
Tabular data control что это
Обновлено: 05.07.2024
Интернет, как всем известно, очень большой. Даже больше, чем ты подумал. И как там обстоят дела, мало кто знает. Покопавшись в такой «кладовке», можно найти много интересных штук. Ну и для всякой статистики бывает полезно посканить что-нибудь по-настоящему большое.
Что нам требуется для этого? Желание, абузоустойчивый хостинг, немного тулз и сколько-то времени. И конечно, перечень диапазонов IP.
И еще раз обойти SOP под Internet Explorer
Решение
Следующий трик основан на «полубаге». Как ты знаешь, SOP появился позже HTML’а, и у него есть ряд исключений. Так, картинки (тег img) мы можем свободно «таскать» с других сайтов. То же самое касается тега script. Мы можем указать путь в параметре src до скрипта на любом домене. Данный скрипт будет скачан и без проблем запущен, но уже в рамках нашего сайта.
Но есть исключения. Браузер может проверить Content-Type и при некорректном типе запретить исполнение JS. Плюс еще немного тонкостей.
Вообще, новых штук в этой области я давно не видел, но интересная находка была сделана в VBScript’е. Это некогда попытка MS создать конкурента для JavaScript, до сих пор счастливо существует в IE. И, соглашусь с Залевским, эта территория далеко еще не перекопана должным образом. Кто-то вообще занимался им глубоко? 🙂
Давай сначала покажу саму атаку, а потом ее разберем. Скрипт на нашей стороне:
Содержимое target.json — классический JSON Array (массив):
По коду все просто. В первом скрипте просто вешаемся на ивент для мониторинга появляющихся ошибок. А далее подключаем файл с атакуемого сервера.
Как думаешь, что произойдет?
Насколько я помню, такие баги были в браузерах лет пять назад… Да, мы получим доступ к данным, как к тексту возникшей ошибки «Несоответствие типа „secret, data, here“».
Здесь две причины. Во-первых, насколько я помню, IE не знает такого Content-Type, как application/json. Вроде только в IE11 добавили официально. Так как контент-тайп неизвестен, IE запускает процесс content-sniffing’а. Это такая технология (которая лет десять назад была актуальна из-за неразберихи с типами, веб-серверами и кодерами), по которой браузер различными способами пытается сам определить тип данных в получаемом ответе на запрос. У IE это анализ тела ответа и анализ расширения запрашиваемого файла (об этом я когда-то тоже писал). Во-вторых, ответ от сервера после некорректного определения его типа попадает в парсер VBScript’а. Далее все получается логично: парсер парсит, встречает первую ошибку, останавливается и возвращает ее.
На деле можно прочитать не только JSON массивы данных. Можно прочитать первую строку, цифру и так далее. Возможно, и еще что-то, но надо шарить в VBScript’е.
Замечу, что JSON-объект (те, что передаются в кривых скобках), прочитать не получится, так как в VBScript’е выражение не может начинаться с
Также интересный момент заключается в том, что это естественное поведение браузера и исправлять MS что-то не собираются.
Выход ли это за рамки спецификаций?
Если считать, что PPT, TDC и EDC являются основой спецификаций AMD для потребления мощности и тока, то да, это выходит за рамки спецификаций. Однако PPT по своей природе выходит за рамки TDP, поэтому тут мы уже попадаем в загадочный мир определений понятия «турбо».
Как мы уже обсуждали ранее касательно мира Intel, пиковое потребление энергии в режиме турбо Intel сообщает производителям материнских плат только в качестве «рекомендованного значения». В итоге чипы от Intel примут любое значение в качестве пикового энергопотребления, как разумные величины типа 200 Вт или 500 Вт, так и безумные, типа 4000 Вт. Чаще всего (и в зависимости от процессора), чип упирается в другие ограничения. Но в случае с самыми мощными моделями этот параметр стоит отслеживать. Значение тау, обозначающее длительность нахождения в режиме турбо, и определяющее объём ведра с энергией, из которого режим турбо её черпает, тоже можно увеличить. Вместо значения по умолчанию из диапазона от 8 до 56 секунд, тау можно увеличивать практически до бесконечности. Согласно Intel, всё это укладывается в спецификации – если производители материнских плат могут делать материнские платы, обеспечивающие все эти показатели.
Intel считает, что настройки выходят за рамки спецификаций, когда частота работы процессора выходит за пределы таблиц турбо режима для Turbo Boost 2.0 (или TBM 3.0, или Thermal Velocity Boost). Когда процессор выходит за эти пределы, Intel считает это разгоном, и считает себя свободной от выполнения гарантийных обязательств.
Проблема в том, что если попытаться перенести те же правила на ситуацию с AMD, то у AMD нет турбо-таблиц как таковых. Процессоры AMD работают, предлагая наибольшую возможную частоту в зависимости от ограничений по току и мощности в любой момент времени. При увеличении количества задействованных в работе ядер уменьшается энергопотребление каждого отдельного ядра, и вслед за ним и общая частота. И тут мы углубляемся в детали по отслеживанию огибающей частоты, и всё усложняется из-за того, что AMD может менять частоту шагами по 25 МГц в отличие от Intel, использующей шаги по 100 МГц.
Также AMD использует возможности, выводящие частоту работы чипа за пределы турбо-частоты, описанные в спецификации. Если вы считаете, что это разгон, и судите только по цифрам на коробке – тогда, да, это разгон. AMD в данном случае специально запутывает ситуацию, однако плюсом можно считать некоторое повышение быстродействия.
Tabular data control что это
Глава 4. РАБОТА С ЭЛЕМЕНТАМИ УПРАВЛЕНИЯ A ctive X
Когда без элемента ActiveX не обойтись
Действительно, бывают случаи, когда требуется воспользоваться объектом, который не отображается на Web -странице, тогда этот объект надо описать, т.е. задать ему параметры в кодах HTML . Например, необходимо отображать на Web -странице значения из полей базы данных, которая сформирована в виде текстового файла (Таблица.3) и находится либо на рабочем месте пользователя, либо на сервере.
Таблица 4. Сведения о сотрудниках
Для того чтобы такие сведения отобразить в браузере целесообразно воспользоваться стандартным элементом ActiveX – Tabular Data Control (работа с данными из таблиц). Такой элемент рассматривается как самостоятельный объект, имеющий ряд параметров, необходимых для взаимодействия программы с данными, которые находятся в файле data . txt . С позиции разработчика – требуется создать интерфейс для пользователя в виде Web -страницы, на которой будут отображаться записи из таблицы. Проект Web -страницы представлен на рис. 26, который содержит интерфейс пользователя с текстовыми окнами для отображения записей из базы данных и двух управляющих кнопок, позволяющих пролистывать записи в прямом и обратном направлениях. Наиболее простым способом для разработки HTML -кодов, является присоединение элемента ActiveX , который можно вызвать через редактор ActiveX Control Pad .

Рис. 26. Интерфейс пользователя для просмотра базы данных
После проведения поиска в диалоговом окне Insert ActiveX Control объекта Tabular Data Control (рис. 27), будет сформированы HTML – коды объекта, к которым остается добавить тэги для описания интерфейса пользователя и сценарий для управления просмотра данных с помощью двух командных кнопок.

Рис. 27. Отображение элемента ActiveX для просмотра табличных данных
Элемент ActiveX для просмотра табличных данных имеет множество свойств, которые следует назначать непосредственно в тех местах программных кодов HTML -страницы, которые имеют отношение к их использованию. Поэтому при формировании объекта Tabular Data Control в тэге < OBJECT …> располагается код объекта ( CLASSID ) и параметр ( VALUE ), которому разработчик назначает путь к исходному файлу с данными:
<OBJECT ID="Base1" CLASSID="CLSID:333C7BC4-460F-11D0-BC04-0080C7055A83">
Листинг 13 с программными кодами для обработки событий, при нажатии на кнопки, для программы отображения записей на экране будет выглядеть следующим образом:
Листинг 13.
<TITLE> Объект Data Control</TITLE>
Document.Base1.Recordset.MoveNext ' Обращение к текстовому файлу
If Document.Base1.Recordset.EOF Then ' Проверка конца файла
Document.Base1.Recordset.MoveLast ' Метод MoveLast - просмотр следующей записи
If Document.Base1.Recordset.EOF Then
<!-- Это коды и параметры объекта: Tabular Data Control -->
<PARAM NAME="DataURL" VALUE="Dop_files\DATA.TXT">
<!-- Используем записи из файла, которые связываются DATASRC (Имя объекта) и DATAFLD (Имя заголовка списка) -->
В программе командные кнопки имеют имена Kn 1 и Kn 2, которые связаны с программами на VBScript . В программе для первой кнопки используются методы: MoveNext (Переместить на следующую) и MoveLast (Переместить на последнюю), а для второй кнопки используются методы: MovePreviors (Переместить на предыдущую) и MoveFist (Переместить на первую). С помощью условного оператора if … then осуществляется проверка состояния просмотра записей в базе данных. Метод EOF (конец просмотра записи) позволяет прекратить цикл просмотра записей, когда найдена последняя. Метод BOF указывает на то, что мы находимся на начале записей в файле. Файл, созданный в приложении Блокнот ( data . txt ) довольно простой, его внешний вид представлен на рис. 28.

Рис. 28. Внешний вид записей в файле data . txt
Для просмотра примера встраивания элемента управления Data Control на HTML -страницу, достаточно нажать на гиперссылку: ПРИМЕР11.
Подвергается ли мой процессор опасности?
Сразу ответим на этот вопрос – нет, не подвергается. У обычных пользователей с достаточным уровнем охлаждения и на стоковых настройках в течение ожидаемого срока службы проекта никаких проблем быть не должно.
У большинства современных процессов х86 есть либо трёхгодовая гарантия для ритейл-версий в коробочках, либо годовая на ОЕМ. И хотя AMD и Intel не будут менять вам процессор по окончанию этого периода, ожидается, что большая часть процессоров будет работать не менее 15 лет. Мы до сих пор тестируем разные старые процессоры в старых материнских платах, несмотря на то, что их уже давно не обслуживают (и чаще всего проблема заключается во вздувшихся конденсаторах на материнской плате, а не в процессоре).
Когда с конвейера сходит подложка с процессора, компания получает отчёт о надёжности, что помогает определить потенциальное применение для этих процессоров. Сюда входят и такие показатели, как реагирование на изменение напряжения и частоты, а также подверженность электромиграции.
Кроме физического повреждения или перегрева при отключении предела нагрева, главным способом повредиться у современного процессора будет электромиграция. В этом процессе электроны пробираются через проводники процессора и сталкиваются с атомами кремния (и других элементов), в результате выбивая их из кристаллической решётки. Само по себе это редкое явление (вспомните, к примеру, как давно работает проводка в вашем доме), однако на мелких масштабах оно может влиять на работу процессора.
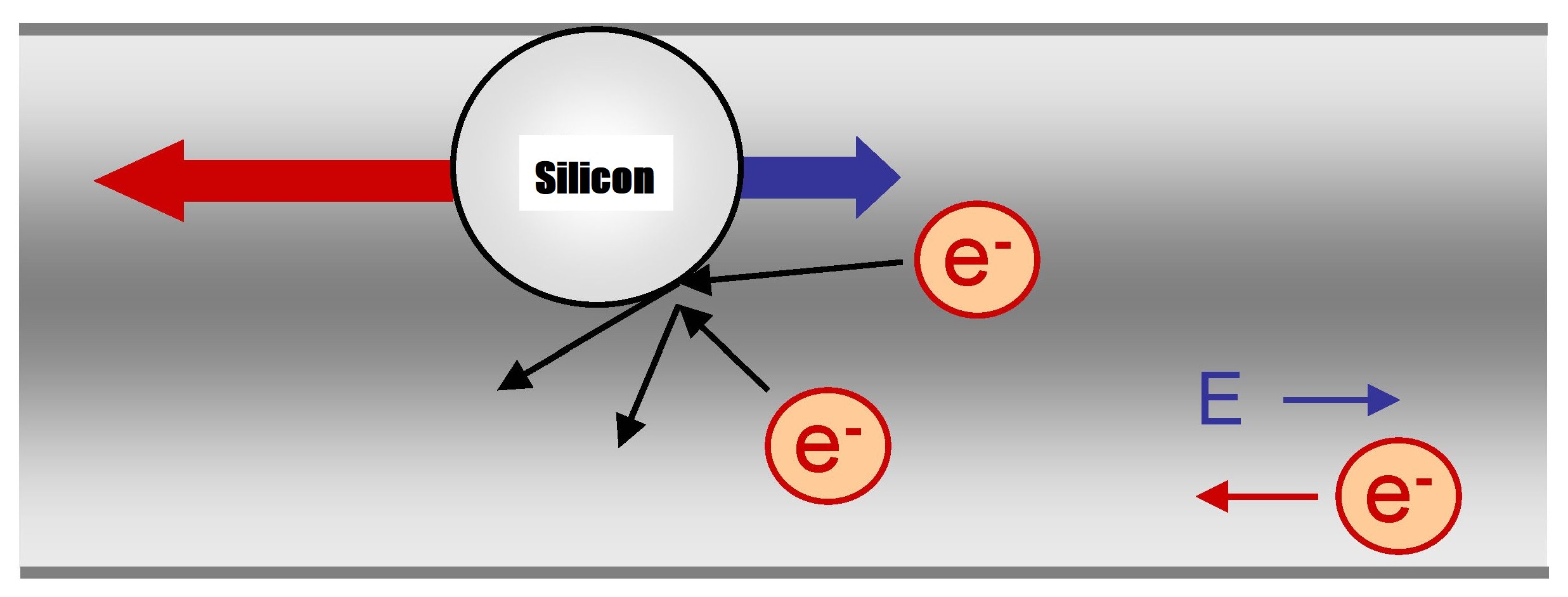
После смещения атома металла в проводнике с его места в кристаллической решётке сечение проводника в этом месте уменьшается. Это увеличивает его сопротивление, поскольку оно обратно пропорционально сечению. Если выбить достаточно атомов кремния, то проводник перестанет проводить ток, и процессор уже нельзя будет использовать. Этот процесс происходит и в транзисторах – там его называют старением транзистора, из-за чего транзистору с течением времени требуется всё большее напряжение («дрейф напряжения»).
При повышении напряжения (и энергии электрона) и плотности тока (электронов на площадь сечения) шансы электромиграции возрастают. При повышении температуры ситуация может ухудшиться. Все эти факторы влияют на то, сколько электронов могут запастись энергией, достаточной для осуществления электромиграции.
Неблагоприятный процесс, не правда ли? Раньше так и было. При постепенном усовершенствовании производственного процесса и схем работы логических вентилей производители применяли контрмеры, уменьшающие уровень электромиграции. При уменьшении характерных размеров и напряжения этот эффект также становится всё менее заметным – ведь площадь сечения проводников также уменьшается.
Довольно долго большая часть потребительской электроники не страдала от электромиграции. Единственный раз, когда я лично столкнулся с электромиграцией – это когда у меня был процессор Core i7-2600K Sandy Bridge 2011 года, который я разгонял на соревнованиях до 5,1 ГГц с использованием серьёзного охлаждения. В итоге он дошёл до такого состояния, что через пару лет работы ему для нормального функционирования требовалось большее напряжение.
Но тот процессор я гонял в хвост и гриву. Современное оборудование разработано так, чтобы работать десятилетие или более. Судя по отчётам, увеличение нагрева с увеличением энергопотребление оказывается не таким уж и большим. В отчёте Стилта указано, что процессор, видя наличие доступной мощности, немного увеличивает напряжение, чтобы получить прирост в 75 МГц, что увеличивает напряжение с 1,32 до 1,38 во время прогона теста CineBench R20. Пиковое напряжение, значимое для электромиграции, увеличивается всего лишь от 1,41 до 1,42. Общая мощность растёт на 25 Вт – нельзя сказать, что на порядок.
Так что, если моя материнская плата каким-то образом подстроит это воспринимаемое значение тока, не превратится ли мой процессор в кирпич? Нет. Если только у вас не будет каких-то серьёзных ошибок при сборке (например, в системе охлаждения). Всё предполагаемое время жизни продукта, и ещё лет десять после этого, вряд ли эта подстройка будет иметь какое-то значение. Как уже упоминалось, если бы даже это влияло на электромиграцию, то производители процессора встроили механизмы для того, чтобы противодействовать ей. Единственный способ следить за развитием электромиграции – это отслеживать средние и пиковые значения напряжения годами, и смотреть, подстраивает ли процессор автоматически эти параметры для компенсации.
Стоит отметить, что безразмерный показатель силы тока конечный пользователь подстраивать не может – им управляет материнская плата через обновления в BIOS. Если вы занимаетесь разгоном, то вы влияете на электромиграцию гораздо сильнее, чем эта подстройка. Если кто-то из вас беспокоится о температурных режимах, я думаю, что это как раз те люди, которые уже отслеживают и подстраивают пределы параметров в BIOS.
Старомодные способы: методы расширения спектра, мультиядерные улучшения, PL2
За время работы редактором по материнским платам, а потом и по CPU, я постоянно сталкиваюсь с ухищрениями, на которые производители материнок готовы идти ради того, чтобы вырваться вперёд по быстродействию в гонке с конкурентами. Мы первыми рассказали о такой настройке, как «мультиядерное улучшение» [MultiCore Enhancement], появившейся в августе 2012 года, и выставляющей рабочую частоту всех ядер выше той, что указана в спецификациях, а иногда и откровенно разгоняющей рабочую частоту. Однако производители материнских плат занимались подстройкой разных свойств, связанных с быстродействием, и задолго до этого. Можно вспомнить метод расширения спектра с увеличением базовой частоты со 100 МГц до 104,7 МГц, благодаря которому увеличивалось быстродействие на поддерживающих его системах.
В последнее время на платформах Intel видны попытки производителей по увеличению пределов мощности с тем, чтобы материнские платы выдерживали турборежим работы как можно дольше – и только потому, что производители материнских плат перестраховываются при разработке обеспечения питания компонентов. За последние пару недель мы обнаружили примеры того, как некоторые производители материнских плат просто игнорируют новые требования Intel Thermal Velocity Boost.
Короче говоря, каждый производитель материнских плат хочет быть лучшим, и для этого часто размываются пределы того, что считается «базовыми спецификациями» процессора. Мы довольно часто писали о том, что граница между «спецификациями» и «рекомендуемыми настройками» может быть размытой. Для Intel мощность в режиме турбо, указанное в документации, является рекомендуемой настройкой, и любое значение, установленное на материнских платах, технически укладывается в спецификации. Судя по всему, Intel считает разгоном только увеличение частоты режима турбо.
Реализация TDC в FPGA
С электронной точки зрения реализация задача сводится к «регистрированию положения» фронта сигнала относительно какого-либо синхросигнала. Элементы FPGA, имеющиеся в нашем распоряжении, это физически линии сигналов на кристалле, регистры, логические блоки, линии клока и PLL. Основные подходы к реализации TDC с использованием этих элементов были предложены относительно давно: субтактовая линия задержки (tapped delay line), линия задержки Вернье (Vernier delay line), «фазированные PLL». Но инженеры до сих пор работают над их усовершенствованием и имплементацией на современных платформах.
В нашей FPGA-шной реализации мы в основном следовали этой публикации, описывающей субтактовую линию задержки, а также некоторым общим идеям, почерпнутым в публикациях Jinyuan Wu из CERN`а 2000-x годов.

Вспоминаем устройство FPGA семейства Cyclone от компании Intel (Altera). Логические элементы (LE) сгруппированы в блоки (LAB), управляемые одной линией клока и соединены линиями переноса разряда (carry line). Это как раз нужная нам схема. То есть входной сигнал будем заводить на какой-нибудь LE и направлять его по линиям переноса разряда на соседние. При этом LE должны работать в арифметическом режиме. Тактировать все LE будем одним клоком и забирать термокод по появлению входного сигнала.
Теперь перед нами стоят несколько практических вопросов:
- Как описать схему линии задержки на Verilog?
- Как объяснить Quartus`у, что мы хотим использовать именно линии переноса и отключить их оптимизацию?
- Как сформировать линию задержки на соседних LE из одного LAB?
С точки зрения Quartus`а, линия задержки — штука бессмысленная. Зачем вести сигнал хитрым способом, если его сразу можно провести из точки A в точку B? Для того чтобы Quartus не пытался оптимизировать линию задержки, и результате выкинул составляющие ее LE, используем директиву /* synthesis keep = 1 */ напротив объявления элемента, к которому она относится. В результате основной код выглядит следующим образом:
Для указания на использование соседних LE и их размещения в конкретном месте на кристалле применим инструмент LogicLock Regions. То есть укажем на кристалле прямоугольную область и явно укажем набор LE, которые Quartus должен в ней разместить. На рисунке ниже область line содержит линию задержки, а область delay_line включает дополнительную логику обработки термокода.

Ниже приведем схему размещения элементов линии задержки из Chip Planner со схематическим отображением сигналов и детальную схему первых двух элементов линии задержки.

Отметим, что реализованная схема имеет мертвое время в один такт, необходимое для «сброса» регистров линии задержки.
Описанная схема была разложена на чипе Cyclone IV EP4CE22. Эксперименты с длиной линии задержки и частотой клока привели к следующим параметрам: длина линии задержки 64 LE, частота клока
120МГц. Линия задержки и логика обработки термокода умещаются в 42 LABs.
Warning!
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.
Начнем с конца. Как известно, не считая того, что перечень свободных диапазонов IPv4 кончился (то есть можно whois’ом узнать принадлежность любого из диапазонов), изначально диапазоны были разделены между регистраторами, что уже вносило территориальное разделение. Конечно, определенная степень погрешности есть, но фактически сейчас каждый диапазон «принадлежит» какой-то организации какой-то страны. И актуальные базы данных доступны бесплатно в интернете. Примеров масса: goo.gl/ezjgi9, worldips.info. Таким образом, мы можем «выдернуть» диапазоны какой-то страны и сканить их или сделать аналогичное по конкретной организации (здесь, правда, есть подводные камни, но об этом я уже писал в предыдущих номерах).
Почему не посканить весь инет — 0.0.0.0/0? Как минимум потому, что в данный диапазон попадает ряд специальных диапазонов (а-ля 127.0.0.1/8, 10.0.0.0/8, мультикасты и так далее), да и времени это займет много.
Далее — хостинг. Сканирование портов в зависимости от страны и провайдера может быть нежелательным, а то и незаконным действием. А если придется сканить что-то большое, то потребуется время, и это обязательно заметит провайдер и, возможно, примет меры. Конкретного совета не дам, лишь пара наблюдений. Между странами/континентами жалобы ходят реже/медленней (сканить Америку из Америки долго не получится, а вот даже из Европы — нормально). Крупные «игроки» обычно медлительней/либеральней меньших товарищей. Так, я больше года переписывался с индусами из Амазона, перед тем как они ввели хоть какие-то санкции на систематическое сканирование. Хотя тут все индивидуально. Например, Digital Ocean сначала заблочил акк и виртуалки, а потом стал разбираться, было ли это сканирование или еще что-то :).
Далее, тулзы и технологии. Конечно, чем сканить, сильно зависит от того, что мы хотим насканить. Если взять за основу сканирование портов, то можно взять и Nmap. Как ни странно, его можно настроить на приличный уровень скорости, и мы говорили об этом в прошлых номерах. Но все же лучше использовать более специализированные вещи, например ZMap или masscan. Оба сканера оптимизированы для быстрого сканирования крупных сетей:
- обработка TCP/IP-стека вынесена из ядра и реализована в пользовательском пространстве;
- запросы отправляются асинхронно (ПО не запоминает, куда и что было отправлено);
- общая оптимизация (один запрос на один порт) и допфичи (PF_RING).
Описывать, какой из них лучше, не буду. Могу лишь отметить, что ZMap более прост в использовании.
Несмотря на то что создатель masscan утверждает, что теоретически можно просканить весь интернет на один порт за несколько минут, фактически обнаруживается много подводных камней, влияющих либо на скорость, либо на точность информации.
Как ни странно, сканированием всего интернета (или его частей) люди занимаются систематически. А некоторые даже выкладывают итоги в Сеть. Так, веселый пример был в 2012 году, когда чел «похакал» с полмиллиона девайсов в интернете и заставил их просканить всю сеть на 700 портов (с детектом портов). Хаканье вроде как заключалось в небольшом подборе логина и пароля (root:root, admin:admin, без паролей и так далее). В итоге получилось 9 Тб общедоступных данных.
Компания Rapid7 (которая давно была известна сканированиями мира) наконец раскрыла свои данные и предложила проект Sonar. В рамках него она предоставила итоги сканирования десятка TCP- и UDP-портов (с баннерами — 2,4 Тб), обратные DNS PTR записи (50 Гб), данные SSL-сертификатов со всех 443 портов (50 Гб). А также предложила комьюнити делиться своими изысканиями и сканами. Так что у нас уже есть большая куча данных! Осталось теперь отпарсить и выискать интересуемое :).
Калибровка TDC
Очевидно, что физические задержки на каждом логическом элементе отличаются. Для учета этого факта необходимо провести калибровку устройства. Первым, что приходит в голову, видится подача на вход TDC сигнала с известным периодом. Однако такой путь является достаточно трудоемким, поскольку требуется прецизионное сканирование периода сигнала в относительно широком диапазоне.
Следующим предложением является калибровка методом случайных событий: подаем на вход сигналы с равномерно распределенными случайными задержками и наблюдаем гистограмму попадания событий в тайм-бины. В этом случае точность растет по мере накопления событий как , где N — число поданных событий. Мы же воспользуемся методом коррелированных событий. В этом методе точность ограничена изначально и может быть достигнута сравнительно небольшим числом измерений.
Суть способа в подборе частоты генерации событий, при которой они будут равномерно распределены в тайм-бинах. Для этого необходимо удовлетворить соотношению:
где N — число событий, которые мы хотим равномерно распределить в временном интервале T1, 1/T2 — частота генерации событий, — дробная часть числа.
При этом сигналы могут быть сформированы внутренним PLL. В нашем примере входная частота PLL равна 50МГц и для числа событий N = 256 мы выбрали следующие рабочие частоты:
- 1/T1 = 50МГц * 93/40 = 116.26МГц: частота клока TDC
- 1/T2 = 50МГц * 32/285 = 5.614МГц: частота генерации событий
Процедура калибровки заключается в многократном измерении непрерывной последовательности из 256 событий. В нашем эксперименте общее число измеренных событий равно 8192. Полученная в результате гистограмма соответствует доле отдельных элементов задержки в одном такте TDC.

На верхнем графике приведено распределение отсчетов по элементам линии задержки. Номер отсчета следует понимать как границу между единицами и нулями в скорректированном термокоде. Провал на 45-м элементе линии задержки соотвует одновременному срабатыванию двух соседних элементов, что является характерным для подобной реализации (bubble error [Wu08]). Положение провала зависит от области размещения линии задержки на кристалле. При увеличении числа регистрируемых событий не происходит существенного изменения распределения отсчетов.
На нижнем графике приведена калибровочная кривая, сопоставляющая номер интервала с длительностью задержки. Сумма всех отсчетов по тайм-бинам соответствует времени T1 = 8.6нс. Перевод номера бина во временные интервалы может осуществляться непосредственно в кристалле или с помощью программируемого процессора Nios II.
Далее приведены абсолютные временные интервалы соотвующие элементам линии задержки с существенным числом срабатываний и распределение интервалов. Среднее значение интервала равно 160 ps, дисперсия времен — 31 ps. В результате, можно утверждать, что достигнутое разрешение времяизмерительной системы составляет
200 ps. Чтобы почувствовать это число отметим, что оно соответствует частоте 5ГГц. И это только самая простая реализация в FPGA не на самом последнем кристалле!
Почему повышение тока на AMD Ryzen не убьёт ваш процессор

Если кто-то хочет повысить быстродействие CPU, обычно он находит способ сделать это. Будь то пользователь, самостоятельно разгоняющий свой компьютер, или же производители материнских плат, подстраивающие настройки для улучшения быстродействия ЦП ещё перед продажей – в итоге всем хочется увеличить быстродействие, и по множеству причин. Эта ненасытная жажда максимального быстродействия означает, однако, что некоторые из этих подстроек и изменений могут вывести ЦП за пределы «спецификаций». В итоге часто можно видеть методы, выполняющие обещания по увеличению скорости работы за счёт увеличения температуры или сокращения времени жизни железа.
В этой связи стоит рассмотреть появившуюся недавно информацию о том, что производители материнских плат играют с настройками тока, подаваемого на процессоры от AMD. Увеличивая его, они увеличивают и потенциальную мощность процессора, что в итоге приводит к увеличению не только скорости работы, но и температуры. Такой подход к подстройке железа нельзя назвать новым, однако недавние события вызвали волну замешательства, вопросов о том, что происходит на самом деле, и какие последствия это может повлечь для процессоров AMD Ryzen. Чтобы прояснить эту ситуацию, мы решили сделать данный обзор.
Обойти SOP под Internet Explorer еще раз
Решение
Перейдем к двум другим примерам. Они достаточно новы: были представлены не так давно на конференции OWASP AppSec 2014 знаменитым хакером Ёсукэ Хасэгавой (Yosuke Hasegawa). Они на самом деле и просты, и угарны.
Первая фича основана на одном из компонентов ActiveX. Возможно, это покажется странным, но IE из коробки имеет приличный перечень активиксов, причем со свободным использованием их (нет ограничения по доменам, Safe for scripting, safe for init). Отказываться от этой подозрительной технологии они не собираются, да и не могут из-за обратной совместимости. И я не уверен, что все компоненты были копаны-перекопаны. Ведь на уровне ActiveX имеются возможности нарушать SOP, если потребуется.
Волнующий нас компонент — это Tabular Data Control (tdc.ocx, ). С его помощью мы получаем мини базу данных. Мы можем указать, где на сервере хранится информация (обычно в формате, похожем на CVS), как необходимо разбивать данные на поля и впоследствии иметь возможность доступа, отображения, сортировки полученных данных, как в таблице. Компонент появился аж в 4-й версии IE (хо-хоу, еще в прошлом веке!), а на сайте MS висит просьба не удалять его из новых версий, так как у кого-то приложения построены на этом компоненте… Самое интересное для нас — можно получать данные и с других сайтов (ориджинов).
Здесь мы инициализируем ActiveX, в DataURL указываем путь до файла. В функции show просто вытаскиваем данные. Yosuke указал в презентации необходимость в первой строчке, но, насколько я знаю, это если и необходимо, то только для IE11.
К сожалению, есть одно приличное ограничение для нас. Дабы сымитировать SOP, в компонент добавили требование — при доступе к файлам на другом сайте необходимо, чтобы в начале файла находилась следующая строчка: «@!allowdomains=имядомена», звездочки тоже работают (@!allow_domains=*). Имя домена, как ты понимаешь, — это место, откуда мы пытаемся сделать запрос.
Конечно, это сильно ограничивает наши возможности по краже данных, но без этого дыра была бы просто огромна. Таким образом, данные получится увести, только если мы можем контролировать первую строчку запрашиваемого файла. Не очень часто, но ситуации такие встречаются.

Опасненький ActiveX. Есть все нужные разрешения
Причем заметь, они именно попытались имитировать SOP. Если файл хранится на том же домене, то первая строчка не нужна. Но подробности сверки доменов или протокола, не говоря уж о портах, неизвестны. Отмечу еще, что защититься на серверной стороне (если строчка все же может быть добавлена) непросто, так как ActiveX-компонент не воспринимает ни Content-Type, ни Content-Disposition.
Повысить привилегии в Windows через USB
Решение
Новые технологии — дело хорошее и полезное. А в нашей сфере они появляются с неимоверной скоростью, прям-таки размножение почкованием. Есть покрупнее и позаметнее (как HTLM5), а есть поменьше. И в современных серьезных проектах получается все большее и большее сплетение их. Но почти каждая технология как-то сказывается на информационной безопасности. Причем для крупных проектов становится трудно понять и просчитать все возможные последствия. Сейчас мы увидим это на небольшом примере.
Винда — она большая, и понятно, что уязвимости в ней систематически находят, хотя надо признать, что удаленные RCE уже редкость.
Одним из векторов атак на повышение привилегий всегда были разнообразные драйверы для оборудования. Это же касалось и USB. USB-порты есть на всех современных компьютерах, доступ к ним тоже, и было много ребят, которые пофаззили это дело. Итогом был ряд уязвимостей (как минимум DoS). Но микрософт не особо обращал на это дело внимание, не считал это дырами, так как для эксплуатации требовался физический доступ к хосту, возможность подключить к USB-порту свой девайс. А это, в свою очередь, нарушало одно из десяти правил ИБ (10 Immutable Laws of Security), которыми руководствуется MS. Но теперь кое-что изменилось.
Я думаю, каждому из нас знаком протокол RDP (Remote Desktop Protocol), который используется для удаленного доступа к винде. MS последние годы значительно расширяла его возможности. Они добавили возможности проброса периферийных устройств с клиента на сервер, serial-портов, возможность монтирования клиентских дисков. И казалось бы — вот теперь мы можем эксплуатировать баги удаленно! Подключаемся удаленно к серверу по RDP, «втыкаем» устройство в свой порт, прокидываем его и получаем повышение привилегий, например. Но нет, можно было пробрасывать только определенный набор устройств, причем это происходило на высоком уровне, после обработки драйверами на клиентской машине. Таким образом, проводить низкоуровневые атаки через USB было невозможно…
Но мир не стоит на месте, и Microsoft продолжает развивать RDP и службы терминалов. И в последних версиях серверной винды (Win 2008 R2 SP1, Win 2012) они добавили новую технологию — RemoteFX. На самом деле это не одна технология, а целый набор. Насколько я понимаю, своей целью Microsoft ставит устранить ограничения при использовании удаленного терминального доступа (когда он осуществляется с «тонкого» клиента) по сравнению с локальным пользованием компьютером. Так, с помощью RemoteFX имеется возможность работать с видео высокого разрешения, с 3D-графикой. Часть RemoteFX касается VoiceIP и поддержки мультитача. ИМХО, очень круто, с учетом роста количества планшетов и смартфонов такая технология будет очень востребована.
Но для нашей задачи самым интересным, конечно, будет «RemoteFX USB Redirection». Я думаю, что ты уже все понял. Она дает возможность низкоуровневого проброса USB на сервер. С помощью этой фичи пользователи могут пробросить на сервер любое USB-устройство. На клиенте даже не надо ставить дрова устройства, сразу на сервере. А мы же можем проводить наши атаки.
Пример такой атаки, да и сама идея эксплуатации через RemoteFX, были показаны на Black Hat 2014 Asia Энди Дэвисом (Andy Davis).

Включаем RemoteFX на клиенте
С серверным же состоянием «по умолчанию» пока не ясно до конца. Вроде как все зависит от режима (роли) запуска терминального сервиса. Если это «стандартный» RDP — Remote Desktop Session Host, то отключено, а если Remote Desktop Virtualization Host (который используется для виртуализированных Hyper-V хостов) — включено.

Обычное перенаправление устройств в RDP
Кстати, если тебя интересуют какие-то виды атак или технологии, о которых бы ты хотел узнать, либо ты хочешь исследовать что-то, поднять пентестерские скиллы — пиши на почту.
Подстройка материнских плат с разъёмом AM4
Теперь мы переходим к новостям – производители материнских плат пытаются подстроить материнские платы Ryzen так, чтобы выжать из них больше быстродействия. Как подробно объяснялось на форумах HWiNFO, у платформ АМ4 обычно есть три ограничения: Package Power Tracking (PPT), обозначающее максимальную мощность, которую можно подавать на разъём; Thermal Design Current (TDC), или максимальный ток, подводимый к регуляторам напряжения в рамках тепловых ограничений; Electrical Design Current (EDC), или максимальный ток, который в принципе может подаваться на регуляторы напряжения. Некоторые из этих показателей сравниваются с метриками, получаемыми внутри процессора или снаружи, в сети подачи питания, с целью проверки превышения пороговых значений.
Чтобы подсчитать параметры программного управления питанием, с которым сравнивается РРТ, сопроцессор управления питанием получает значение тока от управляющего контроллера регулятора напряжения. Это не реальное значение силы тока, а безразмерная величина от 0 до 255, где 0 – это 0 А, а 255 – максимальное значение тока, которое может обработать модуль регулятора напряжения. Затем сопроцессор управления питанием проводит свои подсчёты (мощность в ваттах = напряжение в вольтах, умноженное на ток в амперах).
Этот безразмерный диапазон нужно калибровать для каждой материнской платы, в зависимости от её схемы и используемых компонентов – а также дорожек, слоёв и качества в целом. Чтобы получить точное значение коэффициента масштаба, производитель материнских плат должен тщательно замерить правильные показатели, а потом написать прошивку, которая будет использовать эту таблицу в подсчётах мощности.
Это означает, что в принципе существует способ поиграться с тем, как система интерпретирует пиковую мощность процессора. Производители материнских плат могут уменьшать это безразмерное значение тока, чтобы процессор и сопроцессор управления питанием считали, что на процессор подаётся меньше мощности, и в итоге ограничитель PPT не активировался. Это позволяет процессору работать в режиме турбо, превосходящем то, что изначально планировали в AMD.
У этого есть несколько последствий. Процессор будет потреблять больше энергии, в основном в виде увеличения тока. Это приведёт к повышению теплоотдачи. Поскольку процессор работает быстрее (потребляя больше энергии, чем считает ПО), он покажет лучшие результаты в тестах на быстродействие.
Если у вашего процессора базовая TDP 105 Вт, а PPT равняется 142 Вт, то при нормальных условиях стоит ожидать, что на заводских настройках процессора будет рапортовать о потреблении 142 Вт. Однако если установить безразмерный показатель тока на 75% от реального, то реально он будет потреблять в районе 190 Вт = 142/0,75. Если остальные ограничения не затронуты, то процессор будет рапортовать о 75% от PPT, что будет запутывать пользователя.
Преобразователи Time-To-Digital (TDC): что это такое и как они реализованы в FPGA

На рисунке — первый в мире спутник квантовой связи «Мо-Цзы», который запустили из Китая в 2016 году, в нем летает TDC, реализованная в FPGA.
Объяснить своей девушке (или парню), что такое ADC и DAC, и в каких домашних приборах они используются, может каждый человек, называющий себя инженером. А вот что такое TDC, и почему у нас дома их нет, зачастую можно узнать только после свадьбы.
TDC — это time-to-digital converter. По-русски говоря: времяизмерительная система.
Основные потребители быстродействующих TDC — научные группы. Как правило, под определенный исследовательский проект требуется что-то очень специфическое. То каналов надо много, то разрешение очень высокое, то исполнение компактное. А уровень развития современных FPGA и их доступность как раз дают исследователям возможность экспериментировать с реализациями и подстраивать их под собственные нужды.
В этой хабрастатье приводится детальное описание простенькой времяизмерительной системы на FPGA Cyclone IV. Статья будет полезна не только для расширения кругозора, но и с методической точки зрения, поскольку реализация системы нетривиальная.
Сразу отметим, что пришедшая на ум мысль «Да о чем они тут пишут? Считываем по событию счетчик/таймер CPU/MCU и дело в шляпе» тут не годится. Дело в том, что в приложениях требуется точность на порядок большая, чем могут обеспечить «стандартные» счетчики, а также детерминированная латентность, многоканальность и большая «пропускная способность событий».
Формально задача, которую решает TDC, — определение временного интервала между событиями. В многоканальных системах логика верхнего уровня дополнительно может вычислять корреляции между событиями. В качестве события, как правило, выступает срабатывание какого-либо детектора частиц или оптического датчика. В быту, конечно, такие системы не находят применения. И вообще, в масштабе пикосекунд имеет смысл измерять физические процессы, протекающие в сравнимых временах, например, пролет элементарных частиц в детекторе. Отметим некоторые направления применения TDC:
- Масспектроскопия, позитронно-эмиссионная томография (ПЭТ) — регистрируются времена прихода частиц на детекторы.
- ЛИДАРы — по временным отсчетам определяется расстояние до облученной области.
- Квантовая криптография — регистрируются времена срабатывания детекторов одиночных фотонов.
- Генерация случайных чисел — времена наступления событий используются в качестве энтропии.

Обойти SOP под Internet Explorer
Решение
Как ты, надеюсь, знаешь, SOP (Same Origin Policy) — одна из главных основ безопасности веба. Если сильно упростить, то взаимодействие между сайтами (ориджинами) в рамках браузера строго ограничено. Простейший пример: с помощью яваскрипта, загруженного с сайта Х, мы можем послать запрос на любой другой сайт, но получить ответ браузер нам даст, только если этим сайтом был Х.
По различным причинам SOP не представляет собой набор строгих правил, которые все соблюдают. Для различных технологий, имплементаций он может значительно отличаться. Microsoft, в силу бородатости и извращенности IE, здесь также выделяется на фоне других браузеров.
Сразу скажу, что там не все так плохо и «поломать весь веб» нам не удастся, но вкусности, которые помогут в трудную минуту, имеются. О некоторых из них мы и поговорим. Сразу упомяну, что, несмотря на падение количества пользователей, юзающих ИЕ (а следовательно, и потенциального импакта специфичных уязвимостей), общий процент их все же больше пятидесяти, а в корпоративном секторе так еще выше (до сих пор де-факто это стандарт). Для удобства я их разбил на несколько задачек.
Все достаточно четко и просто, хотя и рождает ряд проблем для разрабов. Все браузеры придерживаются данной практики, за исключением Internet Explorer, как ты мог догадаться. Данный браузер пренебрегает номером порта — только протокол и домен. К чему это приводит? Например, в приведенном примере про отправку запросов IE разрешил бы нам получать ответы на запросы, посылаемые нами на тот же хост, но на другие порты.
Был случай на практике. У крупной корпоративной системы наружу торчало несколько веб-серверов (на разных портах). Один — главный с основным порталом, на который ходили пользователи, и несколько дополнительных административных. Так вот, в одном из админских сервисов была найдена хранимая XSS’ка. Им никто не пользовался, поэтому импакт был близким к нулю. Но, зная о специфике IE (о которой не знали разрабы), мы получили возможность атаковать пользователей основного портала. Наша XSS «на кривом порту» превратилась в приличную уязвимость всей системы.
Из практики могу сказать, что если в инете такие случаи редки (с несколькими веб-серверами/портами на одном домене), то в корпоративных сетях это распространенная ситуация.
Какие у меня есть варианты?
Если ваша материнская плата пытается выжать из процессора больше, чем надо, однако вас устраивает температурный режим и энергопотребление компьютера, то просто наслаждайтесь дополнительным быстродействием. Даже если это всего лишь дополнительные 75 МГц.
С AMD это никак не связано, поскольку вся ответственность ложится на производителей материнских плат. Пользователи могут захотеть обратиться к производителю материнских плат и попросить прислать обновление для BIOS. Если пользователь захочет вернуть такую материнскую плату в магазин, ему нужно уточнить этот вопрос у продавца.
Хотя такое поведение вроде бы нарушает спецификации PPT, на самом деле оно не выходит за (плохо обозначенные) пределы частот. Эта ситуация похожа на то, как производители материнских плат играются с ограничениями мощности на системах от Intel. Однако, возможно, было бы приятно иметь в BIOS опцию, которая позволяла бы включать и выключать такое поведение.
Как узнать, занимается ли этим моя материнская плата
Во-первых, нужно использовать стоковую систему. Если параметры PPT/TDC/EDC изменены, то система уже подстроена по-другому, поэтому сконцентрируемся только на тех пользователях, которые работают со стоковыми системами.
Затем нужно установить последнюю версию HWiNFO и тест, загружающий систему на 100%, к примеру, CineBench R20.
В HWiNFO есть метрика под названием CPU Power Reporting Deviation [отклонение энергопотребления процессора]. Наблюдайте за этим числом, когда система находится под нагрузкой. У нормальной материнской платы число будет равно 100%, а у материнской платы с подстроенным током или регуляторами напряжения этот показатель будет меньше 100%.

- Ваш AMD Ryzen работает на полностью заводских настройках, установленных в BIOS. Никаких настроек в ОС и изменения ограничений по энергопотреблению или току.
- Когда ваш процессор загружен на 100%.
Если это не так, то значение параметра Power Reporting Deviation ничего не значит. Если же эти условия выполнены, а показатель падает ниже 100%, то ваша материнская плата изменяет работу процессора.
Читайте также: