощной видеокарты, и т. п. Если текущей конфигурации не хватает — лучше продать то, что есть, и купить что-нибудь помощнее. Но если нет желания возиться с продажей, а купить пару к имеющейся видеокарте можно недорого (например, бывшую в употреблении через пару лет после снятия с производства) — такой вариант вполне допустим. Особенно с учетом того, что заранее готовиться для него, покупая системную плату с увеличенным количеством линий PCIe, не следует. Не требуются и платы на старших моделях чипсетов, поддерживающих «расщепление» процессорных линий между слотами — для CrossFire подойдет и недорогая системная плата, лишь бы только в нее можно было физически установить две видеокарты, а остальное уже мелочи жизни, на которые можно не обращать внимания :)
Буквально на днях компания ATI собирается анонсировать новый чипсет (или даже серию чипсетов), который должен обеспечить модную маркетинговую особенность — поддержку двух полноскоростных графических интерфейсов PCI Express x16, разумеется, с поддержкой CrossFire. До этого аналогичный шаг сделала NVIDIA с чипсетом nForce4 SLI X16 (nForce Pro в этом контексте упоминать не будем), а прежде желающим создать систему SLI/CrossFire приходилось довольствоваться менее скоростным сочетанием графических интерфейсов. В большинстве продуктов на рынке (чипсеты NVIDIA, ATI) для такого случая использовалась формула x8+x8 — пропускная способность единственного интерфейса x16 поровну распределялась между двумя слотами (форм-фактора, разумеется, PCIEx16).
Однако чипсеты Intel, первыми предложившие пользователям интерфейс PCI Express, такой возможностью не обладали даже во втором поколении (i945/955), поэтому некоторые производители материнских плат прибегали к нестандартному решению с формулой x16+x4. В данном случае первый графический слот обслуживается силами собственно графического интерфейса (x16), а второй подключается не к северному, а к южному мосту и задействует его четыре линии PCI Express, вообще-то предназначенные для подключения периферии. Причем если у платы на i945/955 с южным мостом ICH7R оставалось в этом случае хоть две свободные линии PCI-E, то решения с южным мостом ICH7 или на i915/925 лишались нового интерфейса полностью. (Впрочем, карт расширения с интерфейсом PCIEx1 на рынке даже сейчас практически нет, так что покупатель такой платы лишался, по сути, только интегрированных контроллеров (LAN, SATA RAID), подключаемых к шине PCI Express.) Лишь i975X позволил организовать разделение графического интерфейса на два слота по формуле x8+x8, как у конкурентов.
Нам показалось интересным проверить, существует ли в реальных приложениях разница между разными чипсетами или разными способами организации SLI/CrossFire хотя бы у текущих решений. Дело в том, что даже сами производители видеоускорителей не обещают заметного прироста от перехода к режиму x16+x16, называя осторожную цифру 10% для топовых моделей в самых тяжелых условиях. Изучению этого вопроса и посвящена сегодняшняя статья, в которой мы используем два ускорителя на базе ATI Radeon X850 XT (более скоростные карты в достаточном количестве на момент тестирования в нашей лаборатории отсутствовали).
Исследование производительности
- Процессоры:
- AMD Athlon 64 4000+ (2,4 ГГц), Socket 939
- Intel Pentium 4 Extreme Edition 3,46 ГГц, Socket 775
- Sapphire PC-A9RD480Adv (версия BIOS I-4M) на чипсете ATI Xpress 200 CFE (AMD)
- ECS PA1 MVP (2.0) (версия BIOS 1.0A) на чипсете ATI Xpress 200 CFE (Intel) (BIOS от 14.10.2005) на чипсете i955X (версия BIOS F1) на чипсете i975X
- 2x512 МБ DDR400 DDR SDRAM DIMM Corsair (CMX512-3200XL), 2-2-2-5
- 2x512 МБ DDR2-533 DDR2 SDRAM DIMM Corsair (CM2X512A-4300C3PRO), 3-3-3-8
- основная: [PCIEx16] Sapphire (ATI) Radeon X850 XT CrossFire Edition (256 МБ)
- дополнительная: [PCIEx16] PowerColor (ATI) Radeon X850 XT PE (256 МБ)
- ОС и драйверы:
- Windows XP Professional SP2
- DirectX 9.0c
- Intel Chipset Software Installation Utility 7.0.0.1019
- ATI Catalyst 5.12
- 7-Zip 4.10b
- MPEG4-кодек DivX Pro 5.2.1
- Doom 3 (v1.0.1282)
- FarCry (v1.1.3.1337)
- Unreal Tournament 2004 (v3339)
Результаты тестов
В качестве платформ для тестирования взяты почти все имеющиеся, с учетом того, что чипсеты NVIDIA не позволяют (надеемся, пока) запускать два CrossFire-ускорителя, хотя разделение графического интерфейса для двух SLI-карт у них есть. Таким образом, система на AMD осталась в гордом одиночестве — соответствующих серийных продуктов на чипсетах VIA и SiS мы пока не видели. Сразу хотим отметить, что напрямую сравнивать ее результаты с тремя Intel-системами не нужно, так как процессоры, разумеется, разные (единственным принципом их подбора была близость к топовым решениям, чтобы как можно меньше тормозить связку видеокарт). Более того, мы не ставили своей целью максимизировать результаты каждой из платформ — скорее, наоборот, старались их выровнять, для чего запускали платы с поддержкой DDR2 при таймингах 4-4-4, так как плата ECS PF22 Extreme меньшие «не потянула». Впрочем, ECS PA1 MVP (2.0) и вовсе отказалась нам сообщить, с какими таймингами она стартует (возможности выставить их принудительно также не было).
Итак, наша задача сегодня — наблюдать возможные отличия «CrossFire Ready»-платы (ECS PF22 Extreme) от «CrossFire Ready»-чипсета (i975X), а также от второго чипсета — ATI Xpress 200 CrossFire Edition, название которого говорит само за себя. Результаты же системы с процессором AMD даны в качестве реперной точки, хотя определенные выводы по ним мы, конечно, сделаем. Однако прежде чем броситься к играм, необходимо оценить «отвлеченное» быстродействие каждой из платформ, дабы не смешивать возможный эффект от более удачной реализации CrossFire с обычным превосходством в производительности при работе с памятью.
Действительно, налицо разница в скорости между системами, причем i975X выигрывает пару процентов у [конкретного представителя] i955X и до 5% у чипсета ATI. Разная процессорная архитектура неизбежно приводит к разнице между платформами Intel и AMD, однако и здесь есть интересный момент, который трудно было предсказать заранее. Все системы с процессором Pentium 4 EE практически не отреагировали на включение CrossFire, в то время как результаты платы с не самым слабым Athlon 64 4000+ «просели» (да-да, вы ведь не ожидали, что добавление второго видеоускорителя ускорит процесс архивирования?!) почти на 3%. Не очень много, но наглядная демонстрация пользы от Hyper-Threading: второй логический процессор целиком берет на себя обслуживание Catalyst AI.
Впрочем, кодирование видео практически не замедляется во всех случаях, так что, в конечном итоге, интеллект видеодрайверов ATI обходится не слишком дорого.
Теперь о 3D-приложениях. Наверное, следует напомнить, что далеко не все игры получают выигрыш от распараллеливания рендеринга картинки — или из-за недоработок в драйверах, или из-за того, что производительность системы упирается не в видеоускоритель, а в какой-либо иной компонент (как правило, процессор). Так, мы не стали приводить в статье добросовестно отснятые показатели в SPECviewperf (тут включение CrossFire вызывает замедление работы до двух раз) и игре Painkiller (±0%); ситуацию в целом красноречиво иллюстрирует Unreal Tournament 2004:
Обратимся к тем двум играм, в которых эффект от CrossFire наблюдается.
Наконец, самое интересное: максимальный режим. Снова тот же артефакт производительности у i975X (прирост от CrossFire всего 54% из-за слегка завышенной общей скорости), прочие результаты почти одинаковы (
62%). По-видимому, здесь даже связка CrossFire упирается в собственную производительность, а скорость процессоров избыточна. А вот про минимальный показатель fps этого сказать нельзя, здесь четко наблюдается превосходство системы с Athlon 64 4000+: в режиме CrossFire у нее этот показатель выше на 32%, в то время как у систем с Pentium 4 EE 3,46 ГГц прирост составляет всего
Читайте также: