
Как обучить модель yolo
Обновлено: 05.07.2024

Нейросетевые модели обнаружения объектов делают много полезного. Классифицируют автомобили, определяют злокачественные образования на медицинских изображениях, сегментируют объекты со спутниковых снимков. Тем не менее, одно из серьёзных препятствий, мешающих новым применениям – проблема адаптации доступных ресурсов и моделей к нестандартным задачам.
В этой публикации мы расскажем, как подготовить собственный набор данных для обнаружения необходимых объектов и провести обучение на модели распознавания YOLO.
Наш план. Работа с проблемой машинного обучения начинается с правильно сформулированной задачи. Далее вы собираете и подготавливаете данные, обучаете и корректируете модель, пока, наконец, не получите результат – распознавание необходимых объектов. Процесс может и не быть таким линейным. Например, вы можете обнаружить, что модель работает плохо на одном типе меток изображения. Тогда нужно вернуться к сбору большего количества данных для этой категории.
Распознавание объектов с помощью YOLO v3 на Tensorflow 2.0

До Yolo большинство подходов к распознаванию объектов заключалось в попытках адаптировать классификаторы к распознаванию. В YOLO, распознавание объектов было реализовано как задача регрессии к раздельным ограничивающим рамкам, с которыми связаны вероятности принадлежности к разным классам. Ниже мы познакомимся с моделью распознавания объектов YOLO и методом ее реализации в Tensorflow 2.0.
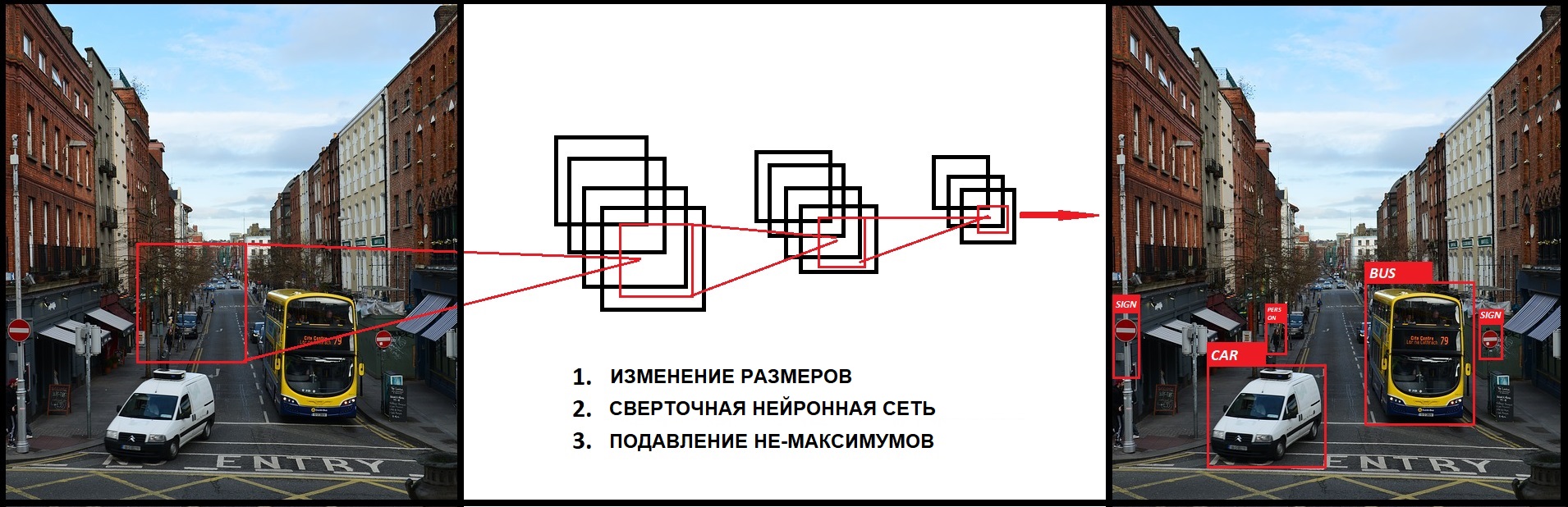
Заключение
Использование модели в производстве ставит вопрос о том, какой будет ваша производственная среда. Например, будете ли вы запускать модель в мобильном приложении, через удалённый сервер или на Raspberry Pi. То, как вы будете использовать модель, определяет наилучший способ хранения и преобразования форматов.
Обнаружение объектов с помощью YOLOv3 на Tensorflow 2.0

До появления YOLO большинство способов обнаружения объектов пытались адаптировать классификаторы для детекции. В YOLO же, обнаружение объектов было сформулировано как задача регрессии на пространственно разделенных ограничивающих рамок (bounding boxes) и связанных с ними вероятностей классов.
В данной статье мы узнаем о системе YOLO Object Detection и как реализовать подобную систему в Tensorflow 2.0
О YOLO:
Наша унифицированная архитектура чрезвычайно быстра. Базовая модель YOLO обрабатывает изображения в режиме реального времени со скоростью 45 кадров в секунду. Уменьшенная версия сети, Fast YOLO, обрабатывает аж 155 кадра в секунду…
— You Only Look Once: Unified, Real-Time Object Detection, 2015
Что такое YOLO?

YOLO – это новейшая (на момент написания оригинальной статьи) система (сеть) обнаружения объектов. Она была разработана Джозефом Редмоном (Joseph Redmon). Наибольшим преимуществом YOLO над другими архитектурами является скорость. Модели семейства YOLO исключительно быстры и намного превосходят R-CNN (Region-Based Convolutional Neural Network) и другие модели. Это позволяет добиться обнаружения объектов в режиме реального времени.
На момент первой публикации (в 2016 году) по сравнению с другими системами, такими как R-CNN и DPM (Deformable Part Model), YOLO добилась передового значения mAP (mean Average Precision). С другой стороны, YOLO испытывает трудности с точной локализацией объектов. Однако в новой версии были внесены улучшения в скорости и точности системы.
Альтернативы (на момент публикации статьи): Другие архитектуры в основном использовали метод скользящего окна по всему изображению, и классификатор использовался для определенной области изображения (DPM). Также, R-CNN использовал метод предложения регионов (region proposal method). Описываемый метод сначала создает потенциальные bounding box’ы. Затем, на области, ограниченные bounding box’ами, запускается классификатор и следующее удаление повторяющихся распознаваний, и уточнение границ рамок.
YOLO переосмыслила задачу обнаружения объектов в задачу регрессии. Она идет от пикселей изображения к координатам bounding box’ов и вероятностей классов. Тем самым, единая сверточная сеть предсказывает несколько bounding box’ов и вероятности классов для содержания этих областей.
Теория
Так как YOLO необходимо только один взгляд на изображение, то метод скользящего окна не подходит в данной ситуации. Вместо этого, изображение будет поделено на сетку с ячейками размером S x S . Каждая ячейка может содержать несколько разных объектов для распознавания.
Во-первых, каждая ячейка отвечает за прогнозирование количества bounding box’ов. Также, каждая ячейка прогнозирует доверительное значение (confidence value) для каждой области, ограниченной bounding box’ом. Иными словами, это значение определяет вероятность нахождения того или иного объекта в данной области. То есть в случае, если какая-то ячейка сетки не имеет определенного объекта, важно, чтобы доверительное значение для этой области было низким.
Когда мы визуализируем все предсказания, мы получаем карту объектов и упорядоченных по доверительному значению, рамки.

Во-вторых, каждая ячейка отвечает за предсказание вероятностей классов. Это не говорит о том, что какая-то ячейка содержит какой-то объект, только вероятность нахождения объекта. Допустим, если ячейка предсказывает автомобиль, это не гарантирует, что автомобиль в действительности присутствует в ней. Это говорит лишь о том, что если присутствует объект, то этот объект скорее всего автомобиль.
Давайте подробней опишем вывод модели.
В YOLO используются anchor boxes (якорные рамки / фиксированные рамки) для прогнозирования bounding box’ов. Идея anchor box’ов сводится к предварительному определению двух различных форм. И таким образом, мы можем объединить два предсказания с двумя anchor box’ами (в целом, мы могли бы использовать даже большее количество anchor box’ов). Эти якоря были рассчитаны с помощью датасета COCO (Common Objects in Context) и кластеризации k-средних (K-means clustering).

У нас есть сетка, где каждая ячейка предсказывает:
Для каждого bounding box'а:
1 objectness error (ошибка объектности), которая является показателем уверенности в присутствии того или иного объекта
Некоторое количество вероятностей классов
Если же присутствует некоторое смещение от верхнего левого угла на cx , cy то прогнозы будут соответствовать:
где pw (ширина) и ph (высота) соответствуют ширине и высоте bounding box'а. Вместо того, чтобы предугадывать смещение как в прошлой версии YOLOv2, авторы прогнозируют координаты местоположения относительно местоположения ячейки.
Этот вывод является выводом нашей нейронной сети. В общей сложности здесь S x S x [B * (4+1+C)] выводов, где B – это количество bounding box'ов, которое может предсказать ячейка на карте объектов, C – это количество классов, 4 – для bounding box'ов, 1 – для objectness prediction (прогнозирование объектности). За один проход мы можем пройти от входного изображения к выходному тензору, который соответствует обнаруженным объектам на картинке. Также стоит отметить, что YOLOv3 прогнозирует bounding box'ы в трех разных масштабах.
Теперь, если мы возьмем вероятность и умножим их на доверительные значения, мы получим все bounding box'ы, взвешенные по вероятности содержания этого объекта.
Простое нахождение порогового значения избавит нас от прогнозов с низким доверительным значением. Для следующего шага важно определить метрику IoU (Intersection over Union / Пересечение над объединением). Эта метрика равняется соотношению площади пересекающихся областей к площади областей объединенных.

После этого все равно могут остаться дубликаты, и чтобы от них избавиться нужно использовать “подавление не-максимумов” (non-maximum suppression). Подавление не-максимумов заключается в следующем: алгоритм берёт bounding box с наибольшей вероятностью принадлежности к объекту, затем, среди остальных граничащих bounding box'ов с данной области, возьмёт один с наивысшим IoU и подавляет его.
Ввиду того, что все делается за один прогон, эта модель будет работать почти также быстро, как и классификация. К тому же все обнаружения предсказываются одновременно, что означает, что модель неявно учитывает глобальный контекст. Проще говоря, модель может узнать какие объекты обычно встречаться вместе, их относительный размер и расположение объектов и так далее.

Yolov3
Мы также рекомендуем прочитать следующие статьи о YOLO:
Реализация в Tensorflow
Первым шагом в реализации YOLO это подготовка ноутбука и импортирование необходимых библиотек. Целиком ноутбук с кодом вы можете на Github или Kaggle:
Следуя этой статье, мы сделаем полную сверточную сеть (fully convolutional network / FCN) без обучения. Для того, чтобы применить эту сеть для определения объектов, нам необходимо скачать готовые веса от предварительно обученной модели. Эти веса были получены от обучения YOLOv3 на датасете COCO (Common Objects in Context). Файл с весами можно скачать по ссылке официального сайта.
По причине того, что порядок слоев в Darknet (open source NN framework) и tf.keras разные, то загрузить веса с помощью чистого функционального API будет проблематично. В этом случае, наилучшим решением будет создание подмоделей в keras. TF Checkpoints рекомендованы для сохранения вложенных подмоделей и они официально поддерживаются Tensorflow.
На этом же этапе, мы должны определить функцию для расчета IoU. Мы используем batch normalization (пакетная нормализация) для нормализации результатов, чтобы ускорить обучение. Так как tf.keras.layers.BatchNormalization работает не очень хорошо для трансферного обучения (transfer learning), то мы используем другой подход.
В каждом масштабе мы определяем 3 anchor box'а для каждой ячейки. В нашем случае если маска будет:
0, 1, 2 – означает, что будут использованы первые три якорные рамки
3, 4 ,5 – означает, что будут использованы четвертая, пятая и шестая
6, 7, 8 – означает, что будут использованы седьмая, восьмая, девятая
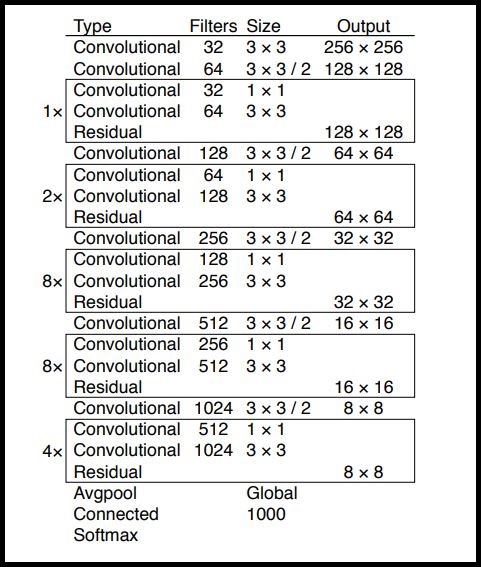
Теперь пришло время для реализации YOLOv3. Идея заключается в том, чтобы использовать только сверточные слои. Так как их здесь 53, то самым простым способом является создание функции, в которую мы будем передавать важные параметры, меняющиеся от слоя к слою.
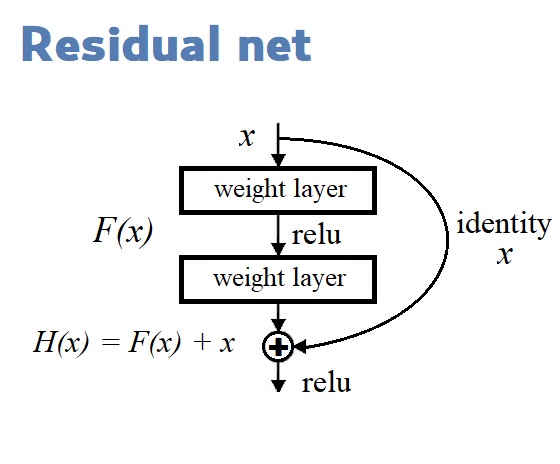
Остаточные блоки (Residual Blocks) в диаграмме архитектуры YOLOv3 применяются для изучения признаков. Остаточный блок содержит в себе несколько сверточных слоев и дополнительные связи для обхода этих слоев.

Создавая нашу модель, мы строим нашу модель с помощью функционального API, который будет легко использовать. С его помощью мы можем без труда определить ветви в нашей архитектуре (ResNet Block) и делить слои внутри архитектуры.
Теперь определим функцию подавления не-максимумов.
Функция "преобразовать цели" возвращает кортеж из форм:
Где N – число меток в пакете, а число 6 означает [x, y, w, h, obj, class] bounding box'а.
Теперь мы можем создать нашу модель, загрузить веса и названия классов. В COCO датасете их 80.

В этой статье мы поговорили об отличительных особенностях YOLOv3 и её преимуществах перед другими моделями. Мы рассмотрели способ реализации с использованием TensorFlow 2.0 (TF должен быть не менее версией 2.0).
Что такое YOLO?
YOLO – это передовая сеть для распознавания объектов (object detection), разработанная Джозефом Редмоном (Joseph Redmon). Главное, что отличает ее от других популярных архитектур – это скорость. Модели семейства YOLO действительно быстрые, намного быстрее R-CNN и других. Это значит, что мы можем распознавать объекты в реальном времени.
Во время первой публикации (в 2016 году) YOLO имела передовую mAP (mean Average Precision), по сравнению с такими системами, как R-CNN и DPM. С другой стороны, YOLO с трудом локализует объекты точно. Тем не менее, она обучается общему представлению объектов. В новой версии как скорость, так и точность системы были улучшены.
Другие подходы в основном использовали метод плавающего над изображением окна, и классификатора для этих регионов (DPM – deformable part models). Кроме этого, R-CNN использовал метод предложения регионов (region proposal). Этот метод сначала генерировал потенциальные содержащие рамки, после чего для них вызывался классификатор, а потом производилась пост-обработка для удаления двойных распознаваний и усовершенствования содержащих рамок.YOLO преобразовала задачу распознавания объектов к единой задаче регрессии. Она проходит прямо от пикселей изображения до координат содержащих рамок и вероятностей классов. Таким образом, единая CNN предсказывает множество содержащих рамок и вероятности классов для этих рамок.
Сбор данных
Чтобы идентифицировать шахматные фигуры, нужно собрать и проаннотировать изображения шахмат. Как было пояснено выше, нам интересны не шахматные фигуры сами по себе, а шахматы внутри партии. Поэтому пришлось сделать пару упрощений.
- Все изображения были сняты под одним углом. Штатив был поставлен на стол возле шахматной доски. Для работы модели на практике это требует, чтобы камера находилась под тем же углом, что и данные для обучения.
- Было создано всего 12 классов: по одному на каждую из шести фигур для двух цветов. Каждому классу соответствовали только фигуры из конкретного набора шахмат
Обучающие данные. Было собрано 292 изображения с различными положениями фигур на шахматной доске. Все фигуры были помечены, вышло 2894 аннотации. Получился общедоступный набор данных. Для маркировки существует множество качественных бесплатных инструментов с открытым исходным кодом, таких как LabelImg. Но в примере использовался RectLabel, который стоит 3 доллара в месяц.

В общем случае. Для решения проблемы, не связанной с шахматами, рассмотрите возможность сбора изображений в контексте того, где ваша модель будет работать в производстве. Очень часто камеры находятся только в одной конкретной позиции. В этом случае у вас будут одни и те же углы наблюдения и, возможно, условия освещения. Но чем больше ситуаций учитывает обучающая выборка, тем производительнее будет модель.
Будьте внимательны с рамками. При маркировке лучше рисовать ограничивающие рамки, включающие объект целиком, не обрезая его. Если один объект перекрывает другой, пометьте перекрываемый так, как если бы вы могли его видеть. Посмотрите, как это сделано на рисунке выше для белого слона и белой ладьи в левом верхнем углу.
Если вы ищете уже аннотированные изображения, рассмотрите наборы данных на Kaggle.
«Breakout-YOLO»: знакомимся с шустрой object-detection моделью, играя в классический «Арканоид»

Всем привет! Весенний семестр для некоторых студентов 3-го курса ФУПМ МФТИ ознаменовался сдачей проектов по курсу «Методы оптимизации». Каждый должен был выделить интересную для себя тему (или придумать свою) и воплотить её в жизнь в виде кода, научной статьи, численного эксперимента или даже бота в Telegram.
Жёстких ограничений на выбор темы не было, поэтому можно было дать разгуляться фантазии. You Only Live Once! — воскликнул я, и решил использовать эту возможность, чтобы привнести немного огня в бессмертную классику. ,
Выбор проекта
Всем хороша свобода выбора, кроме одного: надо определиться с этим самым выбором. Имелось много тем теоретических проектов, предложенных лектором и семинаристами, но меня они не заинтересовали. Всё-таки хотелось получить на выходе нечто, что можно потрогать руками, а не корпеть над статьями и математическими выкладками.
И тут я вспомнил, что год назад вместе с одногруппниками писал браузерный Арканоид на JavaScript. Почему бы не добавить в эту бородатую игрушку немного рок-н-ролла, а точнее модного нынче computer vision-а? Эта область ML представлялась мне довольно интересной и проект на эту тему стал бы прекрасной мотивацией для изучения.
Так и появилась игра Breakout с управлением жестами через веб-камеру, или выражаясь лаконичнее — Breakout-YOLO, но обо всем по порядку.
Теория
Поскольку YOLO смотрит на изображение только один раз, плавающее окно – это неправильный подход. Вместо этого, все изображение разбивается с помощью сетки на ячейки размером 𝑆 ∗ 𝑆 . После этого каждая ячейка отвечает за предсказание нескольких вещей
Во-первых, каждая ячейка отвечает за предсказание нескольких содержащих рамок и показателя уверенности (confidence) для каждой из них – другими словами, это вероятность того, что данная рамка содержит объект. Если в какой-то ячейке сетки объектов нет, то очень важно, чтобы confidence для этой ячейки был очень малым.
Когда мы визуализируем все эти предсказания, мы получаем карту всех объектов и набор содержащих рамок, ранжированных по их confidence.
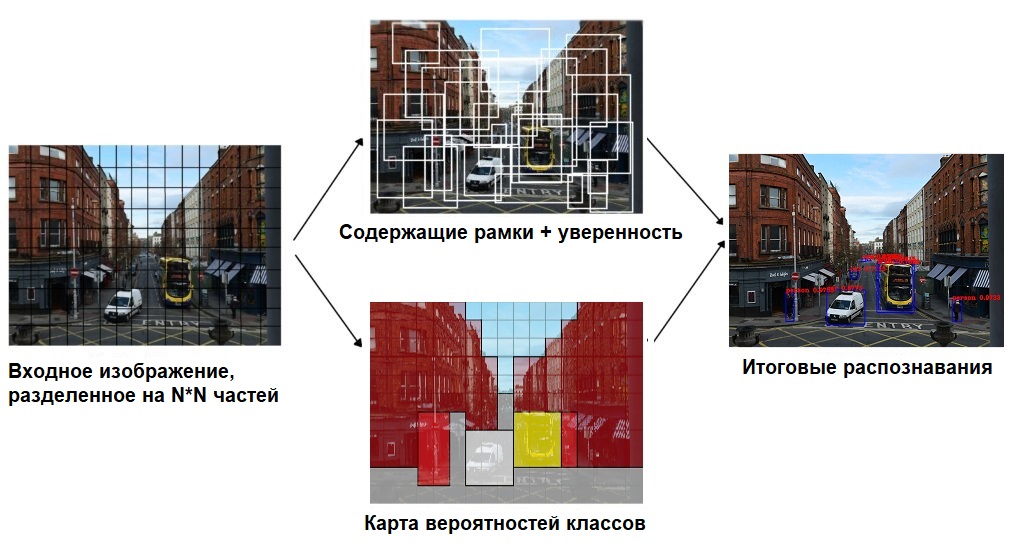
Во-вторых, каждая ячейка отвечает за предсказание вероятностей классов. Это не значит, что какая-то ячейка содержит какой-то объект, это всего лишь вероятность. Таким образом, если ячейка сети предсказывает автомобиль, это не значит, что он там есть, но это значит, что если там есть какой-то объект, то это автомобиль.
Давайте опишем детально, как может выглядеть выдаваемый моделью результат.
В YOLO для предсказания содержащих рамок используются якорные рамки (anchor boxes). Их основная идея заключается в предопределении двух разных рамок, называемых якорными рамками или формой якорных рамок. Это позволяет нам ассоциировать два предсказания с этими якорными рамками. В общем, мы можем использовать и большее количество якорных рамок (пять или даже больше). Якоря были рассчитаны на датасете COCO с помощью k-means кластеризации.

У нас есть сетка, каждая ячейка которой должна предсказать:
- для каждой содержащей рамки: 4 координаты ( 𝑡 𝑥 , 𝑡 𝑦 , 𝑡 𝑤 , 𝑡 ℎ ) и одну "ошибку объектности" – то есть, метрику confidence, определяющую, есть объект или нет.
- некоторое количество вероятностей классов.
Если есть некоторое смещение относительно верхнего левого угла 𝑐 𝑥 , 𝑐 𝑦 , то эти предсказания соответствуют следующим формулам:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t hгде 𝑝 𝑤 и 𝑝 ℎ соответствуют ширине и высоте содержащей рамки. Вместо предсказания смещений, как было во второй версии YOLO, авторы предсказывают координаты локации относительно расположения ячейки сети.
Этот вывод – это вывод нашей нейронной сети. Всего там 𝑆 ∗ 𝑆 ∗ [ 𝐵 ∗ ( 4 + 1 + 𝐶 ) ] выводов, где 𝐵 – количество содержащих рамок, предсказываемых каждой ячейкой (зависит от того, в скольких масштабах мы хотим делать наши предсказания), 𝐶 – количество классов, 4 – количество содержащих рамок, а 1 – предсказание объектности. За один проход мы можем пройти от исходного изображения до выходного тензора, соответствующего распознанным объектам изображения. Стоит также упомянуть, что YOLO v3 предсказывает рамки в трех разных масштабах.
Теперь, если мы возьмем вероятности и умножим их на значения confidence, мы получим все содержащие рамки, взвешенные по их вероятности содержания этого объекта.
Простое сравнение с порогом позволит нам избавиться от предсказаний с низкой confidence. Для следующего шага важно определить, что такое пересечение относительно объединения (intersection over union). Это отношение площади пересечения прямоугольников к площади их объединения:

После этого у нас еще могут быть дубликаты, и чтобы от них избавиться, мы применяем подавление не-максимумов. Подавление не-максимумов берет содержащую рамку с максимальной вероятностью и смотрит на другие содержащие рамки, расположенные близко к первой. Ближайшие рамки с максимальным пересечением относительно объединения с первой рамкой будут подавлены.
Поскольку все делается за один проход, модель работает почти с такой же скоростью, как классификация. Кроме того, все предсказания производятся одновременно, а это значит, что модель неявно встраивает в себя глобальный контекст. Проще говоря, модель может усвоить, какие объекты обычно встречаются вместе, относительные размеры и расположение объектов и так далее.
Мы настоятельно рекомендуем изучить все три документа YOLO:
Обучение модели
Архитектура, которую мы будем использовать, предложена Джозефом Редмоном и называется YOLO. Это сокращение от You Only Look Once, что на английском означает «Вы смотрите только один раз». То есть цифровые данные изображения проходят через нейронную сеть лишь единожды. За счёт этого предсказательная модель производительна, и анализирует до 60 кадров в секунду. Поэтому YOLO часто используют для видеопотоков. Если вам интересно лучше изучить архитектуру модели, рекомендуем прочесть эту публикацию.
Несмотря на то что мы обучаем модель на собственном наборе данных, выгодно не обучать её с чистого листа, а применить «перенос обучения». То есть использовать в качестве отправной точки веса от другой, уже обученной модели. Здесь работает следующая аналогия: чтобы забраться на конкретное место горы быстрее, мы идём не случайным образом, а по проложенной ранее тропинке.
Для поддержки вычислений модели мы будем использовать Google Colab, который предоставляет бесплатные вычислительные ресурсы на GPU, до 24 часов при открытом браузере. Соответствующий пример блокнота на Colab.

Модель улучшается по мере того, как снижается значение функции потерь (loss).
В нашем блокноте мы делаем шесть вещей:
- Выбираем среду, модель архитектуры и предварительно подобранные веса (чужой «след»).
- Загружаем данные с помощью сниппета из Roboflow.
- Определяем конфигурацию модели, например, количество эпох обучения, размеры пакетов, размер набора для теста, скорость обучения.
- Инициируем тренировку (. и ждём).
- Используем обученную модель для прогноза.
- Опционально: сохраняем модель с новыми весами в Google Drive, чтобы далее делать прогнозы, не дожидаясь окончания обучения.
Если вы используете аналогичный подход для решения вашей задачи, для обучения на той же архитектуре нужно всего лишь изменить URL-адрес загрузки данных из Roboflow. Кроме того, вы можете поиграть с параметрами обучения (например, скорость обучения, число эпох).
Постановка задачи
Основной геймплей Арканоида заключается в отбивании шарика двигающейся платформой, управляемой мышью/тачпадом или клавиатурой:
Мне же хотелось перенести функцию управления на жесты пользователя. Управление платформой я утвердил следующее: её положение определяется положением некоторого жеста на видео с веб-камеры.
То есть естественным образом возникла задача real-time object-detection — на вход алгоритму поступает кадр из видео, на выходе хотим иметь изображение с объектами, обведёнными в рамку (bounding box) прямо как на картинке ниже:

И все это нужно делать быстро, выдавая хотя бы 20-30 FPS, — ведь никому не интересно играть в слайд-шоу. Не сомневаюсь, что причастные к CV люди по названию статьи догадались какую модель я выбрал, остальных же охотно приглашаю под следующий заголовок.
Реализация YOLO в Tensorflow
Мы создадим полную сверточную нейронную сеть (Fully Convolutional Network, FCN) без тренировки. Чтобы что-то предсказать с помощью этой сети, нужно загрузить веса от заранее тренированной модели. Эти веса получены после тренировки YOLOv3 на датасете COCO (Common Objects in Context), и их можно загрузить с официального сайта.
Создаем папку для хранения весов
Импортируем все необходимые библиотеки
Проверяем версию Tensorflow. Она должна быть не ниже 2.0:
Определим несколько важных переменных, которые будем использовать ниже.
Список слоев в YOLOv3 FCN — Fully Convolutional Network
Очень трудно загрузить веса с помощью чисто функционального API, поскольку порядок слоев в Darknet и tf.keras различаются. Здесь лучшее решение – создание подмоделей в keras. Для сохранения подмоделей рекомендуется использовать Checkpoint'ы Tensorflow, поскольку они официально поддерживаются Tensorflow.
Вот функция для загрузки весов из оригинальной тренированной модели YOLO в Darknet:
Функция для расчета пересечения относительно объединения
Функция для отрисовки содержащей рамки, имени класса и вероятности:
Мы используем пакетную нормализацию (batch normalization), чтобы нормализовать результаты для ускорения тренировки. К сожалению, tf.keras.layers.BatchNormalization работает не очень хорошо для transfer learning, поэтому здесь предлагается другое решение этой проблемы.
Для каждого масштаба мы определяем три якорные рамки для каждой ячейки. В этом примере маска такова:
- 0,1,2 – мы будем использовать три первые якорные рамки
- 3,4,5 – мы используем четвертую, пятую и шестую рамки
- 6,7,8 – мы используем седьмую, восьмую и девятую рамки
Tiny-YOLOv3
You Only Look Once
YOLO — это популярная архитектура CNN для решения задачи object-detection:

Основная её идея состоит в том, что нейросеть обрабатывает всё входное изображение лишь единожды. Такой подход дает существенный выигрыш в быстродействии по сравнению с методами, использующими region proposals. В последних же происходит несколько независимых классификаций выделенных областей изображения — это не только медленнее по очевидным причинам, но и не учитывает контекст, что несколько ухудшает точность распознавания.
За подробным описанием архитектуры отсылаю интересующегося читателя к оригинальной статье и её обзору от Deep Systems.
Better, Faster, Stronger
Одной из последних* версий YOLO является YOLOv3. От первоначальной модели эту отличает несколько новых фич: авторы отказались от fully-connected слоя в конце, таким образом остались только свёрточные слои. Для улучшения распознавания объектов разных размеров было добавлено 2 дополнительных выходных слоя, что напоминает концепцию feature pyramid.
Были задействованы anchor box-ы — наборы ограничительных рамок, а точнее их параметров, относительно которых сеть делает предсказания bounding box-ов. Для повышения точности предсказаний их нужно перевычислять отдельно для каждого датасета. Обычно это делают с помощью метода k-средних, кластеризуя множество bounding box-ов из трейна.
Для того, чтобы регуляризовать сеть, к каждому свёрточному слою был прикручен batch normalization. Также был применён multi-scale training — случайное изменение разрешения входящего изображения при обучении.
Детальное описание всех изменений можно найти в статьях про YOLOv2 и YOLOv3 и обзоре.
Я же взял Tiny-YOLOv3 — уменьшенную версию этой модели без последнего слоя:

В ней используется слой пулинга вместо свёрточного слоя с страйдом 2. Всё это делает её быстрее и компактнее (
35 Мб), а значит более предпочтительнее для моей задачи.
* на момент выбора модели. С тех пор успела выйти YOLOv4 и нечто, называющее себя YOLOv5.
Реализация YOLO v3
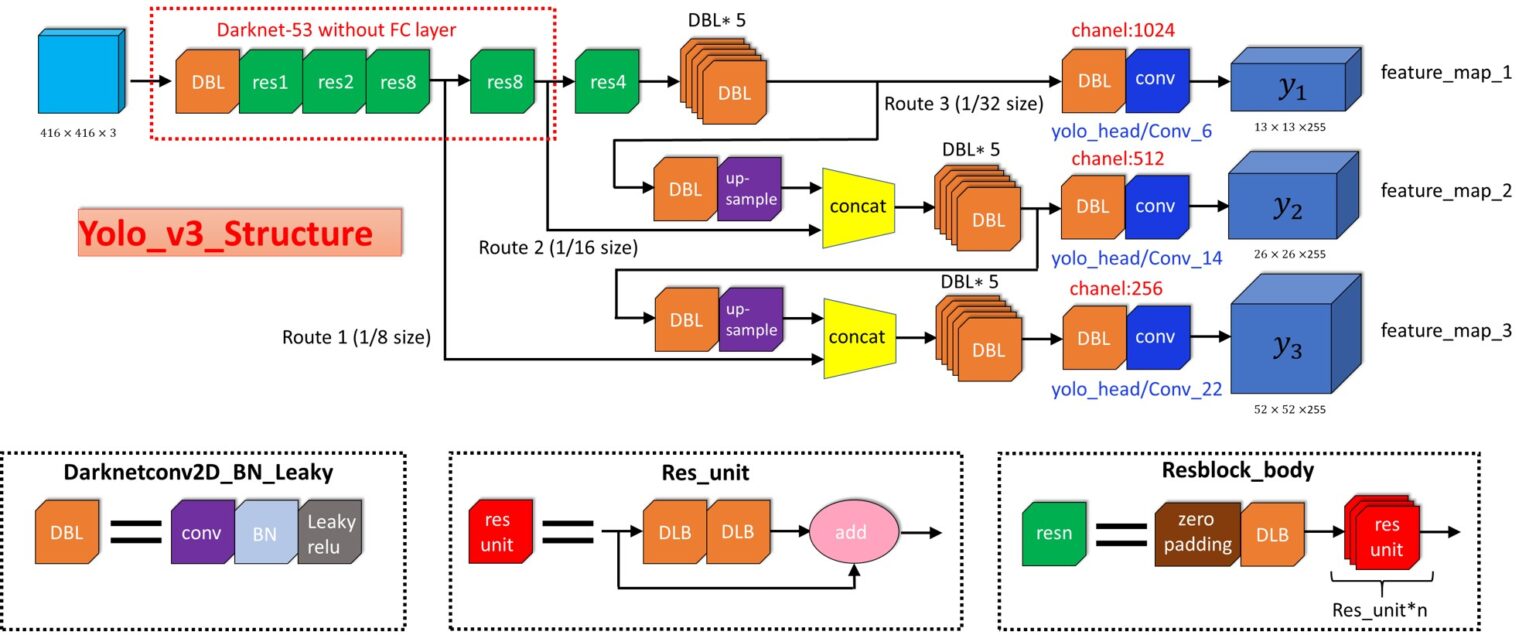
Пришло время реализовать сеть YOLOv3. Вот как выглядит ее структура:
Darknet 53 – YOLO v3
Здесь основная идея – использовать только сверточные слои. Их там 53, так что проще всего создать функцию, в которую мы будем передавать важные параметры, изменяющиеся от слоя к слою.
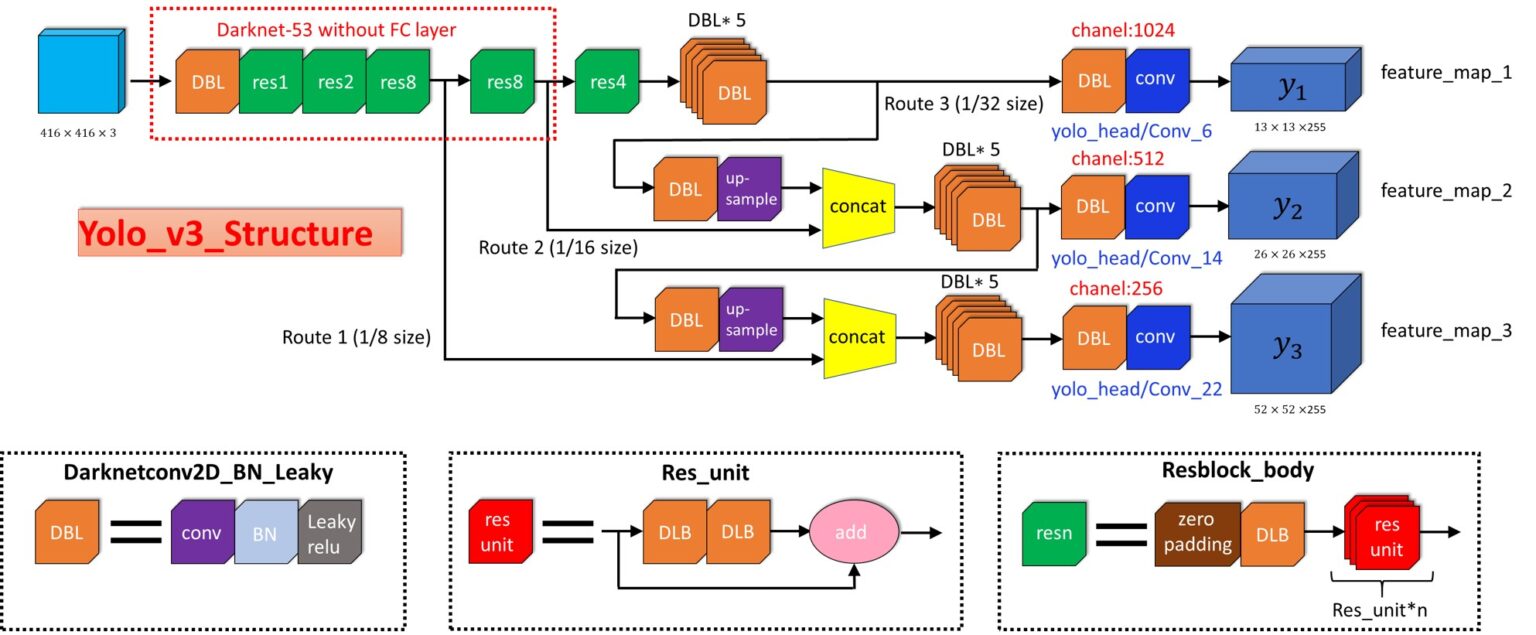
Остаточные блоки (Residual blocks) на диаграмме архитектуры YOLOv3 используются для обучения признакам. Остаточный блок состоит из нескольких сверточных слоев и обходных путей:
Мы строим нашу модель с помощью Функционального API, простого в использовании. С ним мы можем легко задавать ветви в нашей архитектуре (блок ResNet) и легко использовать одни и те же слои несколько раз внутри архитектуры.
Основная функция, создающая всю модель:
Функция потерь с декоратором:
Следующая функция трансформирует целевые выводы к кортежу (tuple) следующей формы:
( [ N , 13 , 13 , 3 , 6 ] , [ N , 26 , 26 , 3 , 6 ] , [ N , 52 , 52 , 3 , 6 ] )Здесь N – количество меток в пакете (batch), а 6 представляет [x, y, w, h, obj, class] содержащих рамок.
Теперь мы создаем экземпляр нашей модели, загружаем веса и имена классов. В датасете COCO их 80.
Вот и все! Прямо сейчас мы можем запустить и протестировать нашу модель на каком-нибудь изображении.

Сохраните это изображение в файл detect.jpg
После выполнения этого кода в файле output.jpg окажется то же изображение с рамками, отмечающими объекты, распознанные нашей нейронной сетью:

Постановка задачи
Конкретный пример. В качестве примера возьмём игру в шахматы. Чтобы совершенствовать навык игры, необходимо фиксировать и понимать ошибки. Определять, какие ходы идеальный игрок мог сделать в той же ситуации. Играть вживую интереснее и приятнее, чем на компьютере или телефоне. Поставим задачу создать систему, которая в реальном времени распознаёт состояние живой игры и записывает каждый ход.
Постановка задачи. Описанный пример потребует не только определения того, что собой представляет шахматная фигура, но и положения фигуры на доске. Нужно совершить скачок от простого распознавания объекта к одновременному обнаружению и фиксации положения объектов. Чтобы пока не усложнять задачу, в этой публикации мы сосредоточимся на обнаружении объектов. Мы должны обучить модель определять тип шахматной фигуры и её цвет (чёрный или белый), то есть принадлежность игроку.

Важно правильно понять, какую задачу вы хотите решить. Мы хотим детектировать все объекты на шахматной доске и определить их положения. В этой публикации обсуждаем только детектирование.
В общем случае для постановки задачи, не связанной с шахматами, нужно заранее подумать об ограничении пространства задачи конкретными элементами. Также рассмотрите минимально приемлемые критерии производительности модели. Например, какая вероятность распознавания объекта вас устроит.
Работа с данными
Перейдём к самой рабоче-крестьянской части проекта.
Выбор жестов и датасета
Для управления игрой были выбраны следующие 4 жеста:

Вопрос: на чем обучать модель?
Первое, что пришло в голову — взять датасет какого-нибудь жестового языка, например американского: ASL Alphabet, Sign Language MNIST и обучится на нем.
Но меня отпугнуло следующее:
- В отсмотренных мною датасетах все фотографии были сделаны на однородном фоне
- Не все выбранные мною жесты были представлены в датасетах
- Я не нашел именно object detection датасета с bounding box-ами, так что в любом случае пришлось бы доразмечать данные
Модели же предстояло работать на разных ноутбуках с разными веб-камерами в условиях если не агрессивного фона и плохого освещения, то как минимум силуэта человека на заднем плане. По этой причине (а также из-за своей неосведомлённости в deep learning) я не мог обоснованно сказать, как YOLO обученная на этих данных поведет себя в бою. К тому же сроки предзащиты проекта поджимали — права на ошибку не было.
Поэтому я посчитал правильным действовать наверняка и решил.

собрать и разметить свой датасет.
Не имей сто рублей, а имей сто друзей
В развивающемся репозитории с различными YOLO моделями мудрецы гласят, что для сколько-нибудь успешного обучения необходимо иметь в трейне не менее 2000 размеченных изображений для каждого класса. Я решил не мелочиться и поставил планку в 3000 изображений для каждого класса, обеспечивая себе пути для отступления и солидную тестовую выборку в случае выполнения поставленной цели.
Как для достижения большего разнообразия в датасете, так и для облегчения собственных страданий пришлось прибегнуть к бесплатному краудсорсингу помощи друзей. Я попросил каждого из этих восьми несчастных записать на веб-камеру 2-ух минутное видео с 4 жестами — по 15 секунд на жест каждой рукой. Сам я сделал 4 таких видео в разной одежде и на разных фонах.
Далее в дело вступал удобнейший GUI для разметки от AlexeyAB. С помощью него я нарезал видео на кадры и, набравшись терпения, сел размечать. Директорию с изображениями я предварительно синхронизировал с гугл-доком при помощи Insync, чтобы не терять время на перенос датасета в облако.
Применение модели
В приведённом выше примера блокнота прогноз происходит при вызове скрипта yolo_video.py . Этот сценарий принимает путь к видеофайлам или изображениям, пользовательские веса, привязки (не рассматривались в этом примере), классы, количество используемых графических процессоров, флаг, описывающий, прогнозируем ли мы изображение иди видео, и, наконец, выходной путь для предсказанного видео или изображения.
Сценарий компилирует модель, ожидает ввода в файл изображения и предоставляет координаты ограничивающих рамок и имя класса для любых найденных объектов. Координаты рамки предоставляются в формате пикселей нижнего левого угла ( min_x , min_y ) и пикселей верхнего правого угла ( max_x , max_y ).
Пользовательские веса, которые мы загружаем в этом примере, на самом деле не самые лучшие в архитектуре YOLO. Из-за ограничений Colab модель не может рассчитать конечные веса. Это означает, что модель не так эффективна, как могла бы быть. С другой стороны, это вычисления выполнены бесплатно. На видео выше показан процесс детектирования перемещения фигур на доске.
Обучение
Снаряжаемся видеокарточками
Времени до первого показа проекта оставалось всё меньше и меньше, поэтому я пошёл куда глаза глядят по пути наименьшего сопротивления и решил обучать модель в Darknet — написанном на C и CUDA open-source фреймворке для создания и обучения нейронных сетей.
Вычислительных мощностей мне объективно не хватало — из графических процессоров с поддержкой CUDA под рукой имелась только GeForce GT 740M (Compute Capability = 3.0), которой требовалось 10-12 часов для обучения Tiny-YOLOv3. Поэтому я стал счастливым обладателем подписки на Colab Pro с Tesla P100-PCIE-16GB под капотом, сократившей это время до 3 часов. Стоит отметить, что Colab уже давно и так бесплатно предоставляет всем желающим мощную Tesla T4, правда с ограничениями по времени использования. О них я узнал по всплывшей на экране надписи «You cannot currently connect to a GPU due to usage limits in Colab», заигравшись с обучением YOLO на всяких кошечках-собачках, интереса ради.
Чтобы нащупать trade-off между точностью распознавания и быстродействием, я взял 4 модели: Tiny-YOLOv3 с размерами входного изображения 192x192, 256x256, 416x416 и XNOR Tiny-YOLOv3, в которой свёртки аппроксимируются двоичными операциями, что должно ускорять работу сети. Указанные «Ёлки» обучались в течение 8, 10, 12 и 16 тысяч итераций соответственно.
Метриками качества обученных моделей послужили mean Average Precision с IoU=0.5(далее обозначается как mAP@0,5) и FPS.
Результаты обучения

На графиках выше представлены зависимости значений лосс-функции на трейне и mAP@0.5 на тесте от номера итерации обучения.
Как видите, XNOR модели нездоровилось. Несмотря на финальный mAP@0.5 ≈ 88%, при хорошем освещении она еле-еле распознавала пару жестов с минимальным confidence. FPS ≈ 15 также намекал, что что-то пошло не так. Это не могло не расстраивать, так как я возлагал на XNOR большие надежды. На момент написания этой статьи мне всё ещё не ясно, в чём была проблема, возможно я что-то напутал в .cfg файле.

Остальные же модели обучились приемлемо. Полученные значения FPS справедливы для следующей
ASUS Vivobook S15, i7 1.8GHz, GeForce MX250
В погоне за быстродействием для использования в игре я выбрал 192х192 модель.
Дабы не зависящий от размера входного изображения mAP@0.5 не вводил в заблуждение, надо сказать, что эта метрика в данной ситуации несколько обманчива.
Дело в том, что в собранном датасете жесты на фотографиях расположены примерно на одном расстоянии от камеры, поэтому модели переобучились на это расстояние. Это видно по тому, как 192х192 модель работает при сильном приближении/отдалении от веб-камеры — она не умеет предсказывать очень большие/маленькие bounding box-ы, так как не видела таковых в датасете. Однако такое переобучение соответствует поставленной задаче — распознаванию жестов на установленном расстоянии, удобном пользователю.
Таким образом, важно понимать, что mAP@0.5 здесь тесно связан с конкретной задачей, и на самом деле при уменьшении размера входного изображения модель теряет в точности распознавания очень близких/далеких к камере жестов, что, однако, практически не влияет на точность на тесте.
Let's play!
Немного про архитектуру
Для распознавания жестов в браузере я использовал библиотеку TensorFlow.js. Обученные веса сначала были сконвертированы в Keras, а затем преобразованы в TFJS Graph model.
Так выглядит демо-версия (загрузка может занять некоторое время):
Сама игра написана на Javascript, за основу был взят этот туториал. Её архитектура предельно проста и заключается лишь в перерисовке кадров с помощью setInterval. На некоторых девайсах наблюдался довольно низкий FPS, поэтому я установил модель распознавать жесты каждую 10-ую перерисовку.
Несмотря на это, всё равно могут быть заметны фризы в момент распознавания. Чтобы их избежать я планирую распараллелить распознавание и перерисовку с помощью Web Worker.
А вот теперь поиграем
Весь код с обученными моделями и инструкцией по использованию лежит здесь.
- Нажатие на кнопку «Play»/пауза в игре — жест «finger up»
- Перемещение курсора в меню/снятие с паузы — жест «circle»
- Перемещение платформы — жест «fist»
- Выстрел шариком с «липкой» платформы — жест «pistol»
Поиграть можно здесь. Я рекомендую использовать FIrefox, но Chrome/Chromium также поддерживаются.
Так выглядит геймплей:
Подготовка данных
Переход напрямую от сбора данных к обучению модели обычно приводит к неоптимальным результатам. Подготавливая изображения для детектирования, выполните следующие действия:
- Проверьте корректность аннотаций. Например, аннотации не должна выходить за рамки изображения.
- Обеспечьте правильную ориентацию в EXIF. Это одна из распространённых ошибок – изображения на диске хранятся обычно не так, как вы видите их в приложениях. Подробно об этом писал Адам Гейтджи.
- Измените размер изображений и обновите аннотации для соответствия новым размерам.
- Проведите цветовую коррекцию.
- Отформатируйте аннотации в соответствии с требованиями входных данных модели (например, нужно создать TFRecords для TensorFlow или простой текстовый файл для некоторых реализаций YOLO).
Подобно табличным данным, очистка и аугментация данных могут повысить производительность конечной модели больше, чем вариация архитектуры модели.
Предобработанные данные по нашей задаче тоже размещены в общем доступе.
В рассматриваемом случае вместо исходных изображений размером 2284×1529 использовались уменьшенные изображения 416x416.
- Изображения меньшего размера позволяют быстрее обучаться.
- Архитектура YOLOv3 более эффективно работает с изображениями, размеры которых кратны 32x32.
С помощью сервиса Roboflow к изображениям был применён ресайзинг и автоориентация, решающая описанную выше проблему с EXIF-данными. Roboflow также генерирует код, который можно перетащить непосредственно в блокнот Jupyter, включая Colab, и использовать так предподготовленные данные.

Подробнее о Roboflow написано на странице Быстрый старт.
Распознавание видео с камеры
Мы уже добились впечатляющего результата, но главное еще впереди! Самое важное в архитектуре YOLO не то, что она довольно неплохо умеет распознавать объекты, а то, что она делает это быстро. Настолько быстро, что успевает обработать все кадры, поступающие от веб-камеры. Включите веб-камеру и запустите следующий код:
Вы увидите на экране изменяющуюся картинку с камеры, на которой будут отмечены все распознанные объекты. Теперь вы можете перемещать свою камеру или двигать объекты в кадре, и нейронная сеть будет успевать обрабатывать меняющиеся изображения.
Вместо заключения
Внимательный читатель спросит: «А причем тут собственно методы оптимизации?» Да ни при чем! Но такая свобода выбора темы проекта дала стимул плотно начать разбираться в интересном разделе машинного обучения, и это здорово, на мой взгляд.
Sapere aude, хабровчане!
Полезные ссылки
- Непосредственно код и постер
- Оригинальная статья YOLOv3
- Толковый сайт посвящённый методам оптимизации — fmin.xyz
Всё это, как видится, лишь история о моём знакомстве с моделью YOLO и о её использовании. Если Вы знаете как надо было сделать, то приглашаю вместе с конструктивной критикой в комментарии, буду рад дельным рекомендациям.
Читайте также: