
Total lba written ssd что это
Обновлено: 17.05.2024
Что такое атрибуты SMART и как они могут быть полезны?
Каждый диск работает под заранее установленным набором атрибутов SMART и соответствующими предельными значениями, которые диск не должен проходить во время нормальной работы.
Описание некоторых атрибутов SMART Health Info отображается в следующей таблице. Эти атрибуты могут отличаться в зависимости от выбранного SSD-накопителя Intel или другого диска. Некоторые из этих атрибутов могут не поддерживаться вашим SSD-накопителем или диском.
Атрибуты SMART для SATA
Id
Атрибут и описание (SATA)
Количество секторов, переудвижных секторов
В нем отсчитываются номера снятых с производства блоков после выхода с производства (количество дефектов возросло).
Количество часов с отключением питания
Raw value reports the cumulative number of power-on hours over the life of the device.
Примечание. Статус включаемой/выключяемой функции УПРАВЛЕНИЯ питанием (DIPM) влияет на количество часов, о которые сообщили.
Количество циклов питания
В основе данных отчетов о накопительное количество событий цикла питания (включаем/выключение) в течение жизненного цикла устройства.
VailableReserved Space
Сообщает оставшееся количество резервных блоков. Нормализованное значение начинается с 100 (64h), что соответствует 100% доступности зарезервированного пространства. Пороговое значение для этого атрибута — 10% доступности.
Количество сбойов программы
В raw value отсчитываются общее количество сбойов программы. Нормализованное значение, начиная с 100, показывает процент сбой оставшегося допустимого значения программы.
Количество сбойов стирки
На простом значении отсчитываются общее количество стиранных данных. Нормализованное значение, начиная с 100, показывает процент сбой оставшегося допустимого стира.
Непредвиденное отключение питания
Отчеты о количестве нестандатных отключений, накопитель издает отчеты о времени работы SSD-накопителя. "Нестандерный выключение" - это отключение питания без НЕПОСРЕДСТВЕННОго ожидания в качестве последней команды (вне зависимости от активности PLI с помощью конденсаторов). Также она известна как "отключение отката питания" для одного магнитного диска.
Количество конечных обнаружений ошибок
Отчеты о количестве ошибок, с которыми сталкиваются во время проверки адресов логических блоков (LBA) на пути данных SSD. Нормализованное значение начинается с 100 и декрементов по 1 для каждого обнаруженного несоответствия тегов LBA. Пороговое значение : 90.
Количество неустанных ошибок
В raw-значении отсчитываются количество ошибок, которые не могут быть восстановлены с помощью кода коррекции ошибок (ECC).
Temperature (Температура) — воздушный поток (корпус)
Отчет о температуре корпусе SSD в градусах Цельсия. Простое значение:
- Byte 0 = Текущая температура (°C)
- Byte 2 = Новейшая минимальная температура (°C)
- Byte 3 = Новейшая максимальная температура (°C)
Нормализовано значение : 100. Температура корпусов рассчитывается на основании смещения от внутреннего датчика температуры.
Безопасное количество выключения (отключение от отката питания)
В оккупном значении сообщается накопительное количество ненадежных (по-тому) событий выключения в течение всего времени службы устройства. Безопасное выключение происходит тогда, когда устройство выключено без ожидания НЕМЕДЛЕННОЙ является последней командой.
Temperature (температура) — внутреннее устройство
Отчет о внутренней температуре SSD-системы. Показания температуры — это значение, прямое от внутреннего датчика. Исходным значением является текущая температура. Нормализованное значение — это мин уравнения результатов (150-ток-терм, 100).
Количество ошибок CRC
Общее количество ошибок, с которыми сталкиваются ошибки интерфейса SATA.
Записи в хост
Raw value reports the total number of sectors written by the host system. Raw value increases by 1 for every 65 536 sectors written by the host.
Время рабочей нагрузки, износ носите информации
Измеряет износ, который износа можно увидеть на SSD-качестве (после сброса timed Workload Timed Workload Timer, атрибут E4) в процентах от максимальных циклов номинальной нагрузки.
Время рабочей нагрузки, коэффициент чтения/записи хоста
Процент операций загрузки/загрузки, которые являются операциями чтения (после сброса timed workload timed Timed Workload Timer, атрибут E4).
Timed Workload Timed Workload Timed Timed Workload Timed Timed Workload Time
Измеряет время, запамянутее (количество минут) с момента запуска этого времени рабочей нагрузки.
Доступное пространство для зарезервированного пространства
Сообщает оставшееся количество резервных блоков. Нормализованное значение начинается с 100 (64h), что соответствует 100% доступности зарезервированного пространства. Пороговое значение для этого атрибута — 10% доступности.
Индикатор износа носитла
Отчет о количестве циклов, которые прошли в медиафайле NAND. Нормализованное значение снижается линейно со 100 до 1 по мере увеличения среднего числа циклов стирки с 0 до максимальных номинальных циклов. Как только нормализованное значение достигает 1, их количество не уменьшается, хотя вероятно, на устройство может быть наложен значительный дополнительный износ.
Общее количество LBAS в письменной области
Кол-во секторов, написанных хостом.
Общее количество прочитано LBAs
Кол-во секторов, прочитано ведущим.
Атрибуты SMART для NVMe*
Id
Атрибут и описание (NVMe)
Критическое предупреждение
Эти биты, если установлены, пометить различные источники предупреждения.
- Бит 0: Доступная запасная не выше порогового значения
- Бит 1. Температура превышает допустимые значения
- Бит 2. Надежность снижается из-за чрезмерных насчетов носите информации или внутренних ошибок
- Бит 3. Носите информации находится в режиме только чтения
- Бит 4. Ошибка резервной системы с энергоэкономией (например, ошибка теста конденсатора потери питания)
- Биты 5–7: Зарезервировано
Любое из критически важных предупреждений может быть связано с асинхронным уведомлением о событии.
Температура
Сообщает общую текущую температуру устройства в Кельвине.
Доступные запасные части
Содержит нормализованный процент (от 0 до 100%) оставшейся доступной запасной емкости. Начинается от 100 и декрементов.
Доступное пороговое значение запасных частей
Пороговое значение установлено на 10%.
Оценка использования в процентах
(допустимые значения превышают 100%). Значение 100 указывает на то, что расчетная изостойкость устройства была пополнена, но может не указывать на неисправность устройства. Значение может превышать 100. Проценты с более чем 254 должны быть представлены как 255. Это значение должно быть обновлено один раз в час питания (если контроллер не находится в режиме сна).
Чтение единиц данных(в LBAS)
Содержит число 512 единиц данных, которые хост считает у контроллера. это значение не содержит метаданных. Это значение оценивается в тысячах (то есть значение 1 соответствует 1000 считыванным 512 bytes) и округлено. Если размер LBA является значением, кроме 512 бит, контроллер должен преобразовать количество считыванных данных в 512 бит.
Записи единиц данных(в LBAS)
Содержит 512 единиц данных, которые хост списыл контроллеру. это значение не содержит метаданных. Это значение сообщается в тысячах (то есть, значение 1 соответствует 1000 единицам из 512 написанных bytes) и округлено. Если размер LBA является значением, кроме 512 бит, контроллер должен преобразовать объем данных, написанный в 512 бит. Для набора команд NVM в это значение должны включаться логические блоки, написанные как часть операций записи. Это значение не должно повлиять на написание неустанных команд.
Команды чтения хоста
Здесь содержится номер команд чтения, которые были выданы контроллеру.
Команды записи хоста
Здесь содержится номер команд записи, которые были выданы контроллеру.
Контроллер время работы (через несколько минут)
Содержит время работы контроллера с командами I/O. Контроллер загружен, когда есть выдающаяся команда для очереди под контроллером. (В частности, команда была выдана в результате записи точки входа в очередь ввода/выхода в очередь отправки, и соответствующая запись очереди завершения еще не была размещена в связанной очереди ввода/завершения.) Это значение будет отчитанося в течение нескольких минут.
Циклы питания
Содержит количество циклов питания
Часы работы с питанием
Содержит количество часов работы с питанием. Это не относится к времени, когда питание контроллера было при низком энергосхеме.
Небезопасные отключения
Содержит количество небезопасного выключения. Этот подсчет будет приращен после того, как не будет получено уведомление о выключении системы (CC.SHN) до отключения питания.
Ошибки мультимедиа
Содержит количество ошибок, когда контроллер обнаружил невозвратимую ошибку целостности данных. В это поле включены ошибки, такие как неугрешимые ошибки ECC, ошибка проверки CRC или некорректное несоответствие тега LBA.
Количество входов в журнал сведений об ошибках
Содержит количество входов в журнал Информации об ошибках за время работы контроллера.
Предупреждение о времени перепада температур в композитном режим
Содержит количество времени в минуты, за которые контроллер работает, и температура композита превышает или равна полю (Warning Composite Temperature Threshold) (WCTEMP) и ниже критического порогового значения температуры (CCTEMP) в структуре идентифицирующих данных контроллера.
Критическое время композитной температуры
Контроллер имеет время в несколько минут, а температура композитной температуры (Composite Temperature Threshold) повышается до критического значения (CCTEMP) в структуре идентифицируемой структуры данных контроллера.
Понимание выходных данных команд smartctl
На выходе получается много информации, которую не всегда легко понять. Наиболее интересной, вероятно, является та часть, которая помечена как “Vendor Specific SMART Attributes with Thresholds”. Она сообщает различные статистические данные, собранные S.M.A.R.T. устройством, и позволяет сравнить эти значения (текущие или худшие за все время) с некоторым порогом, определенным поставщиком.
Например, вот мои отчеты о переназначенных секторах на диске:
Вы можете заметить атрибут «Pre-fail». Он означает, что значение является аномальным. Таким образом, если значение превышает пороговое, велика вероятность сбоя. Другая категория »Old_age" используется для атрибутов, отвечающих значениям «нормального износа».
Последнее поле (здесь со значением «3») соответствует исходному значению атрибута, которое сообщает диск. Обычно это число имеет физическое значение. Здесь это фактическое количество переназначенных секторов. Для других атрибутов это может быть температура в градусах Цельсия, время в часах или минутах или количество раз, когда для диска было выполнено определенное условие.
В дополнение к исходному значению, диск с поддержкой S.M.A.R.T. должен сообщать «нормализованные значения» (значения полей, самые худшие и пороговые). Эти значения нормируются в диапазоне 1-254 (0-255 для пороговых значений). Прошивка диска выполняет эту нормализацию с помощью некоторого внутреннего алгоритма. Кроме того, разные производители могут нормализовать один и тот же атрибут по-разному. Большинство значений представлены в процентах, причем чем выше, тем лучше, но так бывает не всегда. Когда параметр ниже или равен пороговому значению, указанному производителем, диск считается неисправным в терминах этого атрибута. Помня о всех указаниях из первой части статьи, когда атрибут, показывающий ранее значение “pre-fail” все-таки дал сбой, наиболее вероятно, что скоро диск выйдет из строя.
В качестве второго примера возьмем “seek error rate”:
На самом деле (и это основная проблема отчетности S.M.A.R.T.), точное значение полей каждого атрибута понимает только поставщик. В моем случае Seagate использует логарифмическую шкалу для нормализации значения. Таким образом, «71» означает примерно одну ошибку на 10 миллионов запросов (10 в степени 7,1). Забавно, что самым худшим показателем за все время была одна ошибка на 1 миллион запросов (10 в 6-й степени).
Если я правильно понимаю, то это значит, что головки моего диска сейчас расположены точнее, чем раньше. Я не следил за этим диском внимательно, поэтому анализирую полученные данные весьма субъективно. Возможно накопитель просто надо было немного «обкатать» с тех пор как он был введен в эксплуатацию? Или может быть это следствие механического износа деталей и, следовательно, теперь имеет место меньшая сила трения? В любом случае, какова бы ни была причина, это значение является скорее показателем производительности, чем ранним предупреждением об ошибке. Так что меня оно не сильно беспокоит.
Помимо вышеприведенного и трех крайне подозрительных ошибок, записанных около шести месяцев назад, этот диск находится в удивительно хорошем состоянии (по данным S.M.A.R.T.) для стокового диска ноутбука, проработавшего более 1100 дней (26423 часа).
Из любопытства я провел этот же тест на гораздо более новом ноутбуке, оснащенном SSD:
Первое, что бросается в глаза, так это то, что несмотря на наличие S.M.A.R.T., устройства нет в базе данных smartctl . Но это не помешает инструменту собирать данные с SSD, однако он не сможет сообщить точные значения различных атрибутов, специфичных для поставщика:
Выше вы видите выходные данные абсолютно нового SSD. Данные понятны даже в случае отсутствия нормализации или метаинформации для данных конкретного поставщика, как в моем случае с “Unknown_SSD_Attribute.” Я могу только надеяться, что в последующих версиях smartctl в базе данных появятся данные об этой модели диска, и я смогу лучше определять потенциальные проблемы.
Ресурс SSD диска в TBW
Однако, если быть точным, производители дают гарантию в 3, 5 (или больше) лет с оговоркой - если в течении этого срока не будет превышен ресурс по объему записи на SSD диск. При этом, все нормальные производители, указывают такой ресурс записи в технических спецификациях модели диска.
Этот ресурс записи указывается в терабайтах. Например для SSD дисков емкостью 120 - 128 Гб типичный ресурс записи примерно 70 терабайт. А для дисков емкостью 240 - 256 Гб, типичный ресурс записи примерно 150 терабайт. Ресурс записи увеличивается вместе с увеличением емкости диска. Чем больше емкость - тем больше ресурс записи.
В технических спецификациях моделей SSD дисков, этот показатель указывается с сокращением TBW (Total Bytes Written).
70 Тб это много или мало? Если записывать на диск по 120 Гб в день, то 70 терабайт придется записывать в течении почти двух лет.
На самом деле такие объемы записи большая редкость и поэтому даже ресурса 70 Тб, для среднестатистического домашнего или офисного компьютера, что называется "выше крыши". В реальности на домашнем или офисном компьютере объем записи значительно меньше 10 терабайт в год. Намного меньше.
У меня есть возможность, время от времени, узнавать сколько было записано на SSD диск. На тех компьютерах, которые бывают у меня в ремонте или обслуживании.
Так вот. На большинстве компьютеров (это и домашние и офисные) в течении года объем записи на диск меньше или немного больше 2-х терабайт. За год. Максимум который мне попадался, это более 12 терабайт за 3 три года, то есть менее 5 терабайт в год.
Хотя конечно есть особые случаи, при которых объем записи за год будет выше 2-х терабайт. И даже может намного выше. В том случае, если SSD диск используется для работы с файлами большого размера. Причем файлы эти постоянно удаляются и добавляются. Например обработка фотографий или видеомонтаж. Если вы выбираете SSD диск для такой или похожей работы, тогда конечно нужно подумать о ресурсе записи.
Однако, те, кто покупает SSD диск для такой работы, обычно берут диск емкостью как минимум 240 - 256 Гб, или 480 - 512 Гб. А у этаких дисков и ресурс записи выше.
Каждый нормальный SSD диск ведет учет записанного объема данных. Этот счетчик хранится в SMART атрибуте номер 241 (F1) и называется Total LBAs Written. Так что можно эту информацию посмотреть при помощи любой программы, которая показывает SMART атрибуты диска. Но тут есть ньюанс, проблема в том, что в этом атрибуте записываются не байты, а блоки байт (блоки LBA). А размер этих блоков различается у разных производителей. Например у Samsung размер блока 512 байт. А у Transcend размер блока 32 Мб.
Так что, в чистом виде, число из атрибута 241 имеет смысл только в том случае, если вы знаете размер блока для этой модели диска. Однако большинство производителей имеют специальные служебные программы для своих дисков и в такой программе можно увидеть объем записанных данных в тербайтах.
Правда ли SSD надёжнее, чем HDD?

В серии статей SSD 101 мы рассмотрели SSD со всех сторон. А теперь проверим главный аргумент фанатов SSD — что эти устройства выходят из строя гораздо реже, чем старые добрые HDD. Они обычно объясняют, что в SSD нет движущихся частей, и предъявляют документы от производителей с мутными расчётами среднего времени до отказа (MTBF). Всё это хорошо для рекламы, но мы предпочитаем реальную статистику частоты отказов.
Время работы SSD диска
Время, которое SSD диск будет работать, в общем случае определяется типом флэш-памяти. То есть какой тип ячеек используется и по какому техпроцессу изготовлена память. Самый большой ресурс у ячеек типа SLC, далее идут MLC и наконец TLC.
Что означает лимит по количеству циклов записи в практическом смысле? И как примерно оценить возможный срок жизни того или иного диска?
Возьмем условный диск в котором используется MLC flash-память произведенная по техпроцессу 19 нанометров. Предположим что производитель этой памяти указывает для нее лимит записи 3000 циклов. Это показатель для хорошей MLC flash-памяти изготовленной по техпроцессам 19 или 20 нанометров.
На основе этой памяти изготовлен диск емкостью 120 Гб. Лимит в 3000 циклов означает что вы можете 3000 раз полностью записать ваш диск.
Хотя на самом деле, при тотальной записи всего диска, можно будет записать его только 1500 раз, то есть в два раза меньше. Это связано с тем, что перед новой записью ячейки памяти должны быть очищены от предыдущего содержимого. А это один цикл записи. То есть на каждый цикл записи данных, приходится цикл стирания ячеек.
Если вы будете каждый день целиком его заполнять, затем полностью очищать и на следующий снова целиком заполнять, то теоретически память проживет 1500 дней. То есть больше 4 лет. Если же вы в день будете записывать только 60 гигабайт и стирать диск только раз в два дня, то срок жизни увеличивается до 8 с лишним лет.
Конечно это упрощенно. Но понятно, что срок жизни флэш-памяти достаточно большой.
То есть во всех этих жалобах про постоянно снижающийся лимит записи, сегодня серьезной основы нет. Хотя лет 10 назад, когда SSD диски только выходили на массовый рынок, проблема "короткой жизни" была. Но наука и техника не стоят на месте. И сегодня даже самые дешевые дешманские SSD диски имеют гарантию в 3 года. А производители первого эшелона, Самсунг, Интел даже на бюджетные модели дают гарантию в 5 лет, а для профессиональных моделей и больше.
Что не относится к S.M.A.R.T.?
Все это, конечно, круто. Однако S.M.A.R.T. – это не хрустальный шар. Он не может спрогнозировать отказ со стопроцентной вероятностью и не может гарантировать, что накопитель не выйдет из строя без предупреждения. В лучшем случае S.M.A.R.T. стоит использовать для оценки вероятности поломки.
Учитывая статистический характер прогнозирования отказов, технология S.M.A.R.T. особенно интересует компании, использующие большое количество устройств для хранения данных. Чтобы выяснить, насколько точно S.M.A.R.T. может прогнозировать отказы и сообщать о необходимости замены дисков в центрах обработки данных или серверных мейнфреймах, даже проводились специальные исследования.
В 2016 году Microsoft и университет штата Пенсильвания провели исследование, связанное с SSD.
Согласно этому исследованию, некоторые атрибуты S.M.A.R.T. считаются хорошими индикаторами неизбежности отказа. В особенности в статье упоминаются:
Счетчик переназначенных (Realloc) секторов:
Несмотря на то, что основополагающие технологии радикально отличаются, этот показатель остается востребованным как в мире SSD, так и в мире жестких дисков. Стоит отметить, что из-за особенностей алгоритмов балансировки износа, используемых в SSD, когда несколько секторов выходят из строя, то с большой вероятностью можно предположить, что скоро выйдут из строя еще больше.
Ошибки в цикле Program/Erase (P/E):
Это признак проблем с основным оборудованием флеш-памяти, связанных с тем, что диск не может удалить данные из блока или сохранить их там. Дело в том, что процесс производства несовершенен, поэтому появление таких ошибок вполне можно ожидать. Однако флеш-память имеет ограниченное число циклов записи/удаления. По этой причине внезапное увеличение числа событий может сигнализировать о том, что диск достигает своего предела, и вполне ожидаемо, что другие ячейки памяти также начнут выходить из строя.
CRC и неисправимые ошибки («Data Error ”):
События такого типа могут быть вызваны ошибками хранения, либо проблемами с внутренним каналом связи накопителя. Этот индикатор учитывает как исправленные ошибки (без проблем сообщенные хост-системе), так и неисправленные ошибки (из-за которых происходит блокировка диска, сообщившего хост-системе о невозможности чтения). Другими словами, исправляемые ошибки невидимы для операционной системы, тем не менее они влияют на производительность накопителя, увеличивая вероятность переназначения сектора.
SATA downshift count:
Из-за временных помех, проблем с каналом связи между накопителем и хостом или из-за внутренних проблем с накопителем, интерфейс SATA может переключиться на более низкую скорость передачи сигналов. Снижение скорости соединения ниже номинального уровня оказывает очевидное влияние на производительность диска. Таким образом, этот показатель является наиболее значимым, в особенности, когда он коррелирует с наличием одного или нескольких предыдущих показателей.
В исследовании Microsoft и университета штата Пенсильвания не раскрывались модели исследуемых дисков, однако, по словам авторов, большинство дисков поступают от одного и того же поставщика в течение уже нескольких поколений.
В ходе исследования также были отмечены значительные различия в надёжности между различными моделями. Например, «худшая» изученная модель показывает двадцатипроцентную частоту отказов через 9 месяцев после первой ошибки переназначения и до 36-ти процентов отказов в течение 9 месяцев после первого появления ошибок данных. «Худшей» моделью было названо более старое поколение дисков, рассматриваемых в статье.
С другой стороны, с теми же симптомами, что приведены выше, накопители нового поколения отказали в 3% и 20% в соответствии с теми же ошибками. Трудно сказать, можно ли объяснить эти цифры улучшением конструкции накопителя и производственного процесса, или здесь роль играет эффект устаревания накопителя.
«Существует большая вероятность появления симптомов, предшествующих отказу SSD, которые активно себя проявляют и быстро прогрессируют, сильно сокращая время жизни накопителя до нескольких месяцев.»
Другими словами, одна случайная ошибка, о которой сообщил S.M.A.R.T., определенно не должна рассматриваться как сигнал о неизбежном отказе. Однако, когда исправный SSD начинает сообщать о все большем количестве ошибок, следует ждать краткосрочного или среднесрочного сбоя.
Но как узнать, в каком состоянии сейчас ваш SSD? Для удовлетворения своего любопытства, либо из желания начать внимательно следить за своими накопителями, вы можете использовать инструмент мониторинга smartctl .
Использование smartctl для мониторинга состояния вашего SSD в Linux
Чтобы следить за S.M.A.R.T статусом вашего диска, я предлагаю использовать инструмент smartctl , который является частью пакета smartmontool (по крайней мере на Debian/Ubuntu).
smartctl – это инструмент командной строки, но это особенно помогает в случаях, когда вам нужно автоматизировать сбор данных, например, с ваших серверов.
Первый шаг в использовании smartctl – это проверка того, есть ли на вашем диске S.M.A.R.T. и поддерживается ли он инструментом:
Как видите, мой внутренний жесткий диск ноутбука действительно поддерживает S.M.A.R.T. и он включен. Итак, как теперь получить S.M.A.R.T статус? Есть ли какие-то зафиксированные ошибки?
Выдача отчета «о всей S.M.A.R.T. информации о диске» — это опция -a :
Что такое отказ для SSD и HDD?
В своих ежеквартальных отчётах Drive Stats мы определяем отказ диска или как реактивный (диск не работает), или как проактивный (мы считаем, что отказ неизбежен). В случае HDD мы определяем проактивный отказ по специфической статистике SMART, которую сообщает сам диск и которую мы отслеживаем.
SMART, или S.M.A.R.T., расшифровывается как Self-monitoring, Analysis, and Reporting Technology и представляет собой систему мониторинга, встроенную в HDD и SDD. Основная функция — сообщать различные показатели, связанные с надёжностью диска, для предсказания отказов. Backblaze каждый день записывает атрибуты SMART всех работающих дисков.
То же самое для SSD. Различные модели сообщают разные показатели SMART, но некоторые совпадают. На сегодняшний день для SSD мы регистрируем 31 атрибут SMART-статистики. 25 из них перечислены ниже.
Оставшиеся шесть (16, 17, 168, 170, 218 и 245) мы не можем найти. Пожалуйста, напишите в комментариях, если у вас есть информация по отсутствующим атрибутам.
Мы только начинаем использовать статистику SMART для предупреждения отказов SSD. Многие атрибуты зависят от модели диска или производителя. Кроме того, у нас было пока мало отказов SSD, как вы увидите ниже. Это ограничивает количество данных для исследования. Так что в реальности мы пока не смогли предсказать ни одного отказа.
Сравнение яблок с яблоками
В серверах хранения данных в качестве загрузочных дисков работают и SSD, и HDD. В нашем случае называть их загрузочными неверно, поскольку они также хранят различные логи и т. д. Другими словами, регулярно читают, записывают и удаляют файлы, а не только выполняют загрузку сервера.
В первых серверах хранения данных мы использовали только HDD, поскольку они были дешёвыми и выполняли свою функцию. Так продолжалось до середины 2018 года, когда мы смогли купить SSD на 200 ГБ по цене около $50, что в нашем понимании было верхней ценовой границей для загрузочных дисков серверов хранения данных. Это был эксперимент, но всё получилось настолько хорошо, что с середины 2018 года мы перешли на использование только SSD и заменяли вышедшие из строя загрузочные HDD на SSD.
Итак, у нас две группы дисков — SSD и HDD — которые выполняют одинаковые функции, имеют одинаковую рабочую нагрузку и работают в одинаковых условиях в течение долгого времени. Естественно, мы решили сравнить частоту отказов загрузочных дисков SSD и HDD. Ниже приведены показатели отказов за весь срок службы для каждой группы по состоянию на II кв. 2021 года.
Годовая частота сбоев (AFR)
| Количество дисков | Средний возраст (мес.) | Дней работы | Всего сбоев | AFR | |
|---|---|---|---|---|---|
| SSD | 1666 | 14,2 | 591 501 | 17 | 1,05% |
| HDD | 1607 | 52,4 | 3 523 610 | 619 | 6,41% |
Загрузочные диски. Отчётный период: апрель 2013 — июнь 2021
Как продлить жизнь SSD диска
Свободное место на диске. Не "забивайте" его полностью - старайтесь чтобы на диске было процентов 20 - 30 свободного места. Наличие свободного места позволяет контроллеру диска выравнивать износ ячеек памяти. Это свободное место должно быть не размечено, то есть не присвоено никакому разделу с файловой системой. Кстати, наличие такого неразмеченного места, позволяет еще и по поводу TRIM не заморачиваться.
Бесперебойное электропитание. Если вы используете SSD в обычном компьютере, подключайте компьютер через UPS (ИБП). Если SSD в ноутбуке, следите за состоянием батареи - не допускайте отключения ноутбука по полному разряду батареи. Диски SSD не любят внезапной потери питания. При нештатном отключении питания на диске возможно повреждение данных в ячейках flash-памяти. Как вариант можно купить модель диска в которой есть защита от отключения питания (Power Loss Protection).
Охлаждайте. Диски SSD (как и HDD, как любая электроника) не любят перегрева. Чем выше температура диска тем быстрее он выйдет из строя. Если вы устанавливаете SSD в ноутбук, то остается только надеяться на то, что конструкторы вашего ноутбука предусмотрели возможность достаточного отвода тепла от диска.
Но если вы устанавливаете SSD в обычный компьютер, тогда у вас "развязаны руки". Самое меньшее что вам доступно это использовать металлический переходник c 2.5" (диск SSD) на 3.5" (бокс для дисков в корпусе). По металлу переходника тепло от диска будет переходить на корпус. Однако для дисков в пластмассовом корпусе металлический переходник бесполезен.
В контексте охлаждения большой плюс это алюминиевый корпус SSD. Если диск сделан по уму, то металлический корпус используется как радиатор для отвода тепла от микросхем.
Кроме этого можно поставить вентилятор - во многих корпусах даже предусмотрено место для специального вентилятора, обдувающего бокс для дисков. В некоторых корпусах даже есть этот вентилятор.
Не нужно дефрагментировать. Фрагментация файловой системы не снижает скорость работы SSD. Поэтому, делая дефрагментацию вы не получите выигрыша в скорости. Однако, дефрагментируя, вы сократите срок жизни диска, за счет увеличения операций записи.
Размер оперативной памяти. Если у вас Windows 7, 8 или 10 поставьте как минимум 8 Гб оперативной памяти. Дело в том, что при нехватке оперативной памяти, операционная система компенсирует эту нехватку за счет диска (дисковый swap файл или раздел). И чем меньше физической оперативной памяти, тем больше объем записи в дисковый swap. Что касается указанных версий Windows, то при размере оперативной памяти в 4 Гб, они очень активно используют дисковый swap. А если оперативной памяти 8 Гб то для Windows 7 и 8 дисковый swap можно вообще отключить.
Иван Сухов, 2020 г.
Что такое S.M.A.R.T.?
S.M.A.R.T. (расшифровывается как Self-Monitoring, Analysis, and Reporting Technology) – это технология, вшитая в накопители, такие как жесткие диски или SSD. Ее основная задача – это мониторинг состояния.
На деле, S.M.A.R.T. контролирует несколько параметров во время обычной работы с диском. Он мониторит такие параметры как количество ошибок чтения, время запуска диска и даже состояние окружающей среды. Помимо этого, S.M.A.R.T. также может проводить тесты с использованием накопителя.
В идеале, S.M.A.R.T. позволит прогнозировать предсказуемые отказы, такие как отказы, вызванные механическим износом или ухудшением состояния поверхности диска, а также непредсказуемые отказы, вызванные каким-либо неожиданным дефектом. Поскольку обычно диски не выходят из строя внезапно, S.M.A.R.T. помогает операционной системе или системному администратору идентифицировать те диски, которые скоро выйдут из строя, чтобы их можно было заменить и избежать потери данных.
SSD победили… Подождите, не так быстро!
Всё понятно, SSD победили. Можно положить HDD на полку или на пол как ограничитель для двери. Но погодите, давайте сначала учтём несколько моментов, которые не вошли в таблицу.
- Средний возраст SSD составляет 14,2 месяца, а средний возраст HDD — 52,4 месяца.
- Возраст самых старых SSD — около 33 месяцев, а самых новых HDD — 27 месяцев.
Другим фактором является количество дней, сколько диски каждой группы проработали без сбоев. Большой разброс в количестве дней работы приводит к значительной разнице в доверительных интервалах двух групп, поскольку существенно различается количество наблюдений (т.е. дней работы).
Чтобы провести более точное сравнение, попробуем привести к общему знаменателю средний возраст и количество дней работы для SSD и HDD. Для этого можем перенестись назад во времени, когда группа HDD соответствовала группе SSD из II кв. 2021 года по среднему возрасту и количеству дней работы. Это позволит сравнить группы в один и тот же период жизненного цикла.
Взяв данные по HDD за IV кв. 2016 года, мы смогли сделать следующее сравнение.
Годовая частота сбоев (AFR)
| Количество дисков | Средний возраст (мес.) | Дней работы | Всего сбоев | AFR | |
|---|---|---|---|---|---|
| SSD на II кв. 2021 | 1666 | 14,2 | 591 501 | 17 | 1,05% |
| HDD на IV кв. 2016 | 1297 | 14,3 | 659 526 | 25 | 1,38% |
Загрузочные диски. Отчётный период: апрель 2013 — указанный период
Неожиданно разница в AFR оказалась не такой уж большой. На самом деле статистика каждой группы находится в пределах 95%-ного доверительного интервала другой группы. Окно довольно широкое (плюс-минус 0,5%) из-за относительно небольшого количества дней работы накопителей.
Что же в итоге? Мы получили некоторые свидетельства, что в начале работы (в среднем до 14 месяцев в данном случае) SSD выходят из строя реже, но не намного. Но вы же покупаете диск не на 14 месяцев, а на годы. Что мы знаем об этом?
Резюме по примерам
Как видите, в реальной жизни объемы записи таковы, что ресурса записи, который заявлен производителями дисков, хватит на очень долгое время.
Частота сбоев со временем
У нас есть данные по загрузочным HDD с 2013 года и по загрузочным SSD с 2018 года. На диаграмме показан Lifetime AFR каждого типа дисков до II кв. 2021 года.

Как видно, с 2018 года частота сбоев загрузочных HDD стала расти. Тенденция сохранялась в 2019 и 2020 годах, а в 2021 году (пока что) остановилась. Очевидно, что с увеличением возраста HDD увеличивается и частота отказов.
Интересно сравнить кривые в первых четырёх точках. Для флота HDD пятый год (2018) знаменовал резкий рост частоты отказов. Ждёт ли та же участь SSD в их пятый год? Хотя мы можем ожидать некоторого увеличения AFR по мере старения SSD, но будет ли оно таким же резким, как в случае с HDD?
Вступление
У SSD дисков есть отличие от HDD (механические, магнитные диски). Ячейки флеш-памяти, из которой делают SSD, имеют ограниченное количество циклов записи. Для наиболее распространенного сегодня типа флеш-памяти TLC (ячейки емкостью 3 бита) ресурс записи равен примерно 1000 циклов.
Соответственно, срок жизни SSD диска зависит от объема записи данных на этот диск. Чем больше вы записываете данных на диск, тем быстрее он "умрет".
Итог: SSD или HDD?
Что же нам покупать: SSD или HDD? Учитывая то, что мы знаем на сегодняшний день, вряд ли можно использовать AFR как фактор при принятии решения. С учётом возраста и количества дней работы оба типа накопителей схожи, а разница недостаточна, чтобы оправдать дополнительные затраты на покупку SSD вместо HDD. На данном этапе лучше принимать решение на основе других факторов: стоимость, требуемая скорость, энергопотребление, требования к форм-фактору и так далее.
В ближайшие пару лет мы получим более полное представление об AFR для SSD. И тогда сможем решить, насколько велика разница в частоте отказов SSD и HDD. А сейчас мы не видим, чтобы она была значительной.
Ресурс SSD диска в TBW и по времени
Даже небольшая сумма может помочь написанию новых статей :)
Или поделитесь ссылкой на эту статью со своими друзьями.
В этой статье описаны разные аспекты ресурса SSD дисков. А также советы по увеличению срока жизни SSD дисков.
Практический срок жизни SSD диска
За последние лет 9, я установил, в новые и старые компьютеры, несколько десятков SSD дисков. Из них, насколько я знаю, "сломался" только один - Plextor бюджетной линейки S. Да и тот сломался в течении гарантийного срока и данные, размещенные на этом диске, не пострадали.
Но здесь нужно сделать важное уточнение - я никогда не использую дешевые SSD диски от производителей типа SmartBuy и тому подобных. Я использую только диски от Samsung, Intel, Micron, Plextor, Transcend, Corsair.
Далее, представлены реальные примеры того, какой объем записи выполняется на системный диск SSD и как это соотносится с ресурсом записи.
Пример 1, срок жизни SSD диска Transcend 230S
Диск Transcend 230S, установлен в домашнем компьютере, работает в течении примерно 3 лет. Операционная система Windows 7. Кликните картинку для увеличения.


Счетчик записанного объема превышает 12 терабайт - примерно 4 терабайта в год.
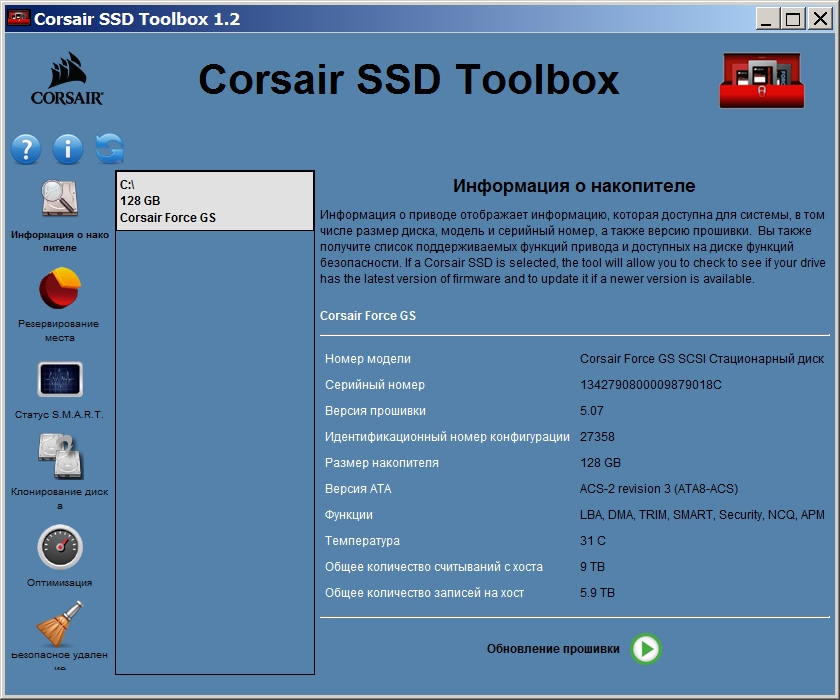
Пример 2, срок жизни SSD диска Corsair GS
Диск Corsair серия GS, установлен в рабочем компьютере бухгалтера, работает с 2013 года. Показания сняты в 2019 году. За это время на диск записано почти 6 терабайт - меньше 1 терабайта в год. Операционная система Windows 7. Кликните картинку для увеличения.
Пример 3, срок жизни SSD диска Samsung 860 Evo
Диск Samsung 860 Evo. Установлен в рабочем компьютере, работает полтора года. Операционная система Windows 7. Объем записи 2.3 Тб за полтора года. Кликните картинку для увеличения.

Пример 4, срок жизни SSD диска Plextor M5 Pro
Диск Plextor M5 Pro. Установлен в рабочем компьютере, работает больше 6 лет. Операционная система Windows XP, затем Windows 8. Объем записи немного более 5 Тб.

Пример 5, срок жизни SSD диска Intel 545s
Диск Intel 545s на 128 Гб. Ресурс записи этой модели заявлен в 72 терабайта.
Домашний компьютер. Операционная система Windows 7. Время работы, этого SSD диска, больше двух лет.
Кликните картинки для увеличения.


Как видно из скриншотов, за это время на диск было записано почти два терабайта. Даже если округлить до 1 терабайта в год, ресурса этого диска, в этом компьютере, должно хватить на 36 лет.
Пример 6, срок жизни SSD диска Kingston SV300s37A
Диск Kingston SV300s37A на 120 Гб. Ресурс записи этой модели заявлен в 64 терабайта.
Домашний компьютер. Операционная система Windows 8, затем Windows 10. Время работы, этого SSD диска, точно неизвестно. Может быть лет 5, но не больше 7 лет, поскольку эта модель выпущена в 2013 году.
Кликните картинки для увеличения.

В атрибуте 241 указано значение 15 643. У SSD Kingston одна единица этого счетчика равна 1 Гб. То есть на диск было записано более 15 терабайт. То есть примерно четверть от ресурса. При этом, родная программа пишет что здоровье этого диска равно 97 %.
Пример 7, срок жизни SSD диска Plextor PX-256M5S
Диск Plextor PX-256M5S на 256 Гб. Ресурс записи этой модели заявлен не известен - производитель такую информацию не предоставляет для этой модели. Предполагаю (исходя из данных по моделям M5pro), что ресурс записи, этой модели, как минимум более 70 Тб. А скорее всего более 100 терабайт.
Домашний компьютер. Операционная система Windows 7. Время работы, этого SSD диска, примерно 7 лет. С того момента как был собран этот компьютер в 2014 году. Схема использования типичная для домашнего компьютера - игры, Интернет и еще "всяко-разно". Размер оперативной памяти 4Гб, так что диск активно свопился всю свою жизнь.

Фирменная программа Plextool показывает максимальный уровень "здоровья" и объем записи 12 терабайт, за 7 лет.
Мониторинг и проверка состояния SSD в Linux
И снова здравствуйте. Перевод следующей статьи подготовлен специально для студентов курса «Администратор Linux». Поехали!

Проверьте свой SSD в Linux с помощью smartctl
До сих пор мы рассматривали данные, собранные во время нормальной работы накопителя. Однако протокол S.M.A.R.T. также поддерживает несколько команд для автономного тестирования для запуска диагностики по требованию.
Автономное тестирование может проводиться во время обычных операций с диском, если не было указано иное. Поскольку тест и запросы ввода-вывода хоста будут конкурировать, производительность диска упадет на время теста. Спецификация S.M.A.R.T. определяет несколько видов автономного тестирования:
Короткое автономное тестирование ( -t short )
Такой тест проверит электрическую и механическую, производительность, а также производительность чтения диска. Короткое автономное тестирование обычно занимает всего несколько минут (обычно от 2 до 10).
Расширенное автономное тестирование ( -t long )
Этот тест занимает почти в два раза больше времени. Как правило, это просто более детальная версия короткого автономного тестирования. Кроме того, этот тест будет сканировать всю поверхность диска на наличие ошибок данных без ограничения по времени. Продолжительность теста будет пропорциональна размеру диска.
Транспортировочное автономное тестирование ( -t conveyance )
Этот тестовый набор предложен в качестве сравнительно быстрого способа проверки на возможные повреждения, возникшие во время транспортировки устройства.
Вот примеры, взятые с тех же дисков, что были выше. Я предлагаю вам угадать, где какой:
Сейчас производится проверка. Давайте дождемся завершения, чтобы посмотреть результат:
Проведем тот же тест на другом диске:
И еще раз, отправим в сон на две минуты и посмотрим результат:
Интересно, что в этом случае мы видим, что производители диска и компьютера, похоже, уже тестировали диск (на времени жизни в 0 часов и 12 часов). Я сам определенно был гораздо менее озабочен состоянием диска, чем они. Итак, поскольку я уже показал быстрые тесты, то и расширенный тоже запущу, чтобы посмотреть как это происходит.
Судя по всему на этот раз ждать придется гораздо дольше, чем при проведении короткого теста. Так что давайте посмотрим:
В последнем тесте обратите внимание на различие в результатах, полученных с помощью короткого и расширенного теста, даже если они были выполнены один за другим. Ну, возможно, этот диск не в таком уж и хорошем состоянии! Отмечу, что тест остановился после первой ошибки чтения. Поэтому, если вы хотите получить исчерпывающую информацию обо всех ошибках чтения, вам придется продолжать тест после каждой ошибки. Я призываю вас взглянуть на одну очень хорошо написанную страницу руководства smartctl(8) для получения дополнительной информации о параметрах -t select , N-max и -t select , чтобы уметь делать так:
Читайте также: