
Java garbage collector как работает
Обновлено: 05.07.2024
Вновь созданные объекты начинаются в Young Generation. Его еще называют ясли, так как здесь начинают жить новые объекты. Young Generation подразделяется на Eden Space, где начинаются все новые объекты, и два пространства Survivor , где объекты перемещаются из Eden после сохранения (surviving) в одном цикле сборки мусора. Они вызывают повторную сборку мусора, когда объекты собираются сборщиком мусора из Young Generation. Eden Space Все новые объекты сначала создаются в Eden Space. Незначительный сбор мусора сработает, когда он достигнет порога, определяемого JVM. Упомянутые объекты перемещаются из Eden Space в пространство первого сохранения (‘Eden’ and ‘from’ —> ‘to’). Объекты, на которые нет ссылок, удаляются при очистке Eden Space. Survivor 0 (S0) and Survivor 1 (S1) Оба поля survivor (From and to) начинаются пустыми. Когда происходит повторная сборка мусора, все объекты, на которые есть ссылки, перемещаются в оставшееся пространство. Когда сборка мусора закончится, места (имена) survivor «from» и «to» меняются местами. Если во время предыдущей сборки мусора S1 был в роли «to», то теперь S1 заполнен и становится «from». Соответственно, если S0 пусто, то оно станет «to».
Old Generation
Permanent Generation
Типы сборки мусора
Сборки мусора, очищающие различные части внутри кучи, часто называют Minor, Major и Full сборками мусора. Но, поскольку термины Minor, Major и Full широко используются и без надлежащего определения, мы рассмотрим объяснение всех этих типов сборки мусора.
Minor Garbage Collection
Сборка мусора из пространства Young Generation называется Minor Garbage Collection. Этот тип сборки всегда запускается, когда JVM не может выделить место для нового объекта, то есть когда Eden Space заполняется. Таким образом, чем выше скорость выделения, тем чаще происходит Minor Garbage Collection.
Major Garbage Collection
Major Garbage Collection очищает Tenured (старое пространство). Поскольку Old Generation больше по размеру, сборка происходит реже, чем у Young Generation. Когда объекты исчезают из Old Generation, мы говорим, что произошел «большая сборка мусора». Сборщик Old Generation попытается предугадать, когда ему нужно начать сборку, чтобы избежать неудач в продвижении со стороны Young Generation. Сборщики отслеживают порог заполнения для Old Generation и начинают сборку, когда этот порог превышен. Если этого порога недостаточно для удовлетворения требований продвижения, запускается «Full Garbage Collection».
Full Garbage Collection
Full Garbage Collection очищает всю кучу — как молодые, так и старые пространства. Многие путаются между Major (только OLD поколение) и Full GC (Young + OLD (Heap)). Full Garbage Collection включает продвижение всех живых объектов от молодого до старого поколения после сборки и уплотнения старого поколения. Полная сборка мусора будет остановкой для Stop-the-World. Она следит за тем, чтобы новые объекты не выделялись и объекты не становились недоступными во время работы сборщика.
15 важных вопросов про Spring на техническом собеседовании
1. Что такое Spring?
Ответ: Spring — это фреймворк с открытым исходным кодом для разработки приложений на Java. Основные функции Spring Framework можно использовать при разработке любого приложения Java, также имеются расширения для создания веб-приложений на основе платформы Java EE. Фреймворк Spring нацелен на упрощение использования J2EE в разработке, и улучшение практики программирования путем включения модели на основе POJO (Plain Old Java Object).
2. Какова область действия по умолчанию у bean-компонента в Spring framework?
Ответ: Область действия bean-компонента по умолчанию — Singleton (шаблон проектирования).
3. Что такое Bean wiring?
Ответ: Bean wiring (подключение Bean) — это действие по созданию ассоциаций между компонентами приложения (beans) в контейнере Spring.
4. Что такое Spring Security?
Ответ: Spring Security — это отдельный модуль инфраструктуры Spring, который фокусируется на предоставлении методов аутентификации и авторизации в приложениях Java. Он также устраняет большинство распространенных уязвимостей безопасности, таких как атаки CSRF. Чтобы использовать Spring Security в веб-приложениях, можно начать с простой аннотации: @EnableWebSecurity.
5. Что содержится в определении bean-компонента?
- Как создать bean;
- Подробности жизненного цикла bean;
- Зависимости bean.
6. Что такое Spring Boot?
Ответ: Spring Boot — это проект, который предоставляет предварительно настроенный набор фреймворков для уменьшения шаблонной конфигурации, чтобы вы могли запускать и запускать приложение Spring с минимальным объемом кода.
7. Что такое DispatcherServlet и для чего он используется?
Ответ: DispatcherServlet — это реализация шаблона проектирования Front Controller, который обрабатывает все входящие веб-запросы к приложению Spring MVC. Шаблон Front Controller (шаблон проектирования корпоративного приложения) — это распространенный шаблон в веб-приложениях, задача которого заключается в получении всего запроса и его маршрутизации в различные компоненты приложения для фактической обработки. В Spring MVC DispatcherServlet используется для поиска правильного контроллера для обработки запроса. Это делается с помощью сопоставления обработчиков: например, аннотации @RequestMapping.
8. Нужен ли spring-mvc.jar в пути к классам или он является частью spring-core?
Ответ: Spring-mvc.jar является частью spring-core, что означает, что если вы хотите использовать инфраструктуру Spring MVC в своем проекте Java, то вы должны включить ее spring-mvc.jar в путь к классам вашего приложения. В веб-приложении Java spring-mvc.jar обычно помещается в папку /WEB-INF/lib.
9. Каковы преимущества использования Spring?
- Легкость — Spring относительно легкий, когда дело касается размера и прозрачности. Базовая версия Spring Framework составляет около 2 МБ.
- Инверсия управления (Inversion of control, IOC) — Слабая связанность (loose coupling) достигается в Spring с использованием техники инверсии управления. Объекты предоставляют свои зависимости вместо того, чтобы создавать или искать зависимые объекты.
- Аспектно-ориентированность — Spring поддерживает аспектно-ориентированное программирование и обеспечивает согласованную разработку, отделяя бизнес-логику приложения от системных служб.
- Контейнеры — Spring Container создаёт объекты, связывает их вместе, настраивает и управляет ими от создания до момента удаления.
- MVC Framework — веб-фреймворк Spring — это хорошо спроектированный веб-фреймворк MVC, который обеспечивает альтернативу таким веб-фреймворкам, как Struts или другим излишне спроектированным или менее популярным веб-фреймворкам.
- Управление транзакциями — Spring имеет согласованный интерфейс управления транзакциями, который может масштабироваться до локальной транзакции (например, с использованием одной базы данных) или глобальных транзакций (например, с использованием JTA).
- Обработка исключений — Spring предоставляет удобный API для преобразования исключений, связанных с конкретной технологией (например, вызванных JDBC, Hibernate или JDO) в согласованные, непроверенные исключения.
10. Что такое Spring beans?
Ответ: Spring beans — это экземпляры объектов, которыми управляет Spring Container. Они создаются и подключаются фреймворком и помещаются в «мешок объектов» (контейнер), откуда вы можете их позже извлечь. «Связка» (wiring) — это то, что является внедрением зависимостей. Это означает, что вы можете просто сказать: «Мне нужна эта вещь», и фреймворк будет следовать определенным правилам для получения этого объекта.
11. Какова цель модуля Core Container?
Ответ: Контейнер ядра обеспечивает основные функции платформы Spring. Первичным компонентом основного контейнера является BeanFactory — реализация шаблона Factory. BeanFactory применяет Инверсию управление для разделения конфигурации и зависимостей спецификации приложения от фактического кода приложения.
12. Что такое контекст приложения (Application Context)?
13. Как интегрировать Java Server Faces (JSF) с Spring?
Ответ: JSF и Spring действительно имеют одни и те же функции, особенно в области сервисов Инверсии управления. Объявляя управляемые компоненты JSF в файле конфигурации faces-config.xml, вы позволяете FacesServlet создавать экземпляр этого bean-компонента при запуске. Ваши страницы JSF имеют доступ к этим bean-компонентам и всем их свойствам. JSF и Spring можно интегрировать двумя способами: DelegatingVariableResolver : Spring поставляется с преобразователем переменных JSF, который позволяет вам использовать JSF и Spring вместе. DelegatingVariableResolver сначала делегирует поиск значений интерпретатору по умолчанию базовой реализации JSF, а затем — «бизнес-контексту» Spring WebApplicationContext. Это позволяет легко внедрять зависимости в JSF-управляемые компоненты. FacesContextUtils : настраиваемый VariableResolver хорошо работает при отображении своих свойств на bean-компоненты в faces-config.xml. Но если потребуется захватить bean-компонент, то класс FacesContextUtils это упрощает. Он похож на WebApplicationContextUtils, за исключением того, что принимает параметр FacesContext, а не параметр ServletContext.
14. Что такое Spring MVC framework?
Ответ: Инфраструктура Spring Web MVC предоставляет архитектуру model-view-controller и готовые компоненты, которые можно использовать для разработки гибких и слабосвязанных веб-приложений. Шаблон MVC приводит к разделению различных аспектов приложения (логика ввода, бизнес-логика и логика пользовательского интерфейса), обеспечивая при этом слабую связь между этими элементами.
15. Как происходит обработка событий в Spring?
Ответ: Обработка в ApplicationContext обеспечивается через ApplicationEvent класса и ApplicationListener интерфейса. То есть если bean-компонент реализует ApplicationListener, то каждый раз, когда ApplicationEvent публикуется в ApplicationContext, этот bean-компонент регистрируется. Спасибо за чтение и удачи в вашем техническом собеседовании!
Организация памяти JVM
Делится на две части:
- Heap - куча. Основной сегмент памяти, где содержатся все объекты и происходит сборка мусора.
- Permanent Generation - содержит мета-данные классов.
Сразу про Permanent Generation. Может менять размер во время выполнения, и это довольно дорогостоящая операция. Размер настраивается (-XX: PermSize - мин размер, -XX: MaxSize - макс размер). Часто мин = макс.
Heap. Куча. Тут и работает GC.
Делится на две области:
- New (Yang) Generation - объекты, кот. тут считаются короткоживущими.
- Old Generation (Tenured) - обекты считаются долгоживущими.
Алгоритм GC исходит из того предположения, что большинство java-объектов живут недолго. Быстро становятся мусором. От них необходимо довольно оперативно избавляться. Что и происходит в New Generation. Там сбор мусора гораздо чаще, чем в Old Generation, где хранятся долгоживущие объекты. После создания объект попадает в New Generation и имеет шанс попасть в Old Generation по прошествии некоторого времени (циклов GC).
Heap состоит из:
- Eden - переводится как Едем (?). Сюда аллоцируются объекты. Если нет места запускается GC.
- Survivor - точнее их два, S1 и S2, и они меняются ролями. Хранятся объекты, которые признаются живыми во время GC.
Размер Heap настраивается.

Для работы любого приложения требуется память. Однако память компьютера ограничена. Поэтому важно ее очищать от старых неиспользуемых данных, чтобы освободить место для новых.
Кто занимается этой очисткой? Как и когда очищается память? Как выглядит структура памяти? Давайте разберем с этим подробнее.
Структура памяти Java
Память в Java состоит из следующих областей:

Структура памяти Java
Native Memory — вся доступная системная память.
Heap (куча) — часть native memory, выделенная для кучи. Здесь JVM хранит объекты. Это общее пространство для всех потоков приложения. Размер этой области памяти настраивается с помощью параметра -Xms (минимальный размер) и -Xmx (максимальный размер).
Stack (стек) — используется для хранения локальных переменных и стека вызовов метода. Для каждого потока выделяется свой стек.
Metaspace (метаданные) — в этой памяти хранятся метаданные классов и статические переменные. Это пространство также является общими для всех. Так как metaspace является частью native memory, то его размер зависит от платформы. Верхний предел объема памяти, используемой для metaspace, можно настроить с помощью флага MaxMetaspaceSize.
PermGen (Permanent Generation, постоянное поколение) присутствовало до Java 7. Начиная с Java 8 ему на смену пришла область Metaspace.
CodeCache (кэш кода) — JIT-компилятор компилирует часто исполняемый код, преобразует его в нативный машинный код и кеширует для более быстрого выполнения. Это тоже часть native memory.
Сборка мусора: введение
Что такое "мусор"? Мусором считается объект, который больше не может быть достигнут по ссылке из какого-либо объекта. Поскольку такие объекты больше не используются в приложении, то их можно удалить из памяти.
Например, на диаграмме ниже объект fruit2 может быть удален из памяти, поскольку на него нет ссылок.

Мусор
Что такое сборка мусора? Сборка мусора — это процесс автоматического управления памятью. Освобождение памяти (путем очистки мусора) выполняется автоматически специальным компонентом JVM — сборщиком мусора (Garbage Collector, GC). Нам, как программистам, нет необходимости вмешиваться в процесс сборки мусора.
Сборка мусора: процесс
Для сборки мусора используется алгоритм пометок (Mark & Sweep). Этот алгоритм состоит из трех этапов:
Mark (маркировка). На первом этапе GC сканирует все объекты и помечает живые (объекты, которые все еще используются). На этом шаге выполнение программы приостанавливается. Поэтому этот шаг также называется "Stop the World" .
Sweep (очистка). На этом шаге освобождается память, занятая объектами, не отмеченными на предыдущем шаге.
Compact (уплотнение). Объекты, пережившие очистку, перемещаются в единый непрерывный блок памяти. Это уменьшает фрагментацию кучи и позволяет проще и быстрее размещать новые объекты.
Поколения объектов
Что такое поколения объектов?
Для оптимизации сборки мусора память кучи дополнительно разделена на четыре области. В эти области объекты помещаются в зависимости от их возраста (как долго они используются в приложении).
Young Generation (молодое поколение). Здесь создаются новые объекты. Область young generation разделена на три части раздела: Eden (Эдем), S0 и S1 (Survivor Space — область для выживших).
Old Generation (старое поколение). Здесь хранятся давно живущие объекты.
Что такое Stop the World?
Когда запускается этап mark, работа приложения останавливается. После завершения mark приложение возобновляет свою работу. Любая сборка мусора — это "Stop the World".
Что такое гипотеза о поколениях?
Как уже упоминалось ранее, для оптимизации этапов mark и sweep используются поколения. Гипотеза о поколениях говорит о следующем:
Большинство объектов живут недолго.
Если объект выживает, то он, скорее всего, будет жить вечно.
Этапы mark и sweep занимают меньше времени при большом количестве мусора. То есть маркировка будет происходить быстрее, если анализируемая область небольшая и в ней много мертвых объектов.
Таким образом, алгоритм сборки мусора, использующий поколения, выглядит следующим образом:
Новые объекты создаются в области Eden. Области Survivor (S0, S1) на данный момент пустые.
Когда область Eden заполняется, происходит минорная сборка мусора (Minor GC). Minor GC — это процесс, при котором операции mark и sweep выполняются для young generation (молодого поколения).
После Minor GC живые объекты перемещаются в одну из областей Survivor (например, S0). Мертвые объекты полностью удаляются.
По мере работы приложения пространство Eden заполняется новыми объектами. При очередном Minor GC области young generation и S0 очищаются. На этот раз выжившие объекты перемещаются в область S1, и их возраст увеличивается (отметка о том, что они пережили сборку мусора).
При следующем Minor GC процесс повторяется. Однако на этот раз области Survivor меняются местами. Живые объекты перемещаются в S0 и у них увеличивается возраст. Области Eden и S1 очищаются.
Объекты между областями Survivor копируются определенное количество раз (пока не переживут определенное количество Minor GC) или пока там достаточно места. Затем эти объекты копируются в область Old.
Major GC. При Major GC этапы mark и sweep выполняются для Old Generation. Major GC работает медленнее по сравнению с Minor GC, поскольку старое поколение в основном состоит из живых объектов.
Преимущества использования поколений
Minor GC происходит в меньшей части кучи (
2/3 от кучи). Этап маркировки эффективен, потому что область небольшая и состоит в основном из мертвых объектов.
Недостатки использования поколений
В каждый момент времени одно из пространств Survivor (S0 или S1) пустое и не используется.
Сборка мусора: флаги
В этом разделе приведены некоторые важные флаги, которые можно использовать для настройки процесса сборки мусора.
Флаг
Описание
Первоначальный размер кучи
Максимальный размер куча
Отношение размера Old Generation к Young Generation
Отношение размера Eden к Survivor
Возраст объекта, когда объект перемещается из области Survivor в область Old Generation
Типы сборщиков мусора
Сборщик мусора
Описание
Преимущества
Когда использовать
Флаги для включения
Использует один поток.
Эффективный, т.к. нет накладных расходов на взаимодействие потоков.
Работа с небольшими наборами данных.
Использует несколько потоков.
Многопоточность ускоряет сборку мусора.
В приоритете пиковая производительность.
Допустимы паузы при GC в одну секунду и более.
Работа со средними и большими наборами данных.
Для приложений, работающих на многопроцессорном или многопоточном оборудовании.
Выполняет некоторую тяжелую работу параллельно с работой приложения.
Может использоваться как на небольших системах, так и на больших с большим количеством процессоров и большим количеством памяти.
Когда время отклика важнее пропускной способности.
Паузы GC должны быть меньше одной секунды.
Выполняет всю тяжелую работу параллельно с работой приложения.
В приоритете время отклика.
Сборщики мусора в Java
Инструменты мониторинга GC
Что мониторить?
Частота запуска сборки мусора. Так как GC вызывает "stop the world", поэтому чем время сборки мусора меньше, тем лучше.
Длительность одного цикла сборки мусора.
Как мониторить сборщик мусора?
Для мониторинга можно использовать следующие инструменты:
Для включения логирования событий сборщика мусора добавьте следующие параметры JVM:
Принцип работы 4 сборщиков HotSpot VM (одна из JVM)
- Serial
- Parallel
- Concurent Mark Sweep (CMS)
- Garbage-First (G1)
Serial. Когда нет места в Eden, запускается GC, живые объекты коприруются в S1. Вся область Eden очищается. S1 и S2 меняются местами. При последующих циклах в S1 будут записаны живые объекты как из Eden, так и из S2. После нескольких циклов обмена S1 и S2 или заполнения области S2, обекты, которые живут достаточно долго перемещаются в Old Greneration.
Следует сказать, что не всегда объекты при создании аллоцируюся в Eden. Если объект слишком велик, он сразу идет в Old Generation.
Когда после очередной сборки мусора места нехватает уже в New Generation, то запускается сбор мусора в Old Generation (наряду со сборкой New Generation). В old Generation объекты уплотняются (алгоритм Mark-Sweep-Compact).
Если после полной сборки мусора места нехватает, то вылетает Java.lang.OutOfMemoryError.
Но во время работы VW может запрашивать увеличение памяти и Heap может увеличиваться.
Как правило, Old Generation занимает 2/3 объема Heap.
Эффективоность алгоритма сборки мусора считается по параметру STW (Stop The World) - время, когда все процессы кроме GC останавливаются. Serial в этом смысле не слишком эффективен, т.к. делает свою работу не торопясь, в одном потоке.
Parallel. То же, что и Serial, но использует для работы несколько потоков. Таким образом STW чуть меньше.
Concurent Mark Sweep. Принцип работы с New Generation такой же, как и в случае алгоритмов Serial и Parallel, отличия в том, что данный алгоритм разделяет младшую (New Generation) и старшую (Old Generation) сборку мусора во времени. Причем сбор мусора в Old Generation происходит в отдельном потоке, независимо от младшей сборки. При этом сначала приложение останавливается, сборщик помечает все живые объекты доступные из GC Root (корневых точек) напрямую, затем приложение вновь начинает работу, а сбощик проверяет объекты доступные по ссылкам из этих самых помеченных, и также помечает их как живые. Эта особенность создает так называемые плавающие объекты, которые помечены как живые, но таковыми по факту не являющимися. Но они будут удалены в следующих циклах. Т.е. пропускная способность растет, STW уменьшается, но требутся больше места для хранения плавающих объектов.
В этом алгоритме уплотнения нет. Т.е. область Old Generation дефрагментированна.
Garbage-First. G1 сильно отличается от своих предшественников. Он делит область Heap не физически, а скорее логически на те же области: Eden, Survivor, Old Generation. Причем дефрагментированно. Физически область Heap делится на регионы одинакового размера, каждый из которых может быть Eden, Survivor или Old Generation + область для больших объектов (громадный регион).
Над очисткой регионов Eden работает сразу несколько потоков, объекты переносятся в регионы Survivor или регионы старшего поколения (Tenured). Это знакомый по предыдущим алгоритмам очистки подход. На время очистки работа приложения останавливается. Отличие в том, что очистка производится не по всем регионам Eden, а только по некоторым, которые более всего в ней нуждаются, таким образом регулируется время очистки. Отсюда название алгоритма - в первую очередь мусор.
А с полной сборкой (точнее, здесь она называется смешанной (mixed)) все немного хитроумнее, чем в рассмотренных ранее сборщиках. В G1 существует процесс, называемый циклом пометки (marking cycle), который работает параллельно с основным приложением и составляет список живых объектов. За исключением последнего пункта, этот процесс выглядит уже знакомо для нас:
- Initial mark. Пометка корней (с остановкой основного приложения) с использованием информации, полученной из малых сборок.
- Concurrent marking. Пометка всех живых объектов в куче в нескольких потоках, параллельно с работой основного приложения.
- Remark. Дополнительный поиск не учтенных ранее живых объектов (с остановкой основного приложения).
- Cleanup. Очистка вспомогательных структур учета ссылок на объекты и поиск пустых регионов, которые уже можно использовать для размещения новых объектов. Первая часть этого шага выполняется при остановленном основном приложении.
После окончания цикла пометки G1 переключается на выполнение смешанных сборок. Это значит, что при каждой сборке к набору регионов младшего поколения, подлежащих очистке, добавляется некоторое количество регионов старшего поколения. Количество таких сборок и количество очищаемых регионов старшего поколения выбирается исходя из имеющейся у сборщика статистики о предыдущих сборках таким образом, чтобы не выходить за требуемое время сборки. Как только сборщик очистил достаточно памяти, он переключается обратно в режим малых сборок.
Очередной цикл пометки и, как следствие, очередные смешанные сборки будут запущены тогда, когда заполненность кучи превысит определенный порог.
Опираясь на уже упомянутую статистику о предыдущих сборках, G1 может менять количество регионов, закрепленных за определенным поколением, для оптимизации будущих сборок.
Громадные регионы. С точки зрения JVM объекты которые превышают размер половины региона являются громадными. Особенности:
- никогда не перемещается между регионами
- может удаляться в рамках цикла пометки или полной сборки мусора
- в регионе, занятом громадным объектом, может находится только он сам.
Громадные объекты в силу небольшого размера регионов могут порождать проблемы с точки зрения STW.
G1 выигрывает по времени STW, но расплатой является меньшая пропускная способность (около 90%, ср., например у Paraller ок. 99%) т.е. большие затраты ресурсов процессора.
Bonus
Вопрос: Расскажите почему именно два региона survival и зачем перекладывать объекты между ними?
Вы просто заводите два указателя на начало новой области. Первый указатель (назовем его T) смещается вправо каждый раз, когда в новую область копируется объект, то есть он всегда указывает на первый свободный блок новой области. При этом на том месте старой области, где находился перемещаемый объект, мы делаем пометку о том, что он был перемещен, и там же оставляем его новый адрес. Первым делом перемещаем таким образом все руты из старой области в новую. И вот тут вступает в действие второй указатель (назовем его R). Он тоже начинает смещаться вправо по уже размещенным в новой области объектам. В каждом объекте он ищет ссылки на другие объекты и смотрит на то место в старом регионе, куда они указывают. Если там стоит метка о перемещении и новый адрес, то этот адрес используется для подмены. Если же там лежит объект, то он перемещается в новый регион, на его месте ставится метка и новый адрес, на который так же заменяется ссылка, по которой его нашли, при этом T опять смещается вправо. Как только R догонит T, окажется, что мы собрали все живые объекты в новой области, размещенные компактно, да еще и с корректно обновленными ссылками, а старый регион можем объявить пустым. Все быстро и просто.
Поиск мусора
- Reference counting - у каждого объекта счетчик ссылок. Когда он равен нулю, объект считается мусором. Проблема такого подхода в том, что могут быть цикличные ссылки у объектов друг на друга, в то время как они фактически мусор и не используются программой.
- Tracing - объект считается не мусором, если до него можно добраться с корневых точек (GC Root: локальные переменные и параметры методов, java-потоки, статичные переменные, ссылки из JNI.
Garbage Collection наглядно
В последнее время я работаю с клиентами над вопросами настроек JVM. Смахивает ситуация на то, что далеко не все из разработчиков и администраторов знают о том, как работает garbage collection и о том, как JVM использует память. Поэтому я решил дать вводную в эту тему с наглядным примером. Пост не претендует на то, чтобы покрыть весь объем знаний о garbage collection или настройке JVM (он огромен), ну и, в конце концов, об этом много чего хорошего написано уже в Сети.
Пост посвящён HotSpot JVM – ‘обычной’ JVM от Oracle (раньше Sun), JVM, которую вы скорее всего будете использовать в Windows. В случае Linux это может быть open source JVM. Или JVM может идти в комплекте с другим ПО, например WebLogic, или даже можно использовать Jrockit JVM от Oracle (раньше BEA). Или другие JVM от IBM, Apple и др. Большинство этих «других» JVM работают по похожей на HotSpot схеме, за исключением Jrockit, чье управление памятью отлично от других и который, например, не имеет выделенного Permanent Generation (см. ниже).
Давайте начнём с того, как JVM использует память. В JVM память делится на два сегмента – Heap и Permanent Generation. На диаграмме Permanent Generation обозначено зеленым, остальное – heap.
The Permanent Generation
Permanent generation используется только JVM для хранения необходимых данных, в том числе метаданные о созданных объектах. При каждом создании объекта JVM будет «класть» некоторый набор данных в PG. Соответственно, чем больше вы создаете объектов разных типов, тем больше «жилого пространства» требуется в PG.
Размер PG можно задать двумя параметрами JVM: -XX:PermSize – задаёт минимальный, или изначальный, размер PG, и -XX:MaxPermSize – задаёт максимальный размер. При запуске больших Java-приложений мы часто задаём одинаковые значения для этих параметров, так что PG создаётся сразу с размером «по-максимуму», что может увеличить производительность, так как изменение размера PG – дорогостоящая (трудоёмкая) операция. Определение одинаковых значений для этих двух параметров может избавить JVM от выполнения дополнительных операций, таких как проверки необходимости изменения размера PG и, естественно, непосредственного изменения.
Heap – основной сегмент памяти, где хранятся все ваши объекты. Heap делится на два подсегмента, Old Generation и New Generation. New Generation в свою очередь делится на Eden и два сегмента Survivor.
Размер heap также можно указать параметрами. На диаграмме это Xms (минимум) и -Xmx (максимум). Дополнительные параметры контролируют размеры сегментов heap. Мы позднее посмотрим один из них, остальные за рамкой этого поста.
При создании объекта, когда вы пишете что-то типа byte[] data = new byte[1024], этот объект создаётся в сегменте Eden. Новые объекты создаются в Eden. Кроме собственно данных для нашего массива байт здесь есть ещё ссылка (указатель) на эти данные.
Дальнейшее объяснение упрощено. Когда вы хотите создать новый объект, но места в Eden уже нет, JVM проводит garbage collection, что значит, что JVM ищет в памяти все объекты, которые более не нужны, и избавляется от них.
Garbage collection – это круто! Если вы когда-либо программировали на языках типа C или Objective-C, то вы знаете, что ручное управление памятью – вещь утомительная и порой вызывающая ошибки. Наличие JVM, которая автоматически позаботится о неиспользуемых объектах, делает разработку проще и сокращает время отладки. Если же вы никогда не писали на подобных языках, значит возьмите С и попробуйте написать программу, и ощутите, как ценно то, что предоставляется вашим языком совершенно бесплатно.
Существует множество алгоритмов, которыми может воспользоваться JVM для проведения garbage collection. Можно указать, какие из них будут использоваться JVM с помощью параметров.
Давайте посмотрим на пример. Допустим, у нас есть следующий код:
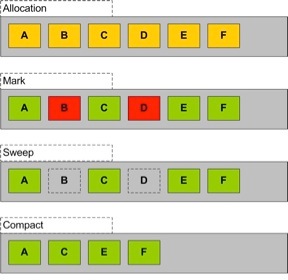
В Eden создаётся («размещается») пять объектов, как показано пятью желтыми квадратиками на диаграмме. После «чего-нибудь» мы освобождаем a,b,c и e, присваивая ссылкам null. Имея в виду, что больше ссылок на них нет, они теперь не нужны, и показаны красным на второй диаграмме. При этом мы всё ещё нуждаемся в String d (показано зелёным).

1) «Mark»: помечаются неиспользуемые объекты (красные).
2) «Sweep»: эти объекты удаляются из памяти. Обратите внимание на пустые слоты на диаграмме.
3) «Compact»: объекты размещаются, занимая свободные слоты, что освобождает пространство на тот случай, если потребуется создать «большой» объект.
Но это всё теория, так что давайте посмотрим, как это работает, на примере. К счастью, JDK имеет визуальный инструмент для наблюдения за JVM в реальном времени, а именно jvisualvm. Лежит он прямо в bin JDK. Воспользуемся ею немного позже, сначала займёмся приложением.
Для разработки, билдов и зависимостей я воспользовался Maven, но вам он не нужен – просто скомпилируйте и запустите приложение, если вам так угодно.
Я выбрал простой JAR (98) и все по умолчанию для остального. Дальше переключился в директорию memoryTool и отредактировал pom.xml (ниже, добавил блок plugin). Это позволило мне запустить приложение прямо из Maven, передав необходимые параметры.
Если вы предпочитаете не использовать Maven, то можете запустить приложение следующей командой:
При этом:
-Xms определяем исходный/минимальный размер heap в 512 мб
-Xmx определяем максимальный размер heap в 512 мб
-XX:NewRatio определяем размер old generation большим в три раза чем размер new generation
-XX:+PrintGCTimeStamps, -XX:+PrintGCDetails и -Xloggc:gc.log JVM печатает дополнительную информацию касаемо garbage collection в файл gc.log
-classpath определяем classpath
com.redstack.App main класс
Ниже – код main-класса. Простая программа, в которой мы создаём объекты и далее выкидываем их, так что понятно, сколько памяти используется и мы можем посмотреть, что происходит с JVM.
Для сборки и выполнения кода используем следующую команду Maven:
mvn package exec:exec
Как только скомпилируете и будете готовы к дальнейшим действиям, запускайте ее и jvisualvm. Если вы не использовали jvisualvm ранее, то нужно установить плагин VisualGC: выберите Plugins в меню Tools, дальше вкладку Available Plugins. Выберите Visual GC и нажмите Install.
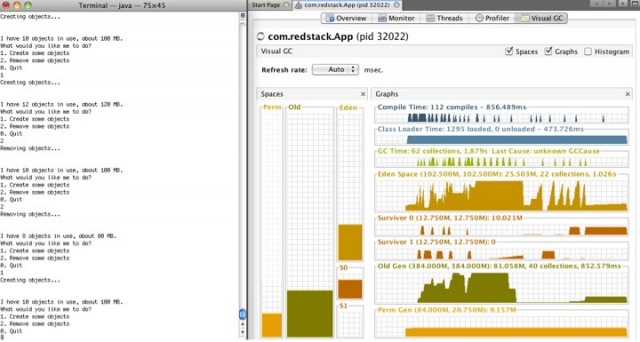
Вы должны увидеть список процессов JVM. Два раза кликните на том, в котором исполняется ваше приложение (в данном примере com.redstack.App) и откройте вкладку Visual GC. Должно появиться что-то типа того, что на скриншоте ниже.
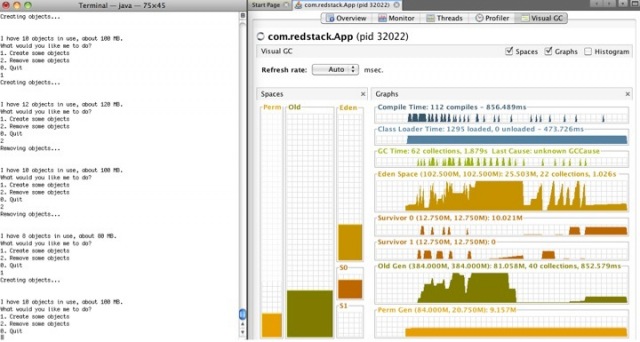
Обратите внимание, что можно визуально наблюдать состояние permanent generation, old generation, eden и сегментов survivor (S0 и S1). Цветные колонки показывают используемую память. Справа находится historical view, которое показывает, когда JVM проводило garbage collections и количество памяти в каждом из сегментов.
В окне приложения начните создавать объекты (опция 1) и наблюдайте, что будет происходить в Visual GC. Обратите внимание на то, что новые объекты всегда создаются в eden. Теперь сделайте пару объектов ненужными (опция 2). Возможно, вы не увидите изменений в Visual GC. Это потому, что JVM не чистит это пространство до тех пор, пока не закончена процедура garbage collection.
Чтобы инициировать garbage collection, создайте ещё объектов, заполнив Eden. Обратите внимание, что произойдет в момент заполнения. Если в Eden много мусора, вы увидите, как объекты из Eden «переезжают» в survivor. Однако, если в Eden мало мусора, вы увидите, как объекты «переезжают» в old generation. Это случается тогда, когда объекты, которые необходимо оставить, больше чем survival.
Пронаблюдайте также за постепенным увеличением Permanent Generation.
Попробуйте заполнить Eden, но не до конца, потом выбросьте почти все объекты, оставьте только 20 мб. Получиться так, что Eden на большую часть заполнен мусором. После этого создайте ещё объектов. На этот раз вы увидите, что объекты из Eden переходят в Survivor.
А теперь давайте посмотрим, что будет, если у нас не хватит памяти. Создавайте объекты до тех пор, пока их не будет на 460 мб. Обратите внимание, что и Eden и Old Generation заполнены практически полностью. Создайте ещё пару объектов. Когда больше не останется памяти, приложение «упадёт» с исключением OutOfMemoryException. Вы уже могли сталкиваться с подобным поведением и думать, почему же это произошло – особенно, если у вас большой объем физической памяти на компьютере и вы удивлялись, как такое вообще могло произойти, что не хватает памяти – теперь вы знаете, почему. Если так случится, что Permanent Generation заполнится (довольно сложно в случае нашего примера добиться этого), у вас будет брошено другое исключение, сообщающее, что PermGen заполнен.
И, наконец, ещё один способ посмотреть, что происходило, это обратиться к логу. Вот немного из моего:
В логе можно увидеть, что происходило в JVM — обратите внимание, что использовался алгоритм Concurrent Mark Sweep Compact Collection algorithm (CMS), есть описание этапов и YG — Young Generation.
Можно воспользоваться этими настройками и в «продакшене». Есть даже инструменты, визуализирующие лог.
Ну, вот и закончилось наше краткое введение в теории и практики JVM garbage collection. Надеюсь, что приложение из примера помогло вам чётко представить, что происходит в JVM когда запущено ваше приложение.
Спасибо Rupesh Ramachandran за то, чему он научил меня относительно настроек JVM и garbage collection.
Краткий конспект реализации Garbage Collector в Java
Garbage Collector (GB) часть JVM, который призван очищать память, выделенную приложению. Он должен:
- найти мусор (неиспользуемые объекты)
- удалить мусор
Есть различные реализации GB.
15 важных вопросов про Spring на техническом собеседовании
1. Что такое Spring?
Ответ: Spring — это фреймворк с открытым исходным кодом для разработки приложений на Java. Основные функции Spring Framework можно использовать при разработке любого приложения Java, также имеются расширения для создания веб-приложений на основе платформы Java EE. Фреймворк Spring нацелен на упрощение использования J2EE в разработке, и улучшение практики программирования путем включения модели на основе POJO (Plain Old Java Object).
2. Какова область действия по умолчанию у bean-компонента в Spring framework?
Ответ: Область действия bean-компонента по умолчанию — Singleton (шаблон проектирования).
3. Что такое Bean wiring?
Ответ: Bean wiring (подключение Bean) — это действие по созданию ассоциаций между компонентами приложения (beans) в контейнере Spring.
4. Что такое Spring Security?
Ответ: Spring Security — это отдельный модуль инфраструктуры Spring, который фокусируется на предоставлении методов аутентификации и авторизации в приложениях Java. Он также устраняет большинство распространенных уязвимостей безопасности, таких как атаки CSRF. Чтобы использовать Spring Security в веб-приложениях, можно начать с простой аннотации: @EnableWebSecurity.
5. Что содержится в определении bean-компонента?
- Как создать bean;
- Подробности жизненного цикла bean;
- Зависимости bean.
6. Что такое Spring Boot?
Ответ: Spring Boot — это проект, который предоставляет предварительно настроенный набор фреймворков для уменьшения шаблонной конфигурации, чтобы вы могли запускать и запускать приложение Spring с минимальным объемом кода.
7. Что такое DispatcherServlet и для чего он используется?
Ответ: DispatcherServlet — это реализация шаблона проектирования Front Controller, который обрабатывает все входящие веб-запросы к приложению Spring MVC. Шаблон Front Controller (шаблон проектирования корпоративного приложения) — это распространенный шаблон в веб-приложениях, задача которого заключается в получении всего запроса и его маршрутизации в различные компоненты приложения для фактической обработки. В Spring MVC DispatcherServlet используется для поиска правильного контроллера для обработки запроса. Это делается с помощью сопоставления обработчиков: например, аннотации @RequestMapping.
8. Нужен ли spring-mvc.jar в пути к классам или он является частью spring-core?
Ответ: Spring-mvc.jar является частью spring-core, что означает, что если вы хотите использовать инфраструктуру Spring MVC в своем проекте Java, то вы должны включить ее spring-mvc.jar в путь к классам вашего приложения. В веб-приложении Java spring-mvc.jar обычно помещается в папку /WEB-INF/lib.
9. Каковы преимущества использования Spring?
- Легкость — Spring относительно легкий, когда дело касается размера и прозрачности. Базовая версия Spring Framework составляет около 2 МБ.
- Инверсия управления (Inversion of control, IOC) — Слабая связанность (loose coupling) достигается в Spring с использованием техники инверсии управления. Объекты предоставляют свои зависимости вместо того, чтобы создавать или искать зависимые объекты.
- Аспектно-ориентированность — Spring поддерживает аспектно-ориентированное программирование и обеспечивает согласованную разработку, отделяя бизнес-логику приложения от системных служб.
- Контейнеры — Spring Container создаёт объекты, связывает их вместе, настраивает и управляет ими от создания до момента удаления.
- MVC Framework — веб-фреймворк Spring — это хорошо спроектированный веб-фреймворк MVC, который обеспечивает альтернативу таким веб-фреймворкам, как Struts или другим излишне спроектированным или менее популярным веб-фреймворкам.
- Управление транзакциями — Spring имеет согласованный интерфейс управления транзакциями, который может масштабироваться до локальной транзакции (например, с использованием одной базы данных) или глобальных транзакций (например, с использованием JTA).
- Обработка исключений — Spring предоставляет удобный API для преобразования исключений, связанных с конкретной технологией (например, вызванных JDBC, Hibernate или JDO) в согласованные, непроверенные исключения.
10. Что такое Spring beans?
Ответ: Spring beans — это экземпляры объектов, которыми управляет Spring Container. Они создаются и подключаются фреймворком и помещаются в «мешок объектов» (контейнер), откуда вы можете их позже извлечь. «Связка» (wiring) — это то, что является внедрением зависимостей. Это означает, что вы можете просто сказать: «Мне нужна эта вещь», и фреймворк будет следовать определенным правилам для получения этого объекта.
11. Какова цель модуля Core Container?
Ответ: Контейнер ядра обеспечивает основные функции платформы Spring. Первичным компонентом основного контейнера является BeanFactory — реализация шаблона Factory. BeanFactory применяет Инверсию управление для разделения конфигурации и зависимостей спецификации приложения от фактического кода приложения.
12. Что такое контекст приложения (Application Context)?
13. Как интегрировать Java Server Faces (JSF) с Spring?
Ответ: JSF и Spring действительно имеют одни и те же функции, особенно в области сервисов Инверсии управления. Объявляя управляемые компоненты JSF в файле конфигурации faces-config.xml, вы позволяете FacesServlet создавать экземпляр этого bean-компонента при запуске. Ваши страницы JSF имеют доступ к этим bean-компонентам и всем их свойствам. JSF и Spring можно интегрировать двумя способами: DelegatingVariableResolver : Spring поставляется с преобразователем переменных JSF, который позволяет вам использовать JSF и Spring вместе. DelegatingVariableResolver сначала делегирует поиск значений интерпретатору по умолчанию базовой реализации JSF, а затем — «бизнес-контексту» Spring WebApplicationContext. Это позволяет легко внедрять зависимости в JSF-управляемые компоненты. FacesContextUtils : настраиваемый VariableResolver хорошо работает при отображении своих свойств на bean-компоненты в faces-config.xml. Но если потребуется захватить bean-компонент, то класс FacesContextUtils это упрощает. Он похож на WebApplicationContextUtils, за исключением того, что принимает параметр FacesContext, а не параметр ServletContext.
14. Что такое Spring MVC framework?
Ответ: Инфраструктура Spring Web MVC предоставляет архитектуру model-view-controller и готовые компоненты, которые можно использовать для разработки гибких и слабосвязанных веб-приложений. Шаблон MVC приводит к разделению различных аспектов приложения (логика ввода, бизнес-логика и логика пользовательского интерфейса), обеспечивая при этом слабую связь между этими элементами.
15. Как происходит обработка событий в Spring?
Ответ: Обработка в ApplicationContext обеспечивается через ApplicationEvent класса и ApplicationListener интерфейса. То есть если bean-компонент реализует ApplicationListener, то каждый раз, когда ApplicationEvent публикуется в ApplicationContext, этот bean-компонент регистрируется. Спасибо за чтение и удачи в вашем техническом собеседовании!
Читайте также: